Blog
In this post, we will show how Aerospike features enable Microservices architecture. Specifically, we will see how separation, coordination, and consistency among services is supported.
Database requirements for microservices
Microservices based architecture represents the state-of-the-art in building large complex systems, in which high level business functionality is delivered through cooperating but loosely coupled microservices that are independently developed and deployed. Microservices allow parallel development, contain complexity and therefore deliver greater productivity and reliability.
Data architecture is a challenging aspect of microservice design. The single database of the monolithic architecture must be split into multiple subsets each controlled by a service (service will be used synonymously with microservice in this post) and residing in a database best suited for the needs of the service. While isolated from each other, services still must be able to coordinate with each other to deliver the required capabilities and maintain data consistency.
Therefore, a database should make it easy to maintain isolation, design data effectively, coordinate across services, and maintain data consistency. Issues surrounding microservices data architecture and consistency are discussed broadly elsewhere, for example, here and here.We will examine how Aerospike supports the following aspects of Microservices architecture with a focus on the third:
Control of data
Design of data
Coordination and consistency across services
Aerospike data model
Aerospike is a distributed key-value database (with support for the document-oriented data model) that supports multiple namespaces (database or schema) holding multiple sets (tables). A namespace is partitioned (sharded) across a cluster of nodes with the desired replication factor. Data is stored as records (rows) that are accessed using a unique key. A record can contain one or more bins (columns) of different data types.
Enabling control of data
At the database level, it is important to keep the data squarely under each service’s (and team’s) control. “One database or schema per service” encapsulates this goal. Aerospike allows the flexibility for services to store and control their data in:
separate namespaces in the same or different clusters, or
separate sets in the same or different namespaces
To preserve separation and control of data, Aerospike enforces role based access in which a role has associated privileges, and a privilege defines a permission such as read, write, and admin, over a scope such as global, namespace, or set. By ensuring that roles with right privileges over the service’s namespace or sets are assigned only to the service and appropriate team members, the desired separation and control over the data is achieved. Details of Aerospike role-based access can be found here.
Enabling design of data
Aerospike provides transactional guarantees for single record requests. A service can eliminate or minimize the need for multi-record transactions by taking advantage of Aerospike’s rich data model that includes nested List and Map types, and its multi-operation single record transactions. With appropriate data modeling, multi-record transactions requiring joins and constraints can be avoided. For instance, data in multiple tables in a relational database may be modeled as a single denormalized record. The data modeling techniques for service design are covered in these blog posts.
Enabling coordination and consistency across services
Different service deployment options are possible with Aerospike. Some services may share the same Aerospike cluster, others may be deployed on different clusters, and still others may use different databases. Multiple services can use the same Aerospike cluster for convenience of administration and operation as a single Aerospike cluster can scale to petabyte size while delivering a predictable sub-millisecond performance, high resilience, and flexible trade-off between availability and consistency at a namespace level. Services may be deployed on different clusters for greater flexibility of distribution and scaling. Aerospike’s Cross Data Replication (XDR) makes it convenient to replicate a namespace across multiple clusters. The following diagram shows the various deployment options with services A, B, C, and D.Services A, B, C, and D using different database deployments and event bus for coordination.
