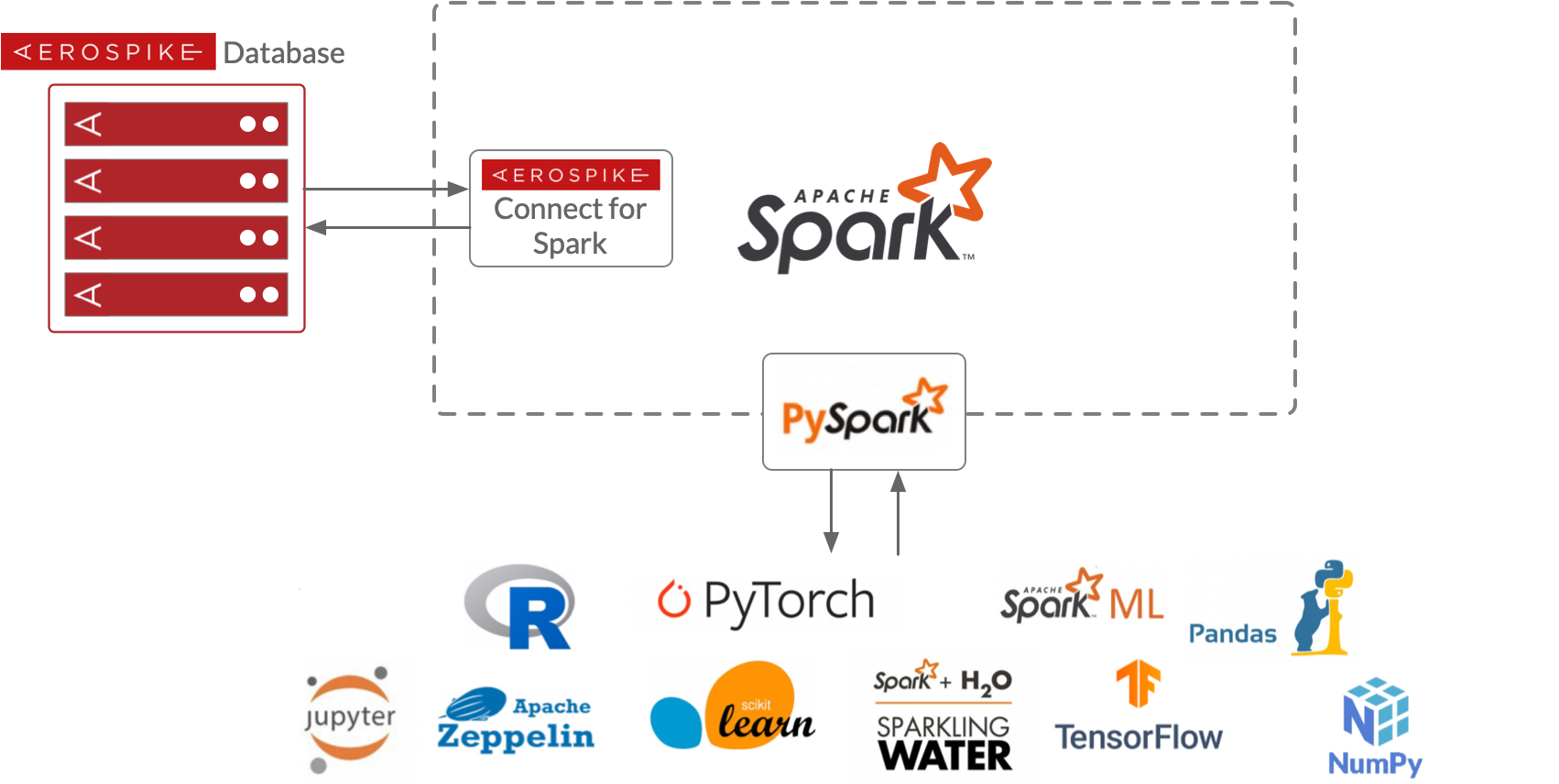
Aerospike Connect for Spark
Aerospike Connect for Spark loads data from Aerospike into a Spark streaming or batch DataFrame in a massively parallel manner, so that you can process the data by using Spark APIs, which are supported in multiple languages, such as Java, Scala, and Python. A Spark connector can be easily added as a JAR to a Spark application, which can then be deployed in a Kubernetes or non-Kubernetes environment, either in the cloud or on bare-metal.
