Cross Datacenter Replication (XDR)
This page describes Aerospike's Cross Datacenter Replication (XDR) feature which asynchronously replicates cluster changes over higher-latency links, typically WANs.
Overview
XDR synchronizes data between geographically distributed Aerospike clusters, ensuring data consistency, redundancy, and high availability. This protects your data against datacenter and cloud service provider region failure, and also lets you to create high-performance geo-distributed, mission-critical applications. Such deployments provide low latency reads and writes at each independent cluster, distributing data in a way that is meaningful to each region while complying with data locality regulations.
Configuring Aerospike XDR
See Static XDR configuration or
:::note Aerospike recommends configuring XDR dynamically so that all nodes start shipping at the same time. For dynamic configuration instructions. :::
Terminology
- Shipping refers to sending data from one datacenter to another.
- A cluster from which records are shipped is a source cluster.
- A cluster to which records are shipped is a destination cluster.
Version changes
- XDR does not impose any version requirement across datacenters.
- Starting with Database 7.2,
ship-versions-policycontrols how XDR ships versions of modified records when facing lag between the source cluster and a destination. ship-versions-intervalspecifies a time window in seconds within which XDR is allowed to skip versions.- Starting with Database 5.7, the XDR subsystem always accepts dynamic configuration commands because it is always initialized even if XDR is not configured statically.
- Prior to Database 5.7, the XDR subsystem must be configured statically with at least one datacenter. For information, see Static XDR configuration.
Architecture
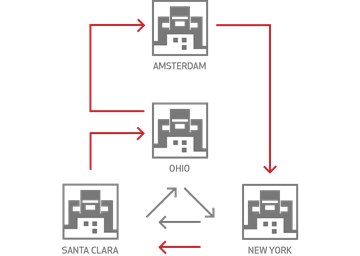
The following diagram shows how XDR replicates data across multiple datacenters worldwide. XDR replicates data between source and destination clusters as follows:
Unidirectionally: The data in a specified source cluster is replicated to a specified destination cluster. Although the replicated data in the destination cluster could be used for the routine serving of data, it is intended principally as a backup, to support disaster recovery.
Bidirectionally: The data in a specified source cluster is replicated to a specified destination cluster; and the data in the destination cluster is, in turn, replicated back to the source cluster. This allows both clusters to be used for the serving of data, which may provide faster data-access for users and applications in remote geographies.
Use cases for XDR
XDR serves various purposes, making it a valuable tool for businesses across different industries.
Disaster recovery: XDR ensures that data is replicated to a remote datacenter, providing disaster recovery capabilities. In case of a datacenter failure, the backup datacenter can take over seamlessly.
Global distribution: For businesses with a global presence, XDR can replicate data across multiple datacenters worldwide, reducing latency and ensuring local access to data for customers.
Load balancing: XDR can distribute read requests across multiple datacenters, balancing the load and improving read performance.
Data migration: When migrating from one datacenter to another or transitioning to a new cluster, XDR facilitates a smooth data migration process.
Capabilities of XDR
XDR can aid in handling many replication scenarios. It allows flexibility in configuring replication to meet your specific use case. Some of these capabilities include:
Static and dynamic configuration: XDR can be configured statically in the configuration file or dynamically via the asadm or asinfo tools.
Configurable replication topology: Various replication topologies supported like active-passive, active-active, star, linear chain and any combination of these (hybrid).
Flexibility in replication granularity: You can selectively replicate certain namespaces, sets or bins and this replication granularity can be defined differently for each datacenter.
Replicating record deletes: XDR can replicate deletes from clients, and even from record expiration or eviction.
Cluster heterogeneity: Clusters can be different sizes, run on different types of machines, operating system, and storage media.
Failure handling: XDR provides graceful handling of node and network failures.
Compression: Compression can be enabled to save network bandwidth.
Rewinding replication: You can rewind or rerun replication of records a specific number of seconds or restart replication completely.
Limitations of XDR
While XDR is a powerful feature, it may not be suitable for all scenarios. Here are some limitations and use cases where XDR might not be the best choice:
Network Latency: XDR relies on network connectivity between datacenters. High network latency can impact the synchronization speed and performance.
Complexity: Setting up and managing XDR configurations, especially in active-active or fan-out scenarios, can be complex and require careful planning.
Consistency guarantees in mesh topology: In a mesh, or active-active, topology, writes which happen in separate datacenters must be replicated to each other. Although XDR's bin convergence feature can help with write conflicts in such a setup, it cannot ensure eventual consistency and intermediate updates can be lost.
