
Aerospike is renowned as a very fast, very scalable database capable of storing billions or trillions of records, as well as being able to replicate the data to multipe remote database clusters. Hence, a common question which arises is: "How can I validate that two clusters are in sync?". This used to be a difficult problem, but new API calls in Aerospike v5.6 make this task substantially easier. In this blog we will look at one of these new API calls and use it to develop some code to show how a cluster comparator could be written.
Premise
Let's assume we have 2 clusters called "A" and "B" with 10 billion records in them and the records are replicated bi-directionally. We want to efficiently see if the clusters have exactly the same set of records in them. There are a couple of obvious ways to do this, by comparing record counts and by using a primary index query with batch gets. Both of these approaches have flaws however. Let's take a look at these.
Comparing record counts
The first way we could check if the clusters have exactly the same set of records in them is by comparing record counts. Aerospike provides easy ways to get the total number of records in either a namespace or a set, so we could get a count of all the records in both clusters "A" and "B" per set and compare the 2 values. This relies only on metadata which the cluster keeps updated and so is blazingly fast. However, this can only determine that the clusters are different when the counts don't match.
What this approach lacks is:
The ability to determine which records are missing. Let's say cluster "A" has 10,000,000,000 records and cluster "B" has 10,000,000,005. Which 5 records are missing from cluster "A"? This cannot be determined by this method, although the set(s) with the missing records might be able to be determined.
Even if the record counts match, there is no guarantee that they both contain the same set of records. Consider a set with records 1,2,3,4,5 with the corresponding set on the other cluster having records 4,5,6,7,8. Both clusters would report 5 records, but the sets clearly do not contain the same records.
Using a Primary Index Query with Batch Gets
A different approach without the above limitations would be to do a primary index (PI) query (previously called a scan) on all the records in cluster "A". Then, for each record returned by the PI query, do a read of the record from cluster "B". If the record is not found, this is a difference between the clusters. We could optimize this by doing a batch read on cluster "B" with a reasonable number of keys (for example 1000) to minimize calls from the client to the server. This would complicate the logic a little but it's still not bad.
However, this approach suffers from the drawback that it will only detect missing records in cluster "B". If a record exists in cluster "B" and not in cluster "A", this approach will not detect it. The process would need to be run again, with "B" as the source cluster and then batch reading the records from cluster "A".
Using QueryParitions
Since Aerospike came out with PI Queries which could guarantee correctness even in the face of node or rack failures in version 5.6, another way has existed, using queryPartitions. (Note: in versions prior to 6.0 the API call for this is scanPartitions. This still exists today but is deprecated). Before we can understand what this call does, we need to understand what a partition in Aerospike is.
Partitions
Each Aerospike namespace is divided into 4096 logical partitions, which are evenly distributed between the cluster nodes. Each partition contains approximately 1/4096th of the data in the cluster, and an entire partition is always on a single node. When a node is added to, or removed from the cluster, the ownership of some partitions is changed so the cluster will rebalance by moving the data associated with those partition between cluster nodes. During this migration of a partition the node receiving the partition cannot serve that data as it does not have a full copy of the partition.
Data within a partition is typically stored on Flash (SSD) storage and each partition stores the primary indexes for that partition in a map of balanced red-black trees:
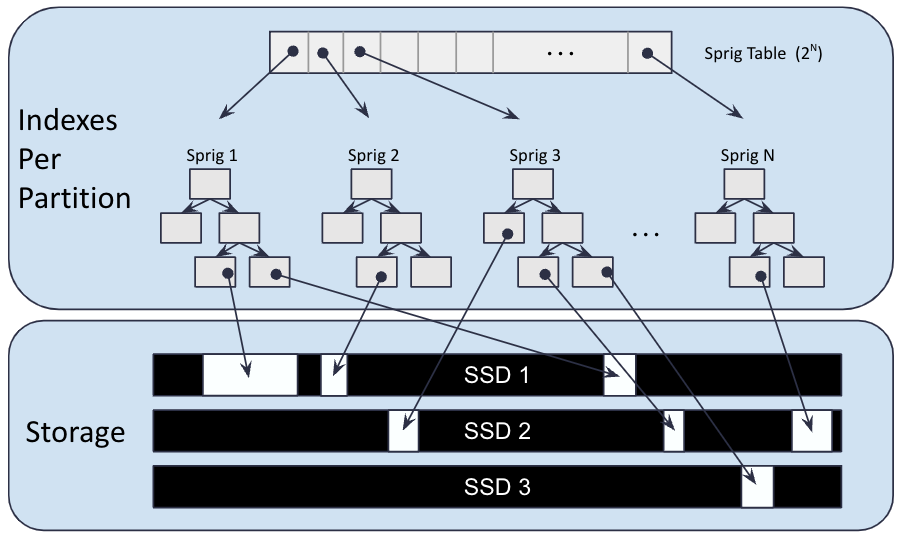
Primary indexes and storage
Each tree is referred to as a "sprig" and the map holds pointers to the sprigs for that partition. There are 256 sprigs per partition by default, but this is changeable via the partition-tree-sprigs config parameter.
QueryPartitions
The queryPartitions method allows one or more of these partitions to be traversed in digest order. A digest is a unique object identifier created by hashing the record's key and the red-black trees depicted above use the digest to identify the location of a node in the tree.
When a partition is scanned, a single thread on the server which owns that partition will traverse each sprig in order and within that sprig will traverse all the nodes in the tree in order. This means that not only will we always get the returned records in the same order, but also that 2 different namespaces - even on different clusters - which contain the records with the same primary key and the same set name will always be traversed in exactly the same order.
Implementing a Comparator
Let's look at how we can use this to implement a comparator between 2 clusters. Let's assume there is only one partition for now. We know that the records in this partition will be returned in digest order, so we can effectively treat it as a very large sorted list. (If there are ~10 billion records in the cluster, there are 4096 partitions so each partition should have about 2.4 million records).
To illustrate how we will do this, let's consider 2 simple clusters each with 12 records in partition 1:

