
This is the first in a series of blog posts intended to help folks who may be struggling with deployment of an Aerospike database. I'm part of the Aerospike Developer Relations team, but I spend most of my days playing around with websites or writing code samples, and not deploying databases in real-world contexts. I hope that you can follow along with me as I fumble my way through a production build and create a tool that will not only help me with my job, but also help me learn a whole lot more about Aerospike.
Let me make the mistakes so you don't have to! Or do make them, that's cool too.
The situation
I have two websites, hosted on Netlify, that generate traffic logs. I want to analyze those traffic logs to see what is currently being used, and what gaps exist, within our content.
Netlify provides these logs - JSON documents - through a log drain that can hook up to a variety of third-party monitoring services. Those are great, but I want to keep everything in house (in my own cloud?), so I'll start by exploring the options to send logs to Amazon's Simple Storage Service (S3), or to my own http endpoint.
Once the logs hit S3, or my endpoint, I need to store them somewhere - enter Aerospike. I want Aerospike to ingest the logs and allow me to query data from a dashboard of my making. Defining a good data model is important, as it can prevent a lot of client-side processing, letting the server do the heavy lifting.
Step one - make a plan.
The plan
If I'm going to do this, I may as well overdo this, so lets get wild and go with a Kubernetes cluster on Amazon Web Services (AWS), maybe a few serverless Lambda functions, some connectors, and whatever else might be fun to play around with.
But for now, the basics. This is what I'm hoping to accomplish.
Create a Virtual Private Cloud (VPC) on AWS.
Deploy an AWS Elastic Kubernetes Service (EKS) cluster in the VPC.
Deploy an Aerospike cluster within the EKS cluster.
Create a data model that best suits the query needs against the documents being stored.
Get said documents from Netlify's log drain to Aerospike.
Build a dashboard to retrieve and analyze data.
Sounds easy enough.
A note on execution
This post focuses on steps one, two, and three of the plan. As we go through how I set this up, remember that the steps I took are what worked best for me as I learned my way through it. If you find a better path, I would love to hear about it.
For this series, I assume you have some basic knowledge of working with AWS. If you're new to the platform, checkout the getting started guide.
The VPC
Credit where credit is due, this Medium post was a massive help to me in getting this setup. I followed along and used this AWS CloudFormation template. The template creates an EKS-ready VPC that includes:
an internet gateway connected to two availability zones.
a public and private subnet in each availability zone.
a route table allowing access to the private subnet.
a NAT gateway with an Elastic IP, connecting to the route table.
Whew!
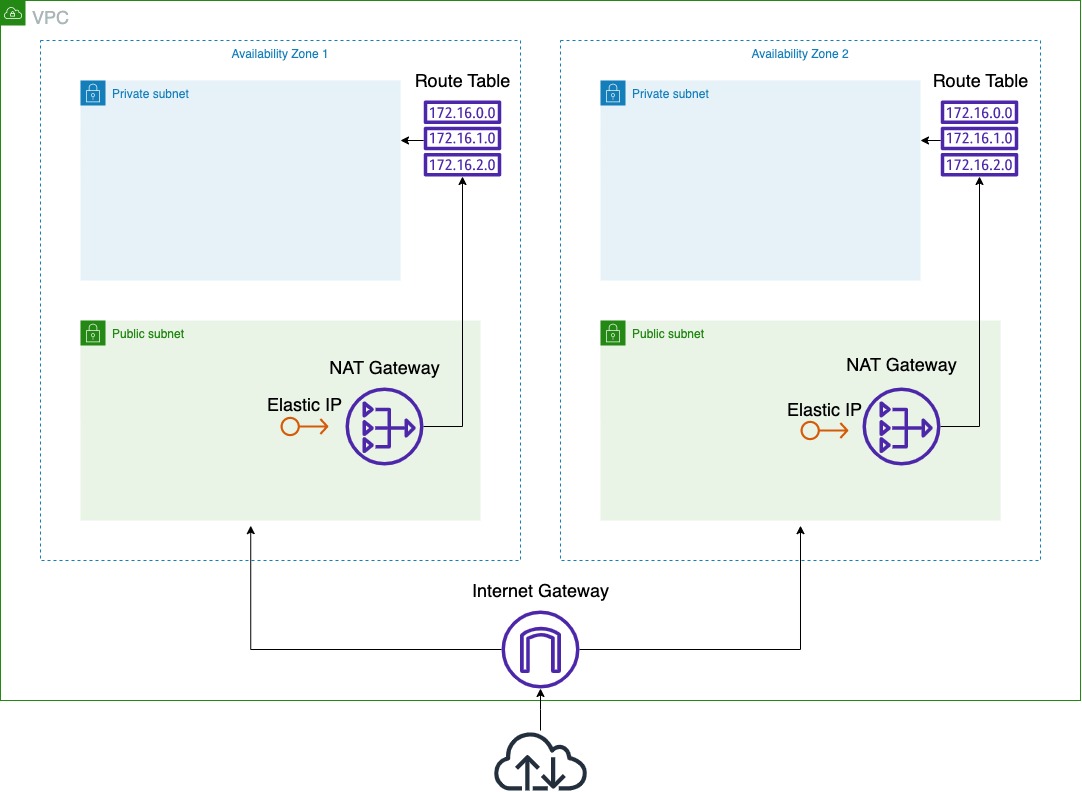
A simple diagram of our VPC
The goal of the template is to have the EKS worker nodes in the private subnet, while the control plane lives in the public subnet. That allows access to the cluster endpoint from outside the VPC, but worker nodes and their traffic are confined to the VPC. More on this later.
