
When to Choose and How to Effectively Use JEMalloc
When a customer’s business really starts gaining traction and their web traffic ramps up in production, they know to expect increased server resource load. But what do you do when memory usage still keeps on growing beyond all expectations? Have you found a memory leak in the server? Or else is memory perhaps being lost due to fragmentation? While you may be able to throw hardware at the problem for a while, DRAM is expensive, and real machines do have finite address space.
At Aerospike, we have encountered these scenarios along with our customers as they continue to press through the frontiers of high scalability. This article focuses specifically on our techniques for combating memory fragmentation, first by understanding the problem, then by choosing the best dynamic memory allocator for the problem, and finally by strategically integrating the allocator into our database server codebase to take best advantage of the life-cycles of transient and persistent data objects in a heavily multi-threaded environment.
Aerospike Principal Engineer, Psi Mankoski, has published an article in High Scalability describing effective use of JEMalloc in Aerospike, and how after over a year in production, the new algorithms have shown substantially better memory management and reliability for customers operating Aerospike at scale. Many of these deployment run from 500k TPS to well over several million TPS.
JEMalloc was initially created in 2003 by Jason Evans, now a Software Engineer at Facebook. JEMalloc provides a superior mechanism for fast allocation and deallocation of memory, and minimizing fragmentation. It was formally described in a white paper published for FreeBSD in 2006. In 2009, it also added support for heap profiling and was ported to Linux.
Memory management has always been a critical issue of computer architectures. In cases where automatic memory management has been implemented, issues of performance degradation during “Garbage Collection” (GC) have been found to be a major problem, such as in Java-based systems. However in manual memory management, application-specific code may introduce memory leaks created by failure to successfully release data objects. Linux’ OOM Killer can be especially prejudicial in its termination of offending processes — this can result in lost data.
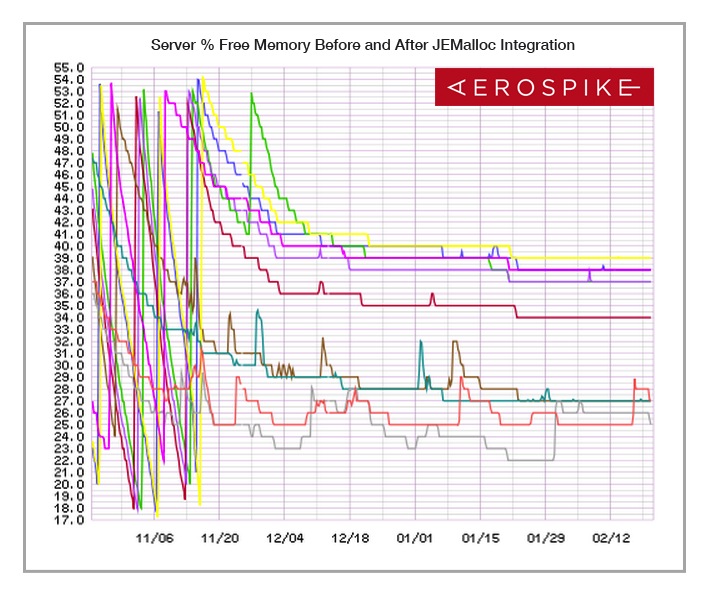
The Graphite image above shows the system free memory (vertical axis = % free memory) on the individual nodes of an actual 14-node Aerospike database cluster in production over a 4 month period (horizontal axis = time), both before and after implementing the techniques discussed in this paper. Each server node had an 8-core Intel Xeon E5-2690 CPU @ 2.90GHz running the CentOS 6 GNU/Linux operating system and was provisioned with 192 GB of RAM. The steep downward curves on the left hand side, the “before” case, show the inexorable trend of memory exhaustion, which was shown to be due to main memory fragmentation. After selecting a better dynamic memory allocator and changing the server to use the allocator effectively in a multi-threaded context, the system memory use per node quickly “flatlines” on the right side (with some residual “bouncing” as memory as additional memory is transiently allocated and given back to the system.)
Even without memory leaks, poor memory allocation techniques can result in fragmentation, resulting in poor application performance and application failure.
In his article, Psi describes the advantages of JEMalloc over GLibC’s malloc implementation (PTMalloc2). He highlights JEMalloc’s strengths in terms of debuggability, memory usage control, and taking maximum advantage of modern multi-CPU, multi-core, multithreaded system architectures. The resulting implementation in Aerospike optimized memory utilization and substantially reduced fragmentation using JEMalloc extensions to create and manage per-thread (private) and per-namespace (shared) memory arenas.
Read the full blog post on High Scalability.



