According to the McKinsey Global Survey on artificial intelligence (AI), companies plan to invest even more in AI in response to the COVID-19 pandemic and its acceleration of all things digital. Data Science teams are utilizing data sets on a never seen before magnitude and scale, pursuing new use cases, and responding to new challenges created by the new normal.
As I had mentioned in my previous blog, the more time the data science teams spend on model training, the less business value they add because no value is created until that model is deployed in production. Apache Spark 3.0 and Aerospike can help you realize your AI/ML strategies at scale, reliably, and cost-effectively. Hence, we are very pleased to announce that Aerospike Connect for Spark now supports Apache Spark 3.0.
Why should you be excited about Apache Spark 3.0?
There are several reasons for it, but let’s look at it through the lens of a data engineer:
Deploy Spark on Kubernetes

Spark on Kubernetes support is now generally available. It offers several critical features for the Spark cluster such as autoscaling via Horizontal Pod Autoscaler, automated rollouts and rollbacks, load balancing, secrets and config management, RBAC and namespaces for security, etc. The Kubernetes Operator for Apache Spark simplifies the deployment of Spark applications on Kubernetes.
When used in conjunction with our recently announced Aerospike Kubernetes Operator, you can easily deploy a Spark 3.0 based data pipeline in on-prem, hybrid cloud, or multi-cloud environment. The Aerospike Kubernetes operator enables organizations to run Aerospike as a stateful database with cloud-native applications on a Kubernetes platform.
Build a single low latency and high-throughput pipeline, from data ingest to data preparation to model training on a GPU-powered cluster.
Spark 3.0 can now schedule AI/ML applications on Spark clusters with GPUs. This will essentially allow you to unify your CPU based data platform that is used for data preparation via ETL and the largely GPU based AI/ML platform into a single unified data infrastructure to accelerate your AI/ML applications. However, you need to be mindful that no matter how optimized your algorithms are or the fact that you use GPUs, data loads are IO constrained by the choice of your database. Aerospike is a highly scalable NoSQL database and its hybrid memory architecture makes it an ideal data source for the below technology stack developed by NVIDIA.
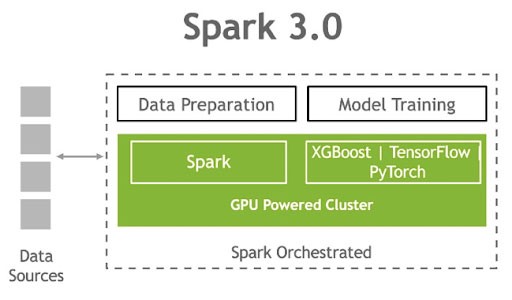
Figure 1 Single pipeline, from data ingest to data preparation to model training on a GPU-powered cluster. (Source: NVIDIA)
Speed up your queries with new query enhancements
Spark 3.0 is packed with features to provide a performance boost to your queries, but the one that grabbed our attention is Adaptive Query Execution (AQE). This feature helps when statistics on the data source do not exist or are not accurate. With AQE, Spark can now examine data (e.g. size, etc.) at runtime once it has been loaded, eliminating the need for static statistics. It has also made SQL query optimization more resilient to unpredictable data set changes, e.g., sudden increase or decrease in data size, frequent and random data skew, etc. There’s no need to “know” your data in advance anymore. AQE is disabled by default but can be easily enabled via configuration. This feature can potentially speed up ETL jobs that involve joining Aerospike data with other data sources without any need to generate statistics for the Aerospike data.
So, what’s new in the Aerospike Connect for Spark?
