

Aerospike is pleased to announce the availability of our 4.8 release. Its major features are discussed below.
Data in Persistent Memory
Aerospike Enterprise Edition 4.8 now supports storing record data in Intel® Optane™ DC Persistent Memory (PMEM). Optane is a new storage technology that represents a new level in the traditional storage hierarchy pyramid that combines byte-addressability and access times similar to DRAM with the persistence and density of Flash NVMe storage.
In an earlier release, Aerospike became the first commercially available open database to support PMEM by allowing the Primary Index to be placed there. The 4.8 release extends PMEM support to the record data itself. Combined, they offer unparalleled performance while retaining both persistence and fast reboot capabilities.
Although storing both indexes and data in PMEM is an obvious choice, their advantages differ somewhat so it is better to match their characteristics (along with NVMe Flash) to data model of the client application. The full matrix of possibilities for placing the Primary Index and data are shown in Table 1. Not all possibilities make sense: the ones that match some use cases are highlighted in green, and will be elaborated upon below.
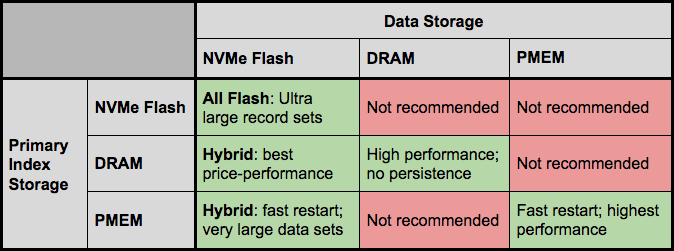
Starting from the lower right, there are few downsides to using an all-PMEM configuration. Performance is on par with DRAM, but at a lower cost per bit, and without giving up either persistence or fast recovery from reboots (minutes rather than hours). The higher performance can be put to use in many ways, including more transactions per node (fewer upgrades as traffic grows), or doing more computation per transaction (e.g. richer models for AdTech and fraud detection use cases).
Another possibility is enabling Strong Consistency (SC) mode or durable writes in applications where the need for real-time performance might have ruled this out in the past. Even when SC is not an absolute requirement, being able to deploy it cost-effectively may be worthwhile for the operational efficiencies gained.
The ultimate limiting factor for data in PMEM is the amount that the processor will support. The current generation of Xeon Scalable 2 (Cascade Lake) processors supports a maximum of 3 TiB per socket: even with multi-socket systems very large databases can’t be accommodated. There may also be economic considerations because the Xeon processors with support for large address spaces carry a premium.
For extremely large databases, dedicating all the PMEM to the Primary index is a better choice. It is more cost effective than DRAM, scales to a larger data set and retains the advantage for fast reboots afforded by not having to rebuild the indexes. Even at petabyte scale, performance is excellent thanks to the many optimizations Aerospike has made to block mode Flash storage.
Compressed Request/Response API Policy
Aerospike already supports in-database compression of records at rest. This is an optional feature that can be enabled with a choice of several compression algorithms representing different tradeoffs between compression ratio, CPU usage and input data characteristics.
Aerospike 4.8 extends compression orthogonally to the transmission of data between client and servers. This is implemented by adding a policy bit to transactional APIs that controls compression over the wire. When set, both the client request and the server response are compressed.
The application has complete control over which transactions are compressed, and this is independent of whether the data at rest is compressed or not. However, the application does not have the ability to specify the compression algorithm used: this is controlled by Aerospike, and was chosen to perform reasonably (balanced CPU usage and compression ratio) across a wide variety of input data.
Many applications are network bandwidth limited and in these cases the benefit of increased throughput facilitated by compressed data outweighs the additional CPU expended. There are related use cases that frequently arise in cloud deployments. If a large volume of data has its source or sink outside the cloud, ingress/egress charges can be mitigated by reducing the volume of traffic through the use of compression.
Regardless of data locality, cloud policies to share resources fairly (or limit “noisy neighbor” problems) may place a cap on the number of packets per second allowed to an instance. Here too, compressing wire traffic can allow more data to pass between client and server for a given packet rate.
Keep reading

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works

Apr 28, 2026
Aerospike Voyager: From first connection to production code
Apr 28, 2026
Introducing the Aerospike Java and Python SDKs: A generational upgrade to building on Aerospike