XDR topologies
XDR configurable topologies include the following:
XDR configuration examples for implementing the topologies are in Example configuration parameters for XDR topologies.
Active-passive topology
In an active-passive topology, clients write to a single cluster. Consider two clusters, A and B. Clients write only to cluster A. The other cluster, cluster B, is a stand-by cluster that can be used for reads. Client writes are shipped from cluster A to cluster B. However, client writes to cluster B are not shipped to cluster A. Additionally, XDR offers a way to completely disable client writes to cluster B, instead of just not shipping them.
A common use case for active-passive is to offload performance-intensive analysis of data from a main cluster to an analysis cluster.
Starting with Database 7.2, active-passive XDR deployments can maintain strong consistency guarantees for version ordering, without the use of bin convergence.
Active-active (mesh topology)
In active-active mesh topology, clients can write to different clusters. When writes happen to one cluster, they are forwarded to the other. In a typical case, client writes to a record are strongly associated with one of the two clusters, and the other cluster acts as a hot backup.
If the same record can be simultaneously written to two clusters, an active-active topology generally not suitable. See Bin convergence in mesh topology for details.
An example for the active-active topology is a company with users spread across a wide geographical area, such as North America. Traffic could then be divided between the West and East Coast datacenters. While a West Coast user can write to the East Coast datacenter, it is unlikely that writes from this user will occur simultaneously in both datacenters.
Bin convergence in mesh topology
Bin convergence can help with write conflicts in mesh/active-active topologies. This feature ensures that the data is eventually the same in all the datacenters at the end of replication even if there are simultaneous updates to the same record in multiple datacenters. To achieve this, extra information about each bin's last-update-time (LUT) is stored and shipped to the destination clusters. A bin with a higher LUT is allowed to overwrite a bin with lower LUT. An XDR write operation succeeds when at least one bin update succeeds, and returns the same message for both full and partial successes.
One important thing to note is that this feature will ensure only convergence and not eventual consistency. Some of the intermediate updates may be lost. This feature will be able to cater to the use cases which care more about the final state rather than the intermediate states. For example, if the application is tracking the last-known location of a device, maybe by multiple trackers, this feature is a good fit.
If the intermediate updates are important, this feature is not the right choice. For example, in a digital wallet application, all the intermediate updates are very important. One should consider multi-site clustering which will not allow the conflicts to happen in the first place.
For more information, see "Bin Convergence".
Star topology
Star topology allows one datacenter to simultaneously replicate data to multiple remote datacenter destinations. To enable XDR to ship data to multiple destination clusters, specify multiple destination clusters in the XDR configuration. Star replication topology is most commonly used when data is centrally published and replicated in multiple locations for low-latency read access from local systems.
Linear chain topology
Aerospike supports the linear chain network topology, sometimes called a "linear daisy chain". In a linear chain topology, one datacenter ships to another, which ships to another, which ships to another, and so on, until reaching a final datacenter that does not ship to any other.
If you are using a chain topology, be sure not to form a ring daisy chain. Make sure that the chain is linear: it ends at a single node and does not loop back to the start or any other link of the chain.
Hybrid topologies
Aerospike supports many hybrid topology combinations.
Local destination and availability zones
While the most common XDR deployment has local and remote clusters in different datacenters, sometimes the "remote" cluster might be in the same datacenter. Common reasons for this are:
- The local destination cluster is only for data analysis. Configure the local destination cluster for passive mode and run all analysis jobs on that cluster. This isolates the local cluster from the workload and ensures availability.
- Multiple availability zone datacenters, such as with Amazon EC2, can ensure that if there is a large-scale problem with one availability zone, the other is up. Administrators can configure clusters in multiple availability zones in a datacenter. For best performance, all nodes in a cluster must belong to the same availability zone.
Cluster heterogeneity and redundancy
Clusters can be different sizes, run on different types of machines, operating system, and storage media. The XDR failure handling capability allows the source cluster to change size dynamically. It also works when multiple-destination datacenters frequently go on and off line.
There is no one-to-one correspondence between nodes of the local cluster and nodes of the remote cluster. Even if both have the same number of nodes, partitions can be distributed differently across nodes. Every master node of the local cluster can write to any remote cluster node. Just like any other client, XDR writes a record to the remote master node for that particular record.