To start, log into your AWS account, navigate to the CloudFormation tool, and follow the steps to create a stack.
Copy the template link above and plug it into the Amazon S3 URL input.
On the next page give the stack a name and define the Worker Network Config (I left everything at the defaults).
Click through the next few pages, leaving the defaults (or not, I'm not your boss), then create the stack.
I did have to repeat this step a few times because I didn't realize that my account already had five Elastic IPs in use. If you're in the same boat as I was, you can do some cleanup or contact Amazon for more Elastic IPs.
It takes a few minutes to get everything setup, and after completion we can add one last thing - tags.
This step eluded many setup guides and threw me for a loop for quite some time. I'm sure there's a better way to do this, but this is how I went about tagging my subnets.
Head over to the VPC dashboard, select Subnets from the sidebar, then select each subnet one by one and add these tags:
Key | Value |
(Only on private subnets) | |
(Only on public subnets) | |
| |
We haven't created the EKS cluster yet, but if the name is already known, add the tag now. Otherwise, come back after creation.
The cluster (EKS)
I'm not going to lie, this part I struggled with - a lot. I highly recommend familiarizing yourself with the EKS getting started guide, though I do say, it only helped moderately. Breaking things a number of times is really where I feel I learned the most.
I went through the majority of this using the AWS Management Console. You can do most, if not all, of what I'm about to do through eksctl. Feel free to check that out if the command line is more your speed.
You need to install a few tools first: kubectl to interact with the Kubernetes cluster from the terminal, and AWS Command Line Interface (CLI) to interact with AWS from the terminal.
Important! the Identity and Access Management (IAM) entity used to create the EKS cluster is the only IAM entity with access to the cluster after creation. You can add users later, just don't use a root user!
Roles
Lets start by creating a few IAM roles necessary for the EKS cluster to function. These roles give the deployment the permissions they need to interact with other AWS resources.
Head over to the IAM dashboard and select Roles from the left sidebar. Click Create role in the top right to get started.
EKSClusterRole: this role is used when creating the cluster.
Select Custom trust policy and add the following to the JSON document and click next.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "eks.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}2. In the Permissions policies search field type eks and hit return. Select the AmazonEKSClusterPolicy and click next.
3. Give the role a unique name and description and click Create role at the bottom to finish.
EKSNodeRole: this role is used for node creation and gives EKS access to Elastic Compute Cloud (EC2). Follow the same steps as above, with these small changes:
1. In the trust policy, swap "Service": "eks.amazonaws.com" with "Service": "ec2.amazonaws.com"
2. In the permissions policies select AmazonEKSWorkerNodePolicy and AmazonEC2ContainerRegistryReadOnly.
If you're following the AWS docs, you may have noticed they say to also add AmazonEKS_CNI_Policy. We'll create a separate role for that before creating any cluster nodes, as it is a best practice to separate the CNI role from the Node role in production clusters.
Into the kube
Now that we've setup a few base roles, head over to the EKS console to create the EKS cluster.
After you click Add cluster -> Create, add the cluster name and select the EKSClusterRole role setup above. Click next when complete.
2. On the networking page, select the VPC created earlier. The subnets should automatically populate and select the control plane security group that was created with the VPC.
I started with the Public and private option for Cluster endpoint access but eventually switched to Private. I'll discuss this in another post, but for now, Public and private works fine. I left all add-ons at the defaults as well.
3. Leave everything else at the defaults, at least that's what I did. Click next until you are able to click Create, then wait until the cluster is active.
With that done, we can now setup our EKSVPCCNIRole role. This role controls VPC networking for pods on our cluster nodes.
