
We at Aerospike are excited to see a significant player such as Amazon acknowledge that the market demands high-performance databases for real-time data demands with their new EC2 High Memory instances for 6 TB, 9TB, and 12 TB of memory. Part of their motivation, as indicated, is to allow large in-memory databases to run in the same Amazon Virtual Private Cloud as connected business applications are running. We couldn’t agree more with the market’s need to reduce management overhead (in their case for “complex networking”) and ensuring “predictable performance.” These two tenets are core to Aerospike (see “Predictable High Performance” and “Low TCO”), albeit arrived at by different means than relying on co-location within a VPC. In fact, the Aerospike Predictable Performance and Low TCO are arrived at by not employing in-memory, but via our hybrid-memory architecture™. However, when one considers the Amazon application requirements, one needs to think about location of your data, your costs, and the restart experience and associated infrastructure. Overall, Amazon is increasing the awareness in this space, echoing where Aerospike has been playing these past several years.
Confirmation of Real-time Data Infrastructure
The Amazon announcement specifically indicates that the High Memory Instances “are purpose-built to run large in-memory databases.” In-memory databases, such as SAP HANA (which the Amazon announcement specifically cited), have real-time use cases.
According to SearchDataManagement, “In terms of specific in-memory DBMS uses, applications with real-time data management requirements can benefit, such as apps for telecom and networking, capital markets, defense and intelligence, travel and reservations, call center applications, and gaming. Applications with an immediate need for data are also candidates, such as apps for real-time business intelligence, fraud detection, real-time analytics and streaming data.”
While an in-memory mode of storage addresses the issue of high-performance and low latency, the TCO for building applications with in-memory storage is considerably high (due to DRAM costs). This is exactly the reason (depending on the latency constraints) data should instead be distributed across a storage hierarchy. Aerospike has been addressing this need with a very effective TCO using a spectrum of storage hierarchy – all while delivering the promise of low-latency.
Restarts Can be Challenging; In-memory size issues
One of the things that these High Memory instances are looking to do, in effect, is place more data in memory on fewer nodes. We at Aerospike couldn’t agree more: our TCO use cases repeatedly reduce the number of nodes for our clients over their existing, largely in-memory database architectures.
Meanwhile, we are routinely seeing larger and larger datasets from our customers, specifically in the context of real-time AI/ML based decisioning applications including a 160 TB use case from one of our largest customers in the payments industry.
