The circuit breaker pattern
Learn how to implement the Circuit Breaker pattern and the importance of tuning it for high-performance applications.

The circuit breaker pattern is a design pattern used in microservices architecture to prevent service failures from impacting an entire system. Much like an electrical circuit breaker that interrupts the flow of electricity to protect appliances, the software-based circuit breaker monitors service interactions. When it detects an increase in failures—whether due to timeouts, server overload, or network issues—it "trips," halting traffic to the failing service. This allows the system to recover gracefully, avoid bottlenecks, and maintain system stability.
A circuit breaker operates in three primary states: closed, where requests pass through normally; open, where traffic to the failing service is halted; and half-open, where a small number of test requests are allowed to determine if the service has recovered. If these tests succeed, the breaker returns to the closed state; otherwise, it transitions back to open until recovery. Effective management of these circuit breaker states is crucial for maintaining system resilience, as it ensures a single component's issues don't bring down the entire application.
This pattern is particularly useful in systems where fault tolerance and resilience are critical, as it prevents the domino effect that often accompanies service disruptions in distributed systems. By implementing a fallback mechanism, a circuit breaker also provides an alternative response when the primary service is down, ensuring users still receive a timely response, even if it’s a failure message.
It also exemplifies graceful degradation in system design: rather than allowing partial failures to escalate into full-scale outages, a tripped circuit breaker will short-circuit calls to the faulty downstream service. This prevents cascading failures across other services in a microservices architecture and confines the impact to the isolated component.
The concept of the circuit breaker design pattern was popularized by Michael Nygard in his book Release It!, and it has since become a standard resilience pattern in modern software architecture and distributed systems. When implementing circuit breaker logic (often referred to as circuit breaking), developers often use existing libraries or frameworks rather than building the functionality from scratch. For example, Spring Boot applications can leverage Spring Cloud Circuit Breaker modules (or libraries like Netflix Hystrix and Resilience4j) to wrap calls to external APIs with circuit-breaking functionality. These circuit breaker libraries act as a safety net at the API gateway or within each service client—essentially functioning as a reverse proxy for outbound requests to downstream services. They monitor for consecutive failures or a high error rate, and if a threshold limit is exceeded, they will open the circuit and provide fallback responses (ensuring graceful degradation). Such frameworks also automatically manage the circuit breaker states, transitioning from closed to open to half-open as needed until the downstream service recovers and the circuit can close again, thereby improving overall fault tolerance.
Aerospike’s high-performance database client libraries implement the Circuit Breaker pattern by default so that application developers using Aerospike Database don’t have to worry about implementing the pattern themselves. However, tuning the circuit breaker threshold for a given use case is critical.
This post is a deep dive into the problem that the Circuit Breaker pattern is designed to address, how it solves that problem, and how to implement the Circuit Breaker pattern in Aerospike applications.
While not discussed here, Aerospike provides a number of additional configuration policies that are important for high-performance applications. See the Aerospike Connection Tuning Guide for details on the configuration policies not discussed in this post.
The problem
Failures in which the application doesn’t get a response from the database within the expected time frame, such as a temporary network disruption, can result in an amplification of the load imposed on the entire system. Factors contributing to this load amplification include the increased time network connections remain open waiting on a response, the overhead of churning connections that timeout, application retry policies, and back-pressure queueing mechanisms.
When applications perform high volumes of concurrent database operations at scale, this load amplification can be significantly greater than during steady-state. In extreme cases, this type of scenario can manifest as a metastable failure where the load amplification becomes a sustaining feedback loop that results in the failed state persisting even when the original trigger of the failure state (network disruption) has been resolved.