1. We'll start with a little setup. Hopefully you've already installed and setup AWS CLI and installed kubectl. If not, go do that now.
From the terminal run the following command to setup communication between your machine and the cluster (this isn't necessary right now, but we may as well make the connection).
aws eks update-kubeconfig --region <your-region-code> --name <your-cluster-name>Run the following to get the cluster's OIDC provider URL:
aws eks describe-cluster --name <your-cluster-name> --query "cluster.identity.oidc.issuer" --output textIt should look like this:
https://oidc.eks.region-code.amazonaws.com/id/EXAMPLED539D4633E53DE1B71EXAMPLE Copy it, head over to the IAM console, and select Identity providers from the left sidebar.
2. If there isn't already a provider that exists with the URL from step two, click Add provider.
3. Choose OpenID Connect, add the URL from step one to the Provider URL field, click Get thumbprint, add sts.amazonaws.com to the Audience field, and click Add provider.
4. Now that we have all that set, follow the role creation steps from before, this time using the following for the trust provider (fill in your info accordingly):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::<your-aws-account-id>:oidc-provider/oidc.eks.<your-region>.amazonaws.com/id/<your-oidc-id>"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"oidc.eks.<your-region>.amazonaws.com/id/<your-oidc-id>:aud": "sts.amazonaws.com",
"oidc.eks.<your-region>.amazonaws.com/id/<your-oidc-id>:sub": "system:serviceaccount:kube-system:aws-node"
}
}
}
]
}Then select the AmazonEKS_CNI_Policy for the permissions policies.
5. Finally, head back into the EKS console, open the cluster, select Add-ons, open the vpc-cni add-on, click Edit, then select the new role we just created and click Update. This will take a few minutes to complete.
We have a cluster! Holy cow, there is still so much more to do...
Nodes
The nodes created and used within the cluster are largely dependent on your use case. For this project I setup a node group with two nodes, r5a.large EC2 instances, each with a 400GB Elastic Block Storage (EBS) volume that I'll be setting up for persistent storage. I'm not doing any autoscaling - yet, but you may want to explore that avenue.
When setting up the node group, use the EKSNodeRole from earlier. Checkout Creating a managed node group for more detailed instructions.
The operator
The Aerospike Kubernetes Operator is built to automate deployment and management of Aerospike clusters in Kubernetes.
Our great engineers and technical writers have already put together an awesome guide on installing the operator and deploying an Aerospike cluster. What I want to talk about are the problems I ran into during my journey.
OLM
The two available paths for setup use either Helm or Operator Lifecycle Manager (OLM). I went down the OLM path and can say that after my first small hiccup, it was a pretty smooth sailing. The problem I ran into was with the install. Maybe I did it to myself by going down the kubectl path for installation - we'll never know - but regardless, this is what happened.
First, I used the following commands to install OLM:
1. kubectl apply -f https://github.com/operator-framework/operator-lifecycle-manager/releases/download/<olm_release>/crds.yaml
2. kubectl apply -f https://github.com/operator-framework/operator-lifecycle-manager/releases/download/<olm_release>/olm.yaml
The problem arose from the fact that command one was missing an important flag, failing the install and leaving me with a non-function OLM. Adding --server-side=true to the first command remedied that problem for me.
After getting past that hurdle I ran into one more issue with my deployment - storage.
Storage
I used the ssd_storage_cluster_cr.yaml template for deployment, which requires persistent storage and a provisioned storage class in my EKS cluster.
The aws-ebs-csi-driver is required to make this work and is easily missed if you are not familiar with EKS. This driver is responsible for managing the lifecycle of EBS volumes for persistent storage.
To setup the aws-ebs-csi-driver we'll create a role and install an add-on in the cluster. To create the role, I'll let the good folks at Amazon take you through step by step.
Once the role is ready, head over to the EKS console and select the cluster. Click Add-ons -> Add new then select Amazon EBS CSI Driver and the role you just created for the Service account role and click Add.
Once the add-on is installed, follow through the rest of the operator setup (it's actually super easy!) and you should be rocking an Aerospike cluster in no time!
What would I do different?
Take the time to learn eksctl and use the AWS CLI more.
These tools take you out of the Management Console and can simplify a lot of the setup. That said, I learn by making mistakes, and I find that it's a lot easier to see my mistakes in the Management Console. Your mileage may vary.
What's next
Keep your eyes peeled for the next installation of this harrowing journey, where we'll talk data modeling and (hopefully) set things up right. Then, maybe we can get into storing and accessing said data, and who knows what else. This project is here to be overdesigned to our hearts content. Let's play around a little.
Check out our docs and our Developer Hub for more great Aerospike content and an interactive sandbox to mess with.