Aerospike is a NoSQL DB and is schemaless. Further, it offers a rich data model which is a little different from Spark SQL. An Aerospike set, unlike a Spark DataFrame, is not required to have the same bins (which correspond to columns in DataFrames) across all of its records. The Spark connector reconciles those differences and offers a SQL experience in both DataFrame and Spark SQL syntaxes that Spark users are familiar with, while leveraging the gamut of Aerospike database’s benefits, which include strong consistency and hybrid-memory architecture.
The Spark connector allows your applications to parallelize work on a massive scale by leveraging up to 32,768 Spark partitions (configured by setting aerospike.partition.factor) to read data from an Aerospike namespace storing up to 32 billion records per namespace per node across 4096 partitions. For example, if you had a 256-node Aerospike cluster, which is the maximum allowed, you would be able to store a whopping 140 trillion records.
The Spark connector scans Aerospike database partitions in parallel; such support, when combined with Spark workers, enables Spark to rapidly process large volumes of Aerospike data. This can help significantly reduce the execution time of a Spark job. For example, you can use Spark APIs in your ETL applications to read from and write to Aerospike by using the connector. Then, when an ETL application is submitted as a Spark job, Spark distributes the job across your cluster's worker nodes to read from or write to Aerospike in a massively parallel manner.
Key features
Enables Python users to use PySpark to load Aerospike data into a Spark DataFrame and bring to bear various open-source Python libraries, such as Pandas and NumPy; AI/ML frameworks, such as Scikit-learn, PyTorch, TensorFlow, SparkML; and visualization libraries, such as Matplotlib.
Enables users to write query results, predictions, enriched and transformed data, and more from DataFrames to Aerospike.
Enables streaming use cases that need millisecond latency, such as fraud detection, via Spark Structured Streaming read and write APIs.
Supports Jupyter Notebook to help you to quickly progress from your POC to production.
Supports Aerospike's rich data model, which includes collection data types such as maps and lists, allowing you to write compelling Spark applications.
Supports Aerospike's secondary index.
Supports
aerolookupfor Python, Scala, and Java for looking up records in the database corresponding to a set of keys in a Spark DataFrame.aerolookupreturns faster results than using inner joins in Spark for the same purpose.Enables secure connections between Aerospike and Spark clusters with TLS and LDAP.
Supports schema inference to allow you to query data stored in Aerospike when the schema is not known a priori. You can also provide the schema, if it's available. The connector also supports flexible schemas.
Allows you to pushdown Aerospike Expressions to the database directly from Spark APIs to limit the data movement between the Aerospike and the Spark clusters and consequently accelerate queries.
Uses
You can use the Spark connector to load data from an Aerospike database into a Spark cluster. From there, you can use the data for interactive notebooks, machine-learning, AI, predictive data analytics, and scientific computing. Through the connector, you can also write changes to data back into your Aerospike database.
Limitations
Using the Spark Structured Streaming readStream() API with Aerospike requires that you use Kafka as a streaming source for Spark Streaming, along with the Aerospike Connect for Kafka. Kafka is used to reconcile the difference in models between Aerospike XDR (push-based) and Spark (pull-based).
If you are planning to use SQL syntax, Spark SQL DDL statements are not supported because the Spark connector does not use the Spark Catalog. DML statements such as “SELECT” and “INSERT INTO” that need I/O interaction with the database are supported. However, connector versions 2.7+ and 3.0+ use the Spark DataSource V2 API, which does not support “INSERT INTO” for a temp view. Use DataFrame syntax for equivalent functionality for unsupported statements in the SQL syntax.
We recommend that you provide schema for queries that involve complex types such as lists, maps, and mixed types. Using schema inference for complex types, especially when they are deeply nested, might cause unexpected issues.
When you query with
__digest, you might get the user keys that are stored in the database, as NULLs in the result set. It is a known issue. Use the user keys returned by the__digestquery with caution.