As a simple example, consider a typical HTTP-based API in which an HTTP request to the application results in a single database read. This is illustrated in the sequence diagram below:
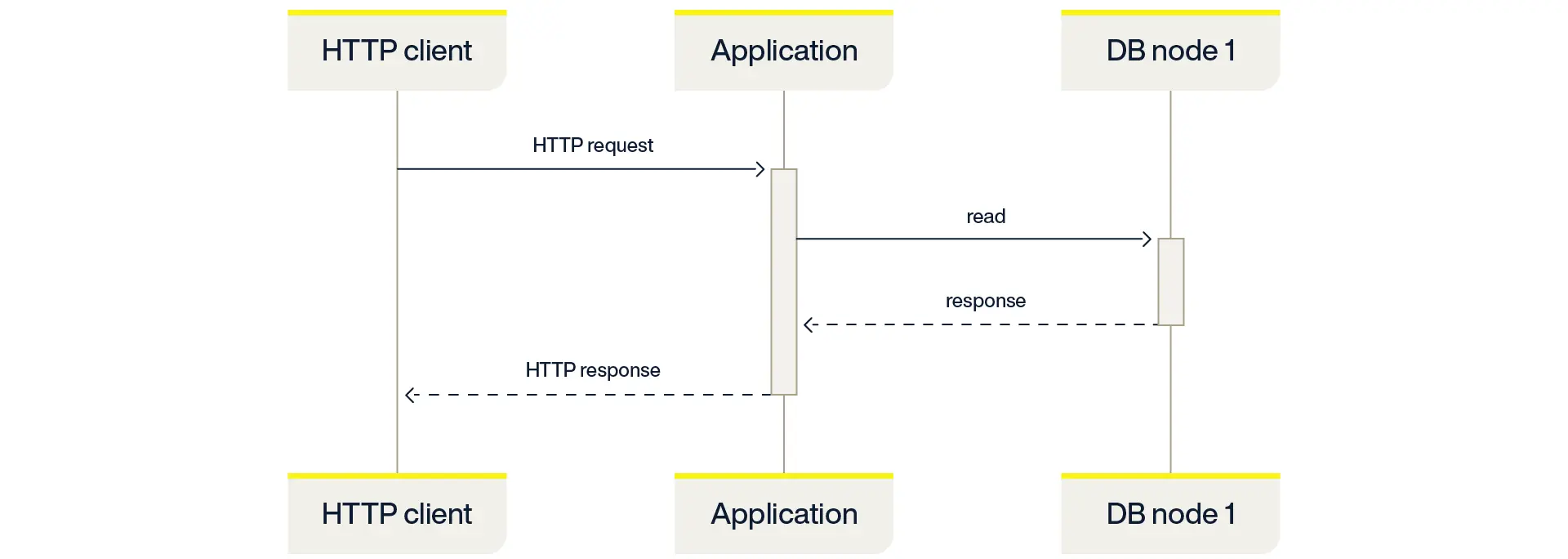
The system load created from this steady-state usage pattern is often what the system is designed to be able to sustain.
But now consider what happens when there is a network failure that results in the application timing out database operations. Since the application doesn’t know the nature of the network timeout, it might also close the TCP connection and open a new one (connection churn). Churning connections can be expensive–especially when connecting must do a TLS handshake. Database applications designed for high availability often retry read operations against replicas (Aerospike does by default), which, during this type of failure, could also timeout and churn another connection per retry.
