
Introduction
Batch operations are requests performed on multiple records. In Aerospike, batch reads have been available for a long time, and batch writes were introduced is Aerospike Database 6.0. Client versions like Java Client 6.0.0+ or Python Client 6.0.0+ enable the new batch write functionality.
Applications can leverage Aerospike's newly introduced batch writes to obtain significant improvements in ingest and update throughputs. Like many other Aerospike API operations, you can execute the batch operations in synchronous or asynchronous mode.
This blog post discusses the new batch write operations. Please check out this interactive tutorial, and work along.
. . . .
Execution Flow of Request
It is important to understand the various overheads and potential bottlenecks in the execution flow of a request in Aerospike. The client submits a request to the server for processing:
Combine or batch requests: Before sending a request for processing to the server, the application may combine it with other requests and send them together as a batch. The application may wait for some maximum duration for the batch to fill up, or send it as soon as a certain number of requests have been gathered.
Obtain a connection to server: The client library sends a request to the correct server node or splits it into multiple requests across nodes depending on where the records reside. The client library maintains a connection pool to each server node. Getting a connection to a server node from the pool is typically fast. Still, new connections need to be created if the connection pool has no connection available, or if your old connections are retired periodically.
Send the request and receive response: The request processing time involves the transfer time to send request and receive response, plus the processing time on the server. In synchronous mode, the request thread is blocked until a response is received.
Process the response: The application processes the response. Here, we assume the response processing time is similar across the various alternatives described below, and therefore can be ignored in comparisons.
. . . .
Single-Record Versus Batch Request
One obvious dimension to consider is the number of records involved in a request. In addition to the differences in send and receive, a batch request introduces special considerations for inline processing on server, as well as retries, as explained below.
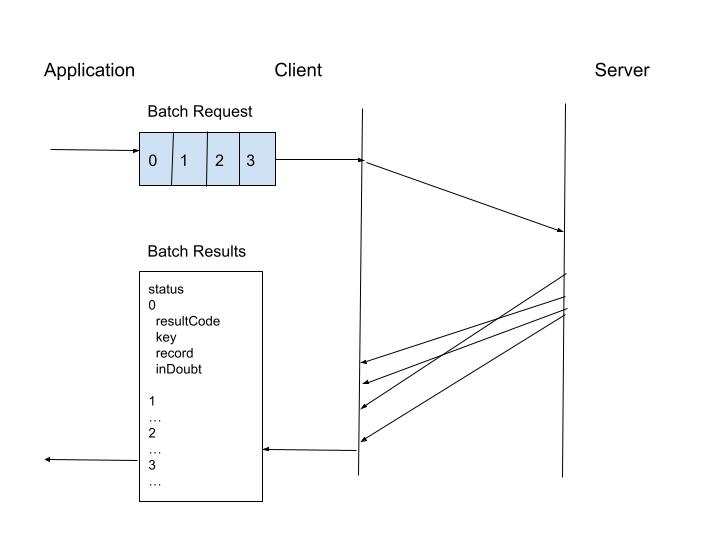
Synchronous Batch Request
Send
A single-record request can be sent as soon as it arrives whereas a batch request waits for the batch to be formed. Since the connection is shared for a batch request, there is saving in the time to obtain connections, as well as the number of connections used.
Receive
The application can receive the responses from the batch request all at once. In this case, the results for all operations are returned together, and the response time for an individual operation is the same as the slowest operation.
Aerospike also allows results from a batch request to be received as soon as they are available in the asynchronous mode. In this mode, the response time of an individual operation reflects its server processing time.
Inline Processing
The application can choose the processing on the server to be “in line” for a batch request, in which case a single server thread processes all operations in the batch. This (allowInline) is the default if all records belong to namespaces that are configured to have the data “in-memory”. In this case, inline processing is fast and efficient. The inline mode preserves the sequence of operations as they appear in the batch request. It is important to note that inline does not mean transactional semantics across the batch operations. If any records belong to namespaces that have the data on SSD, an inline setting (allowInlineSSD) is off by default, but can be explicitly turned on. Consider, however, the performance impact since the inline server thread blocks on-SSD read operations to retrieve the records in memory.
In general, operations in a batch request are processed by multiple server threads, and no assumption should be made about the ordering of operations in a batch.