2 simple partitions and their data
(Note that the numbers represent the digest of the records).
If we were to query this partition on cluster 1 and cluster 2 at the same time, each time we retrieved a record from the queries we would have one of three situations:
The record would exist in only cluster 1
The record would exist in only cluster 2
The record would exist in both clusters.
The first time we retrieve a record from each cluster we will get record 1 on each:

After retrieving the first record on each cluster
The current record on cluster 1 (Current1) and the current record on cluster 2 (Current2) both have a digest of 1, so there is nothing to do. We read the next record on both clusters to advance to digest 2, which is again the same. We read digest 3 (same on both) so we read the next record on both which gives:

Situation after reading next record after digest 3
When we compare digests here Current1 has digest 5 but Current2 has digest 4. We need to flag the record which Current2 refers to (4) as missing from Cluster 1 and then advance Current2, but not Current1:

After flagging record 4 as missing from Cluster 1 and advancing Current2
We're now back in the situation where the 2 values are equal (5) so they progress again as before.

Situation after reading next record after digest 5
Here Current1 has 6 but Current2 has 7. We need to flag the record which Current1 refers to (6) as missing from Cluster 2 then advance Current1.
This process is repeated over and over until the entire partition has been scanned and all the missing records identified.
The code for this would look something like:
RecordSet recordSet1 = client1.queryPartitions(queryPolicy, statement, filter1);
RecordSet recordSet2 = client2.queryPartitions(queryPolicy, statement, filter2);
boolean side1Valid = getNextRecord(recordSet1);
boolean side2Valid = getNextRecord(recordSet2);try {
while (side1Valid || side2Valid) { Key key1 = side1Valid ? recordSet1.getKey() : null;
Key key2 = side2Valid ? recordSet2.getKey() : null;
int result = compare(key1, key2);
if (result < 0) {
// The digests go down as we go through the partition, so if side 2 is > side 1
// it means that side 1 has missed this one and we need to advance side2
missingRecord(client2, partitionId, key2, Side.SIDE_1);
side2Valid = getNextRecord(recordSet2);
}
else if (result > 0) {
missingRecord(client1, partitionId, key1, Side.SIDE_2);
side1Valid = getNextRecord(recordSet1);
}
else {
// The keys are equal, move on.
side1Valid = getNextRecord(recordSet1);
side2Valid = getNextRecord(recordSet2);
}
}
}
finally {
recordSet1.close();
recordSet2.close();
}Enhancements
This process will identify missing records between the 2 clusters but not validate the contents of the records are the same between both clusters. If all we need is to identify missing records, the contents of the records are irrelevant - we just need the digest which is contained in the record metadata. Hence, when we set up the scans we can set the query policy to not include the bin data by using:
queryPolicy.includeBinData = false;This will avoid reading any records off storage and send a much smaller amount of data per record to the client.
Should we wish to compare record contents, includeBinData must be set to true (the default). Then when the digests are the same we can iterate through all the bins and compare contents. This is obviously slower - Aerospike must now read the records off the drive, transmit them to the client, which will then iterate over them to discover differences. However, this is a much more thorough comparison.
Handling multiple partitions
This process works great for one partition, but how do we cover all partitions in a namespace? We could just iterate through all 4096 partitions applying the same logic. To get concurrency, we could have a pool of threads, each working on one partition at a time and when that partition is complete they move onto the next one which has not yet been processed. This is simple, efficient and allows concurrency to be controlled by the client. Each client-side thread would use just one server-side thread per cluster so the effect on the clusters would be well known.
It would be possible to have the server scan multiple partitions at once with a single call from the client. However, this is more complex as the results would contain records over multiple partitions, so the client would need to keep state per-partition and identify the partition for each record.
Implementation
A full open source implementation of this algorithm can be found here. This includes many features such as:
Optional comparison of record contents
Logging the output to a CSV file
The ability to "touch" records which are missing or different to allow XDR to re-transmit those records
Selection of start and end partitions
Selection of start and end last-update-times
Metadata comparison
Whilst there are a lot more features than are presented in this blog, fundamentally it is based on the simple algorithm presented here, all possible due to the nature of queryPartitions.
Keep reading

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works

Apr 28, 2026
Aerospike Voyager: From first connection to production code