This is illustrated in the sequence diagram below:
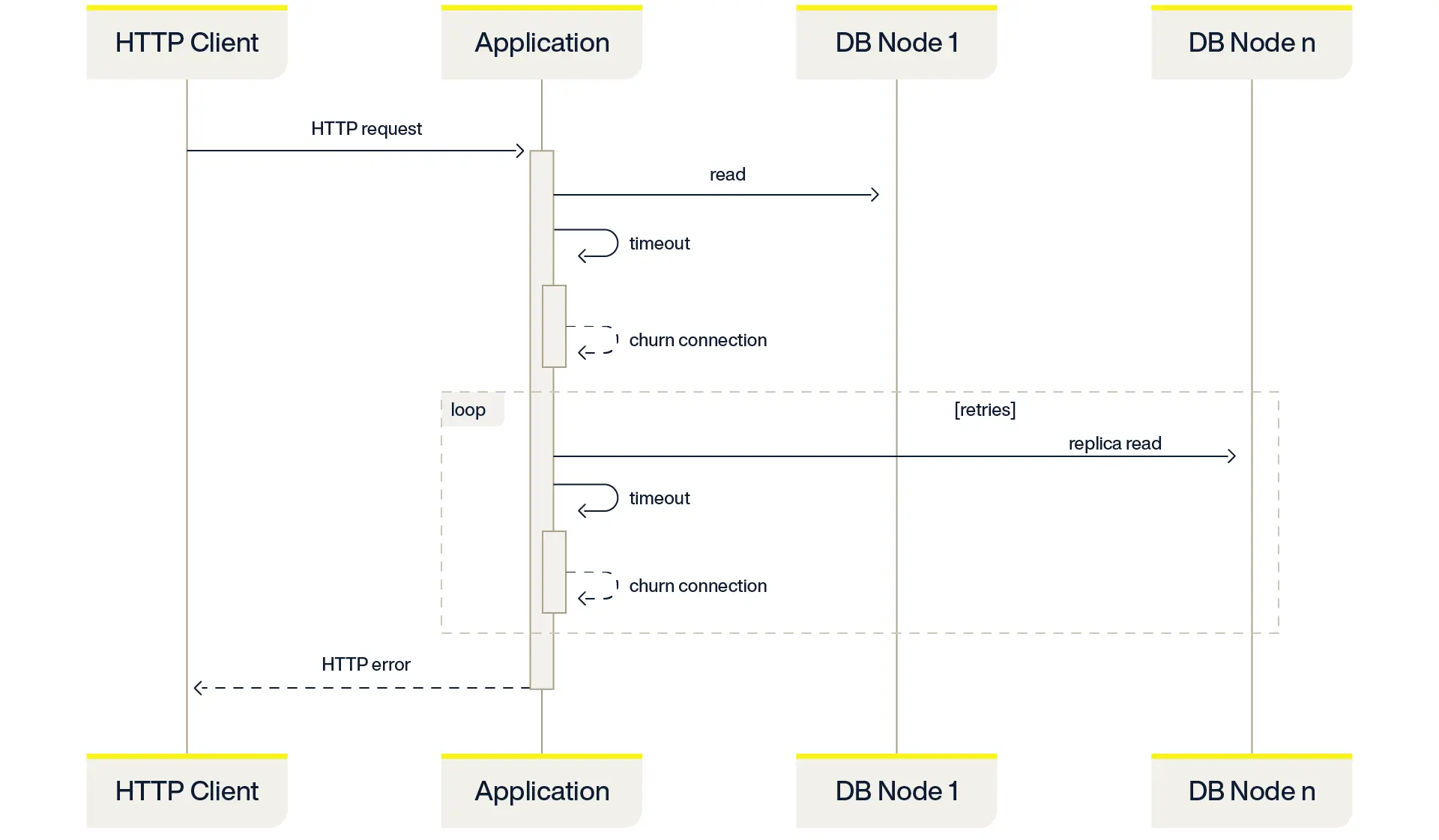
Each attempted transaction is now consuming significantly more time and resources than it would during steady state. This is “load amplification” triggered by the network outage.
Now imagine hundreds or thousands of concurrent application threads performing hundreds, thousands, or millions of database operations per second. The cost of churning a connection adds up at scale. A network outage lasting mere seconds can trigger a metastable failure that lasts far beyond the trigger event, and the only way to recover is to reduce the load on the system. Simply scaling the system to handle the worst-case load amplification wouldn’t be practical or cost-effective.
How the circuit breaker pattern works
Much like its namesake component in electrical systems, the Circuit Breaker pattern will “trip the breaker” when the number of failures in a given time period exceeds a predefined threshold. The idea is to put a hard limit on the impact of these types of failures–to break the feedback loop–and recover quickly and automatically once the underlying trigger is resolved.