Retry Processing
Although retries should be rare in a normally functioning system, it is worth noting how they are handled in a batch request processing. A retry of a server node’s sub-batch results in multiple smaller sub-batches sent to other server nodes, because the retry may have to go to an alternate partition replica location or node for each data partition involved in the sub-batch. Multiple such retries during cluster transition could result in a large number of such sub-batches - and connections - to process the original batch request.
Optimal Batch Size
The client library splits a batch into multiple sub-batches, one for each server node involved, and sends multiple sub-batches to multiple server nodes. Therefore, the batch size relative to the cluster size is important; planning for an average batch size much larger than the cluster size is necessary to get the benefit of batching at a server node level.
For the upper side of batch size, request and response sizes would play a role in server side allocation of additional buffers and the attending overhead. A large batch size can also introduce a larger buffering delay in the application for the batch to “fill up”. It is important to experiment with different batch sizes with your workload and deployment to arrive at the optimal range.
Synchronous Versus Asynchronous Execution
Most single-record as well as batch requests can be executed synchronously or asynchronously.
In synchronous mode, the requesting thread is blocked until the response arrives. This means the application’s thread resources can be less optimally used and more threads must be allocated to achieve desired parallelism and throughput, and this may become the bottleneck. Synchronous mode also incurs context switching overhead across a large number of threads.
Asynchronous mode avoids the performance issues of synchronous mode, and provides better resource utilization. On the other hand, synchronous mode could be easier to program and troubleshoot. If the application involves interdependent multi-step processing without stringent throughput needs, synchronous APIs may be more suitable.
. . . .
Execution Options and Tradeoffs
The combination of single-record vs batch and sync vs async, gives us the following options and tradeoffs.
Synchronous single request
A single request is sent to the server on a connection. The client waits for the results.
Requires multiple client threads and multiple connections to achieve parallel processing.
Inefficient resource utilization as multiple connections and threads wait from dispatch of the request to return of results, and also due to the context-switching overhead.
Synchronous batch request
Multiple operations are sent to the server as a batch. The client waits for all results to arrive.
Better parallelism and more efficient use of connection and thread resources.
May need multiple client threads and multiple connections to achieve more parallel processing.
Not optimal resource consumption as multiple requests have to be buffered to send in a batch, and the client must wait from dispatch of request to return of results.
Asynchronous single request
A single operation is sent to the server on a socket. The result is processed in a callback thread when it arrives.
Better parallelism and more efficient use of thread resources.
May need multiple connections to achieve more parallel processing.
Not optimal resource consumption as multiple connections are needed. Maximum parallelism is limited to the total number of available connections to the server, and can be as little as the total number of available connections to a single server node if all operations are mapped to the same node. A limit on the number of connections and connection turnover can limit the performance and throughput.
Asynchronous batch request
There are two options in async mode: 1) Wait on all results, and 2) Process individual results as they arrive.
Wait on all results
Multiple record operations are sent to the server on a connection. All results are delivered and processed together in a single callback.
Better parallelism and more efficient use of thread and connection resources.
Multiple connections can be used to achieve more parallel processing.
Multiple requests have to be buffered to send as a batch. Also, not optimal as all results are returned in one shot, causing all operations to have the response time of the slowest operation.
Process individual results as they arrive
Multiple record operations are sent to the server on a connection. A single record result is processed in a callback as it arrives.
Better parallelism and more efficient use of thread and connection resources.
Multiple connections can also be used to achieve more parallel processing.
Better response time.
Multiple requests have to be buffered to send as a batch.
Pipeline
In pipeline processing, the same channel to the server is used to send requests as they arrive, and receive responses as they become available.
This offers best resource utilization without having to wait in order to buffer/batch operations, have threads waiting until response is received, or obtain new connections to the server.
Each operation’s results can be processed as soon as they arrive, thus ensuring best individual response times.
Aerospike does not currently support the pure form of pipeline processing. However, in a busy client, asynchronous processing of batch requests is very similar to pipeline processing.
. . . .
New Batch Capabilities
Sync and async versions of the following new batch operations are now available.
Multi-key operate: Same list of operations are performed on multiple records. Most CRUD operations can be specified with the exception of UDF operations.
General batch operate: This is the general form of batch function, and allows multiple operations to be specified, each with its own key. In addition to most CRUD operations, UDF operations can also be specified.