Configuration best practices
Aerospike recommends configuring XDR dynamically so that all nodes start shipping at the same time. For instructions, see XDR dynamic configuration.
For details about how to do a static configuration of XDR, including sample parameters for the features discussed in this overview, see Static XDR configuration.
XDR Proxy
Aerospike XDR Proxy addresses cross-datacenter situations where the source Aerospike cluster cannot get direct access to the nodes of the remote cluster. This includes most containerized environments, such as those launched using Kubernetes, but could be extended to cloud-based deployments in general, where a VPC/VPN containing both source and destination Aerospike clusters cannot be established. The XDR Proxy can be used to expose the destination Aerospike cluster as a service to the source cluster.
See XDR Proxy for more information.
Replication granularity: namespace, set, or bin
Replication is defined per datacenter. You can configure the granularity of the data to be shipped:
- A single namespace or multiple namespaces.
- All sets or only specific record sets.
- All bins or a subset of bins.
Shipping namespaces
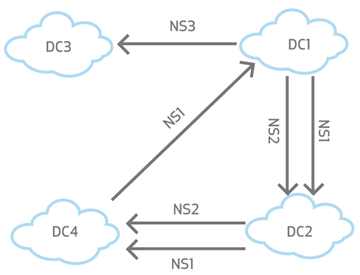
Aerospike nodes can have multiple namespaces. You can configure specific namespaces to ship to specific remote clusters. In the following diagram, DC1 ships namespaces NS1 and NS2 to DC2, and shipping namespace NS3 to DC3. Use this flexibility to configure different replication rules for different data.
Shipping specific sets
You can configure XDR to ship only specific sets to a datacenter. The combination of namespace and set determines whether to ship a record. Use sets if not all data in a namespace in a local cluster needs to be replicated in other clusters.
Shipping specific bins
You can configure XDR to ship only specific bins and ignore others. By default, all bins are shipped. Configure bin-policy to change which bins are shipped.
Shipping record deletes
In addition, you can configure XDR to ship record deletions. Such deletes can be either those from a client or those that result from expiration or eviction by the namespace supervisor (NSUP).
- By default, record deletes by clients are shipped. Durable deletes are always shipped.
- By default, record deletes from expiration or eviction by NSUP are not shipped.
LUT and LST
- The Aerospike service keeps track of a record's digest and Last Update Time (LUT) based on write transactions.
- The XDR component of the Aerospike service tracks the Last Ship Time (LST) of a record's partition. Any record in a partition whose Last Update Time (LUT) is greater than the partition's LST is a candidate for shipping. The LST is persisted at namespace level.
- The XDR component of the Aerospike service compares the record's LUT to the record's partition LST. If the LUT is greater than the LST, the record is shipped to the defined remote nodes' corresponding namespaces and partitions in the defined remote datacenter destination.
- The replica writes are also tracked in case they are needed to recover from a failed master node.
- If XDR is configured to ship user-initiated deletes or deletes based on expiration or eviction, these write transactions are also shipped to the remote datacenter destination.
- The record's partition's LST is updated.
- The process repeats.
Failure handling
XDR manages the following failures:
- Local node failure.
- Remote link failure.
- Combinations of the above.
In addition to cluster node failures, XDR handles failures of a network link or of a remote cluster.
- First, replication by way of the failed network link, or to the failed remote cluster, is suspended.
- After the issue has been resolved and things are back to normal, XDR resumes for the previously unavailable remote cluster and catches up.
- Replication by way of other functioning links to other functioning remote clusters remains unaffected at all times.
Local node failure
XDR offers the same redundancy as a single Aerospike cluster. The master for any partition is responsible for replicating writes for that partition. When the master fails and a replica is promoted to master, the new master takes over where the failed master left off.
Communications failure
If the connection between the local and the remote cluster drops, each master node records the point in time when the link went down and shipping is suspended for the affected remote datacenter. When the link becomes available again, shipping resumes in two ways:
- New client writes are shipped just as they were before the link failure.
- Client writes that happened during the link failure, that is, client writes that were held back while shipping was suspended for the affected remote cluster, are shipped.
When XDR is configured with star topology, a cluster can simultaneously ship to multiple datacenters. If one or more datacenter links drop, XDR continues to ship to the remaining available datacenters.
XDR can also handle more complex scenarios, such as local node failures combined with remote link failures.
Combination failure
XDR manages combination failures such as local node down with a remote link failure, link failure when XDR is shipping historical data.