The Aerospike implementation of the Circuit Breaker pattern, which is built into the Aerospike client libraries and enabled by default, will trip when there are 100 or more errors within an approximate 1-second window. Both the threshold and the time window are configurable.
Under the hood, a circuit breaker object tracks a failure counter over a rolling time window (counting recent failed operations). If the count of recent failures exceeds the threshold limit (indicating an unacceptable failure rate), the breaker will trip open to prevent further damage.
As a simplified example, assume an application is performing 1,000 database read operations per second and a network failure occurs that lasts for 2 seconds. During each of those seconds, when the network is failing, the application would get 1,000 network errors and thus would result in 1,000 churned connections.
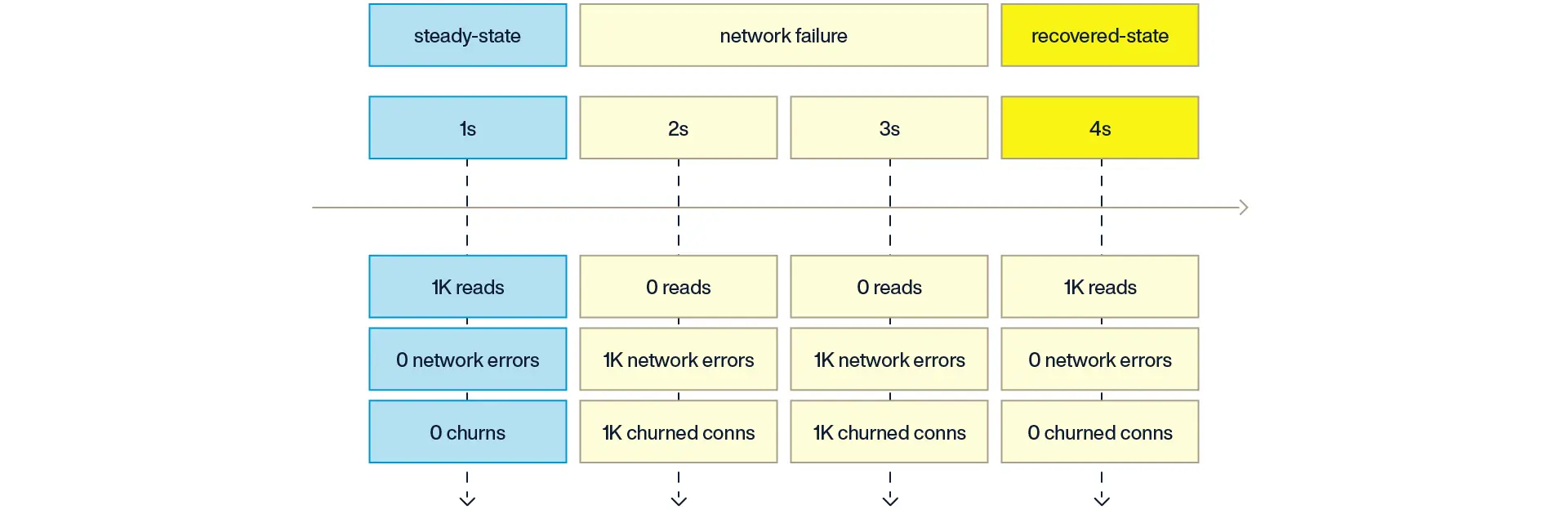
With the Circuit Breaker pattern in place, the application would instead only get network errors up to the configured threshold (100) each second, and the remaining 900 operations within that one-second window would instead immediately raise an exception rather than trying to connect to the database server. As a result, the application would only churn 100 connections each second rather than 1,000.
In other words, the impact of a network failure is limited to churning 100 connections per second, and the system only needs to be designed to handle that limited amount of load amplification.