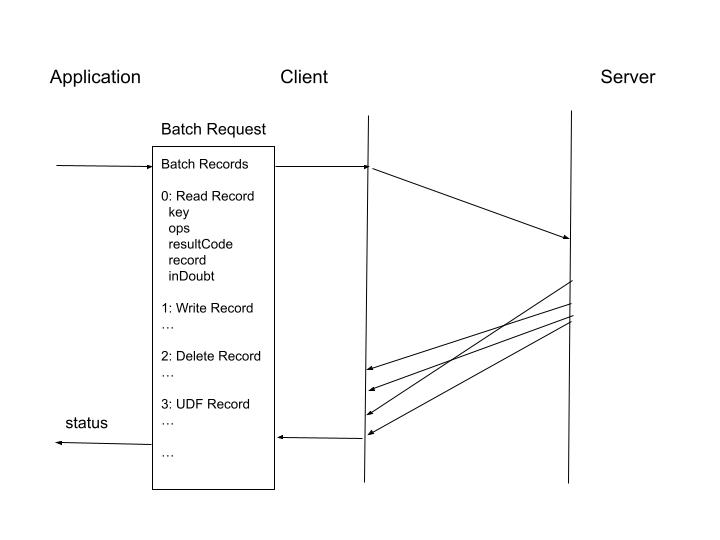
Synchronous General Batch Request
Multi-key delete: Multiple keys can be deleted in a batch.
Multi-key UDF execute: A single UDF operation is performed on multiple records.
. . . .
Key Points
Here are some key points about the batch operations in Aerospike. Entire batch is processed.
A batch can continue to be processed even if some operations fail.
The behavior is controlled by the batch policy respondAllKeys, the default being true.
A batch request is not atomic.
A batch is not processed atomically. There is no rollback available for partially successful operations.
Transaction boundary
The transactional boundary is assured for individual record operations. If a record is specified multiple times, the transaction boundary is limited to each specific occurrence.
Batch read is backward compatible with some changes.
The previously supported batch read APIs have not changed to ensure that the existing code using the batch read APIs does not break. However there are the following behavior changes:
By default, all keys in the request will be processed even if there are failures. In the old batch reads, if a node sub-batch returned an error, the entire batch operation failed.
Failures are returned separately for each record.
Operate now takes “read expressions”, which were introduced in server 5.7.
Set names are always sent. The policy option sendSetName is ignored, and is deprecated.
Matching results to requests
The key field in the response object (in addition to the array index in the response array) can be used to match the response to the request.
Overall batch status
Overall status of the batch is reflected in the “status” field of batch results. In case of a non-success status, you must walk through the partially filled record array to determine each operation’s result.
Use of filter expression
The filter expressions behavior is aligned with the semantics of the two batch operations:
Multi-key operations (operate, delete, UDF) are meant for the same operations and filter over multiple records. Therefore, although a multi-key operation takes two policies, an overarching batch policy and an operation specific policy, the filter expression in the batch policy is applied to all records, whereas the filter expression in the operation specific policy is ignored.
The general batch operate is meant for different operations and potentially different filters over individual records.Therefore, although the general batch operate works with an overall batch policy as well as a batch-record specific policy for each record, a filter expression when specified in the latter takes precedence over the one specified in the former.
Batch size limit
The maximum batch size in a request (sent to a single server node) is defined by the configurable server parameter batch-max-requests (default: 5000).
Many ways to perform a batch request
There are now multiple ways of performing a batch request.
Get or operate - both can be used to read multiple records
General batch operate is the most general form where any read/write/delete/UDF operations on any number of records can be performed. However, you may find the key-list form more convenient if the same set of operations is performed across multiple keys.
. . . .
Conclusion
Aerospike Database now supports batch writes, which can be executed in synchronous and asynchronous mode. Applications can leverage Aerospike’s newly introduced batch writes to obtain significant improvements in ingest and update throughputs.
Find code examples of Aerospike batch operations in this interactive tutorial.
Keep reading

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works

Apr 28, 2026
Aerospike Voyager: From first connection to production code
Apr 28, 2026
Introducing the Aerospike Java and Python SDKs: A generational upgrade to building on Aerospike

Apr 22, 2026
Aerospike vs. Cassandra: Databases don’t need to go down to break your application