While in-memory systems can certainly persist data to disk, issues arise when a node either crashes or the database needs to be updated and takes the node down. (Note: Aerospike keeps nodes online during updates.) Once a node goes offline for an in-memory database, you need to then rebuild the database into DRAM from disk. This takes time. For a 6-to-12 TB system, this could take several minutes if not longer. An unintended consequence of in-memory systems is to mandate replication factors of 3 or higher and thus more hardware. (Note: Aerospike typically recommends a replication factor of 2 by contrast.)
Hot data has specific needs (but can be delivered in multiple ways)
In the Amazon case, their High Memory Instances are catering to in-memory databases in the cloud to serve up hot data.
As stated in their announcement, they are looking to place data closer to their business applications. Interestingly, this is precisely what both Aerospike and Edge Computing look to do. Edge Computing, almost by definition, is outside the cloud. Putting data closer to your applications is always a good idea to facilitate speed.
According to Gartner VP & Distinguished Analyst, Thomas J. Bittman, in his webinar, “Digital Business Will Push Infrastructures to the Edge,” two of Edge Computing drivers are real-time, unpredictable interactions and digital business needs for the physical/digital convergence to capture business moments:
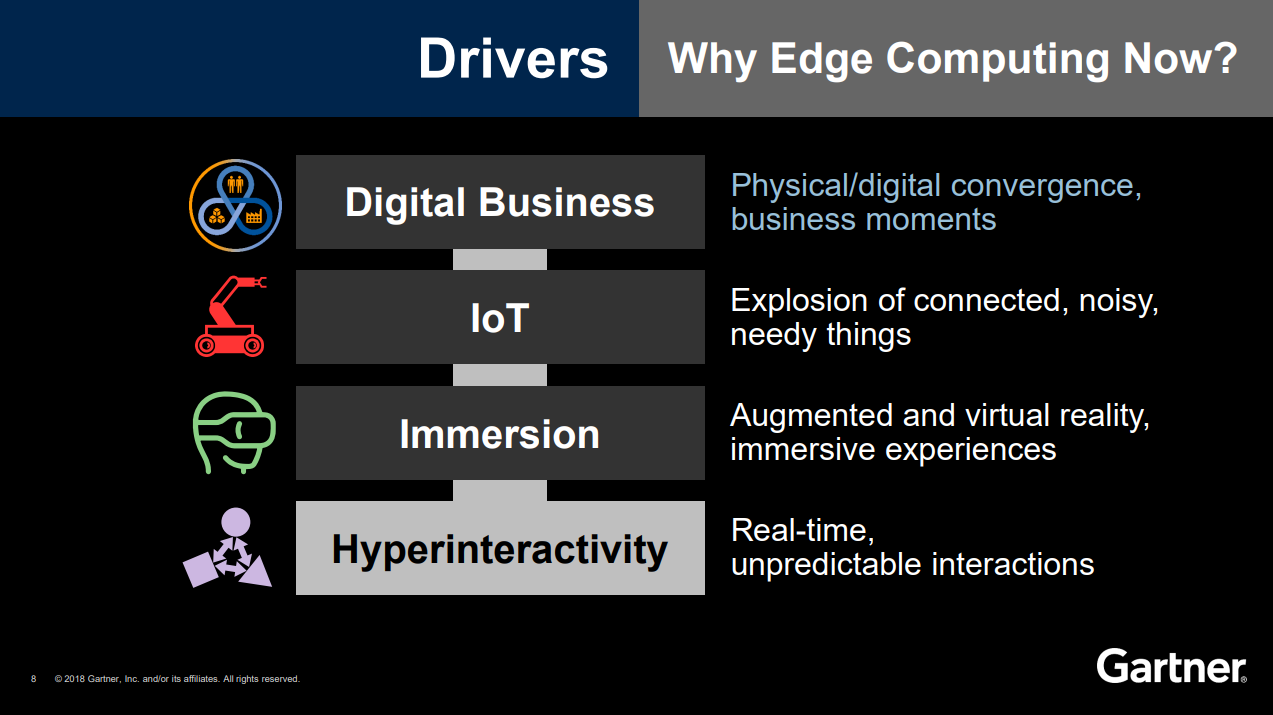
Aerospike has a number of ways to put data closer to applications: it can be run on bare metal or in the cloud, including Amazon EC2, Google Cloud Platform, and Microsoft Azure.
In addition, Aerospike has a flexible storage approach, that is, it can be deployed either in-memory or with it’s hybrid-memory architecture. The latter obviates the need for substantial amounts of costly DRAM (which is what the Amazon High Memory Instances consist of).
Databases need to play in the entire spectrum of the storage hierarchy
The storage hierarchy can range across in-memory, hybrid-memory, flash storage, or even HDD. Determining factors will depend on latency sensitivity of an application as well as the need for data movement between those clusters.
Our technology partner’s, Intel’s, Optane DC Persistent Memory Module and Optane SSD are great additions into the storage hierarchy. In effect, they expand and smoothen the “Latency-Cost curve”:
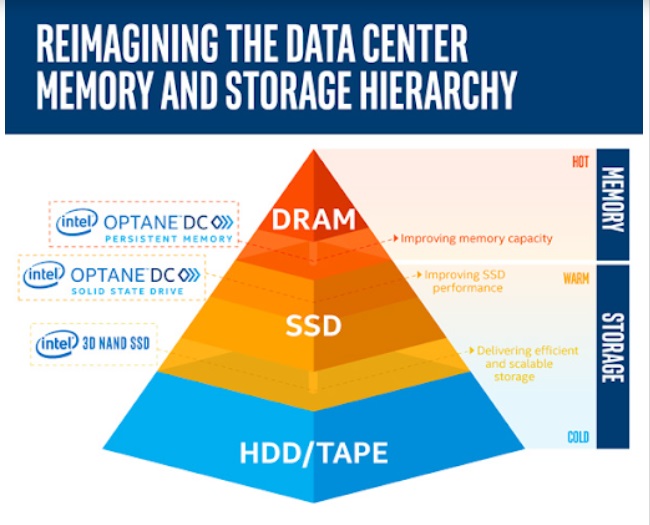
Aerospike envisions that as enterprises embark on their digital transformation, the lines between data temperatures will become blurred. The resultant benefit will be building-in latency tolerance. Data temperature and latency requirements should determine the data distribution across the storage hierarchy and each system/application should be able to gravitate to their storage needs accordingly (and not become “stuck” with a single storage vehicle). As a result, data needs the freedom to be seamlessly moved across those database setups with their corresponding latency tolerances.
And that’s why we see the Amazon High Memory instances as a partial if perhaps misguided step in helping digital data architectures.
Keep reading
Feb 2, 2026
Cache replacement policies explained

Feb 3, 2026
How Forter built a fraud decision engine that responds before you click 'buy'

Jan 28, 2026
Inside HDFC Bank’s multi-cloud, active-active architecture built for India’s next 100 million digital users

Jan 27, 2026
Aerospike named a finalist for “Most innovative data platform” in SiliconAngle Media’s 2026 Tech Innovation CUBEd Awards