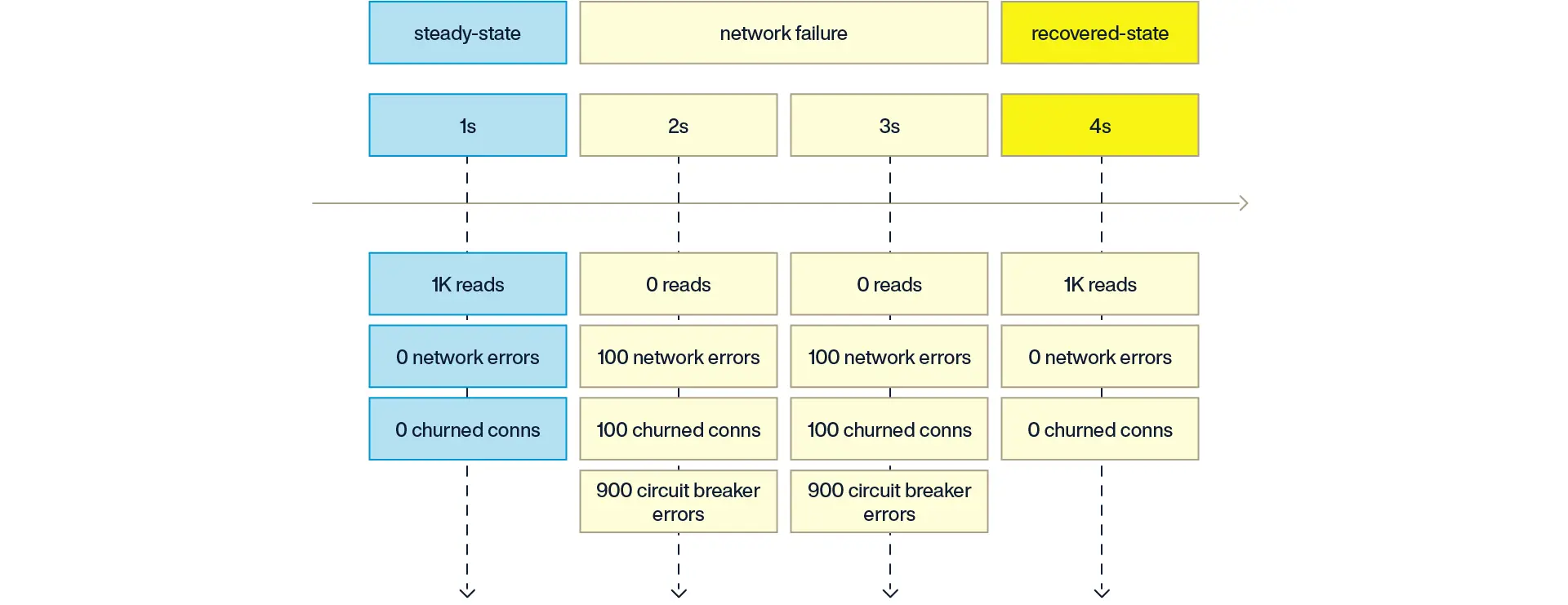
The application would then handle the exceptions raised when the circuit breaker has tripped according to the use case. For example, the application may abandon those operations as a hard failure, implement an exponential backoff, save those operations in a dead letter queue to be replayed later, etc.
Aerospike circuit breaker in Java
The Circuit Breaker pattern is enabled in the Aerospike Java client by default. However, you can tune the number of errors per tend interval (approx. 1 second) to suit your use case.
For example, to reduce the threshold from the default value of 100 errors per second to 25 errors per second:
import com.aerospike.client.IAerospikeClient;
import com.aerospike.client.Host;
import com.aerospike.client.policy.ClientPolicy;
import com.aerospike.client.proxy.AerospikeClientFactory;
Host[] hosts = new Host[] {
new Host("127.0.0.1", 3000),
};
ClientPolicy policy = new ClientPolicy();
policy.maxErrorRate = 25; // default=100
IAerospikeClient client = AerospikeClientFactory.getClient(policy, false, hosts);The application would then handle the exceptions raised when the circuit breaker threshold has been tripped using the MAX_ERROR_RATE attribute of the ResultCode member of the exception:
switch (e.getResultCode()) {
// ...
case ResultCode.MAX_ERROR_RATE:
// Exceeded max number of errors per tend interval (~1s)
// The operation can be queued for retry with something like
// like an exponential backoff, captured in a dead letter
// queue, etc.
break;
// ...
