
Aerospike is pleased to announce the availability of Aerospike Server 4.9. This release is developer-centric, offering new functionality, enhancements to existing features, and some changes in defaults better aligned with the most common use cases. The highlight is the introduction of operations on probabilistic data (HyperLogLog), which will be described in detail below along with the other major features (refer to the Release Notes for a comprehensive summary of all changes).
HyperLogLog
HLL Background
Aerospike Server 4.9 introduces the HyperLogLog (HLL) probabilistic data type and a number of new operations that can be performed on HLL bin data. These operations provide an efficient solution to a class of problems that frequently arise when working with large sets of data in application domains such as AdTech and fraud detection. Understanding the utility of HyperLogLog requires a bit of explanation.
Probabilistic algorithms compute an estimate of a deterministic metric, rather than the exact value. To be useful, the estimate must be reasonably accurate (colloquially, within a couple of percentage points) and have low variance. In exchange for approximate accuracy, probabilistic algorithms require less computing and storage resources than the corresponding deterministic algorithms.
The operations performed on HLL data are based on the distinct-counting problem (DCP). That is, given a set of elements (technically a multiset, meaning duplicates are allowed), how many unique elements are there in the set? For example, the set {b, a, a, b, c, a} has cardinality of 6 but the number of distinct elements is 3. Brute force solutions to DCP require storage (and computation) at least proportional to the number of distinct elements, or worse, to the range of element values for a histogram array approach. This becomes intractable as the number of elements reaches into the millions or billions.
The first probabilistic solution to the distinct-counting problem was the 1985 Flajolet-Martin algorithm. It has been superseded by the 2007 HyperLogLog algorithm implemented in 4.9, but is useful for demonstrating the principles at work in the following example.Each element of the set is hashed, resulting in a pseudo-random but uniformly distributed pattern of bits. A cryptographic hash is used to ensure collisions (different elements hashing to the same value) are rare. The number of trailing zero bits is computed for each hash, and the longest such sequence across all elements (call it n) is extracted.Treating each bit position as a coin toss, the probability of a sequence of n zero bits occurring is 2-n, meaning that there are approximately 2n distinct elements in the set. Note that repeated occurrences of an element in the set don’t change the result, because the hash is the same.
HLL Operations
The new HyperLogLog data type was created in 4.9 to hold the state necessary to perform HLL operations on sets of data. Although an HLL instance can grow to several kilobytes (see documentation for computing this) this is orders of magnitude smaller than brute-force storage requirements. The following operations are supported:
The cardinality of the number of distinct elements in a set
The cardinality of the number of distinct elements in the intersection of two or more sets
The cardinality of the number of distinct elements in the union of two or more sets
A measure of the similarity between sets
The similarity measure is based on the probabilistic HyperMinHash algorithm, which in turn gives an estimate of the Jaccard Similarity coefficient between two sets, which is defined as the ratio of distinct elements in the intersection of the sets to distinct elements in the union of the sets:
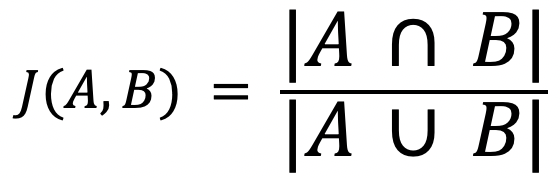
This yields a fraction between 0.0 (if the sets are disjoint) and 1.0 (if they are identical), unless both sets are empty, in which case the result is undefined (0➗0). HLL operations are streaming, meaning that the probabilistic estimates can be updated by adding new elements to a set without recomputing the desired operation from scratch.
Scan by Partition (Correct Scans)
Prior to 4.9, basic scans were only performed in parallel at the namespace level, and records within a namespace were scanned serially. Aerospike supports a maximum of 32 namespaces, so this limitation was a major performance limitation.
Starting with 4.9, new API calls have been added to allow partitions to be scanned in parallel. To recall, Aerospike records are distributed evenly across 4096 partitions, based on bits extracted from the RIPEMD160 digest of the record key, so this represents three orders of magnitude increase in potential parallelism. Aerospike Connect for Spark has been updated to take advantage of this feature, resulting in a large improvement in performance.
The new API also supports per-partition cursors. This allows partitions to be scanned in disjoint chunks: for example a partition with 100 records can be scanned in 5 groups of 20. Cursors are based on record digests, and work in conjunction with partition filters. Records within a partition are scanned in the same order.
A side-effect of the scan by partition implementation is that scans are always accurate, even if they occur during migrations. This allows a backup to proceed unimpeded if a node restarts while the backup script is running.
Changed Eviction/Expiration Defaults
Evictions & expirations are optional mechanisms in Aerospike to automatically purge records, either because they have expired (have an expiration date set), or in response to memory pressure (evictions). This mechanism is essential in many applications (e.g. in AdTech), but highly undesirable in others (e.g. systems-of-record). In response to application requirements growing more diverse, and to better align default behavior to the most common use cases, Aerospike has changed the following defaults to zero:
high-water-disk-pct
(was 50)
high-water-memory-pct
(was 60)
mounts-high-water-pct
(was 80)
nsup-period
(was 120)
The net effect of these changes is that eviction is inactive by default. Applications requiring eviction that were depending on default configuration parameter settings must now explicitly configure these values.A final consideration applies to applications that wish to write records with TTLs. If nsup-period is zero, this would normally return an error (because the namespace supervisor is inactive). To allow this use case, set the new configuration parameter allow-ttl-without-nsup.N.B. It is advisable to read the 4.9 release notes carefully to fully understand the impact of these changes and adjust your configuration if needed. The server takes great care to avoid accidentally expiring records, and will refuse to start if it detects inconsistent settings.
Sampling Max Records Option
The new max-records option allows the number of records returned from a basic scan to be specified directly. This is an alternative to the existing percent sampling option, which specifies the number of records to return as a percentage of the total. In either case, the scan will never return more than the max-records value, and will likely return the exact number, though it could possibly return fewer records if the max-records value is close to the number of records in the database. Going forward, the percent option is deprecated in favor of max-records, though both sampling options are still supported for the time being.
Request/Response Compression Level
Aerospike Server 4.8 introduced the ability for applications to selectively specify compression of requests and responses through a policy bit on transactional APIs. Neither the compression algorithm nor level of compression performed are user selectable. After an analysis of a representative set of applications, the compression level has been reduced. Although compression efficiency and performance is data-dependent, this change is expected to result in lower CPU usage with approximately the same efficiency in most cases.
Element Creation in Nested CDT Operations
The CDT subcontext feature (added in Aerospike Server 4.6) allows operations that are targeted at nested lists and maps. In 4.9, this capability has been enhanced to optionally allow a specified list or map to be created if it does not yet exist when an application performs an operation on it.