We have added the following key features to power your Spark 3.0 based workloads:
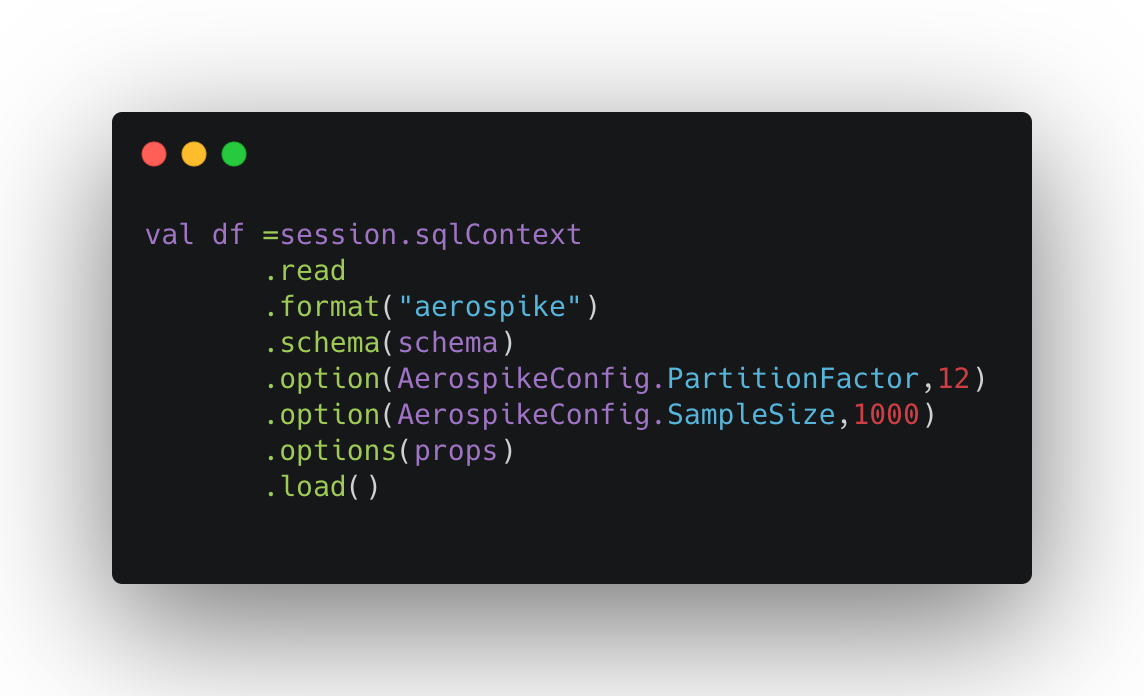
Data Sampling at scale Our upcoming release will have the capability to help data engineers with sampling of data stored in Aerospike, rather than reading the whole Aerospike namespace when the use case just demands exploring a small subset of data. This feature is configurable and when used in conjunction with the connector’s partition scanning capability can enable you to massively parallelize the sampling from the database. Further, if you would like to do random sampling, you can use the Spark DataFrame sample() function after you sample records from the database. However, the whole namespace will be read if you just use the Spark DataFrame sample () without bringing to bear the connector’s sampling capability. The below code snippet shows how you can easily use the sampling property to sample 1000 records from a million record Aerospike set. Further optimization includes limiting the database scans which can significantly reduce the load on the server.
Support for set indexes and quotas features of the Aerospike Database 5.6
Set Indexes The set indexes feature solidifies the notion of 1:1 mapping between a Spark DataFrame i.e. table and an Aerospike set, and vice-versa. It allows Spark queries to efficiently scan a set, rather than scanning the whole namespace as previously done. This can speed up the queries when you are querying a tiny set in a giant namespace and is extremely memory efficient. Another advantage is that no code changes are needed to your existing Spark application to use this feature.
Quotas You can choose to use this feature to rate limit Spark users so that no single user can hog your Aerospike cluster resources with a long-running and IO intensive Spark job. The rate-limiting will come with a required scan policy, hence each database scan essentially self-limits. If you exceed the limit, the scan gets rejected upfront.
Pushdown predicates with previously unsupported operators to the database to speed up queries
In an upcoming release, we plan to add the capability to push down predicates with the MOD operator via Spark’s .option() function to the connector. The connector can then update Spark’s optimized physical plan to push down predicates to Aerospike using Aerospike expressions, rather than running full table scans for each query. We plan to extend this to support a large section of Aerospike expressions in the future to limit data movement between Aerospike and the Spark clusters, and consequently speed up queries.
Support for highly performance Spark Data Source V2 API
We added support for the highly performant Spark Data Source V2 API to the Spark 2.4.x connector earlier this year and have extended it to the Spark 3.0 connector as well. Based on our internal performance testing, with a V2 compliant connector, we have seen up to 60% reduction in the average query latency versus the V1 compliant connector across various types of query loads.
Finally, what can you do with it?
Here are two select case studies:
A big Ad-tech company is currently trialing the sampling feature for sampling (small %) data across globally distributed Aerospike clusters and aggregating results to verify their Ad coverage. It has helped them to measure the impact of existing coverage gaps and enabled them to use that information to improve their targeting. Given the massive volume of data in their clusters, moving 100% of the data from Aerospike clusters to the Spark cluster was neither technically feasible nor financially viable.
A big telco was using the connector to read large amounts of data in a massively parallel manner from Aerospike into a Spark DataFrame. Once the data was loaded into a DataFrame, they were using the SparkGraph module of Spark 3.0 to detect data sensitivity by identifying relationships between different fields of the data set. This helped them to successfully comply with various regulatory requirements.
What’s next?
If you have an AI/ML initiative that you would like to deploy at scale with Apache Spark 3.0, look no further. Build your Spark 3.0 based AI/ML pipeline by downloading Aerospike Database Enterprise Edition and the Aerospike Connect for Spark, and follow our Jupyter notebook based SparkML tutorial. In the near future, we plan to validate our Spark connector with the RAPIDS Accelerator for Apache Spark so that you can feed Aerospike data in a massively parallel manner directly to Deep Learning models running on GPUs. Stay tuned for more details!