}Example code
This is an example Java application that demonstrates how the Circuit Breaker design pattern is implemented in Aerospike. It includes examples of error handling and instructions on simulating failures.
Tuning the circuit breaker threshold
While the default value of maxErrorRate=100 has been proven to protect against metastable failures by the Aerospike performance engineering team, the optimal value ultimately depends on the use case.
Setting the threshold effectively puts a cap on the number of connections that are churned per second (approximately) in a worst-case failure scenario. The cost of a connection churn can vary. For example, a TLS connection takes more resources to establish than a plain TCP connection. Logging a message on every failure is more expensive than incrementing a counter.
Managing failure thresholds in a distributed system is critical to avoid unnecessary retries or premature circuit breaker activation. For example, in systems using a timeout pattern, a short timeout threshold could cause the circuit breaker to trip too early, potentially blocking a service that’s only experiencing a temporary high-latency issue. By setting an optimal failure threshold, services can allow for small transient failures without disrupting the overall system.
Consider a service with a consecutive failure threshold of three. Each failed call is logged, and after three failures, the circuit breaker transitions from closed to open. While this sounds simple, managing these failures requires tuning both the retry pattern and the timeout periods to avoid overloading the system with excessive retry requests, which could exacerbate existing issues, such as network congestion.
In such scenarios, the retry pattern can be configured to exponentially back off, allowing for more effective error handling. For instance, an initial retry may happen after 2 seconds, followed by 4, and so on, allowing the system to recover gradually instead of bombarding it with frequent retries. This method reduces the likelihood of cascading failures, as retry requests are spaced out, giving services the time they need to recover without overwhelming the system.
When it comes to high-latency services, the circuit breaker design pattern provides a buffer that prevents overwhelming the system with requests. A well-configured circuit breaker not only manages failures but also works in tandem with the bulkhead pattern, which isolates failing services from the rest of the system, ensuring system resilience.
So the questions you have to ask are:
How many connections opened/closed per second can each of my application nodes reasonably handle?
How many connections opened/closed per second can each of my database nodes reasonably handle?
Every Aerospike client instance connects to every server node. So, with 50 application nodes and the default value of maxErrorRate=100, a single database node might see approximately 5,000 connections churned per second in the worst-case failure mode.
Then, consider what happens on the server when a connection churns. Depending on the type of failure, there might be a log message from the failure. When using the Aerospike authentication and audit logs there can be an audit log message for the attempted authentication while connecting. So with those two log messages there could be approximately 10,000 log messages per second during this type of failure mode.
Can your logging stack handle that volume from each Aerospike node?
Dropping the value down to maxErrorRate=5 would lower that worst-case log volume down to approximately 250 log messages per second. The trade-off would be that a larger number of the transactions during that window would need to be addressed by the application (exponential back-off, dead-letter queue, etc).
But that trade-off is acceptable if you leverage other techniques for resiliency at scale, such that the Circuit Breaker pattern is a last resort for just the most extreme failure scenarios. Less severe disruptions, such as high packet loss, single node failures, short-lived latency spikes, etc., can be mitigated before tripping the circuit breaker in the first place.
The policies that can provide that additional resilience at scale are documented in the Aerospike Connection Tuning Guide. An in-depth explanation about how they work is discussed in Using Aerospike policies (correctly!).
Key takeaways
For large-scale and high throughput applications, it is critical for applications to be designed for resilience to network disruptions.
The circuit breaker design pattern protects the application and the database from failures that could otherwise overwhelm the system.
The Aerospike client libraries implement a circuit breaker pattern and expose it to developers as a simple policy configuration.