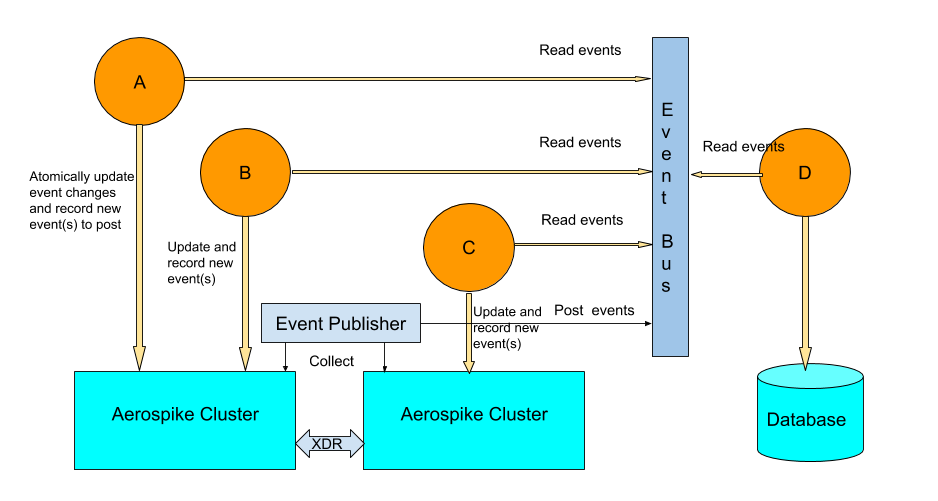
Service deployment options and events based architecture
Event based coordination
Event (or message) oriented coordination allows loose coupling between services: Events of interest are produced by a publisher service and consumed by one or more subscriber services. In order to guarantee (eventual) consistency among services, all events must be processed exactly once. Below, we will describe how this can be done in Aerospike through a combination of events being published at-least-once by the publisher service and being processed idempotently by the consumer service.
Multi-service transaction model
Transactions spanning multiple services are often necessary, and in such cases a sequence of service level transactions is used. Each service processes its part of the transaction by making the corresponding change in its database and posting an event for the subsequent service. If there is failure and the entire sequence has to be reversed, a series of reverse compensating transactions must be performed by posting appropriate events in the reverse order. The diagram below shows a transaction sequence spanning services A, B, C, and D, and an event E propagates through them. Note a service reads an event from and posts an event to different queues or topics.
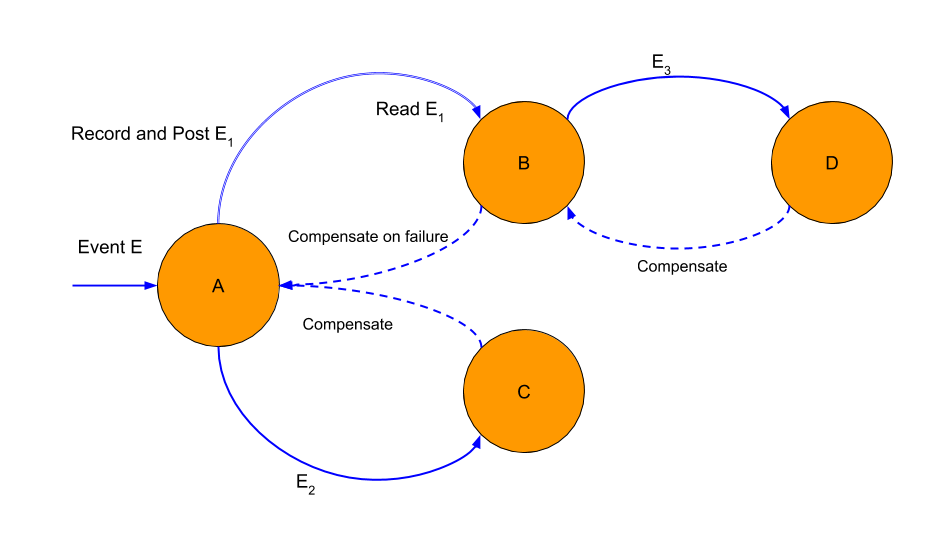
A transaction sequence for event E with services A, B, C, and D
Consumer-publisher pattern
Each stage in a transaction sequence can be generalized as a combination of a consumer and a publisher. A service:
As a consumer, reads an event published by the previous stage and processes it in an idempotent fashion.
As a publisher, may record a new event to publish to the appropriate topic (including in case of a failure, as a compensating request). This must be done atomically with updates in Step 1.
An external long-running Publisher process is responsible for collecting and posting to the event bus all recorded events with “at-least-once” guarantee.Viewed from the perspective of an event, an event is processed in the following steps:
A service reads the event from an event bus topic.
The service processes the event and updates the database.
Atomically with Step 2, the service records any new event(s) to publish to an appropriate topic.
A separate Publisher process collects all events to publish from Step 3 and posts them to respective topics on the event bus.
Consumer and publisher parts of a service as well as the Publisher process are illustrated below with pseudo-code.
Service schema
In addition to the bins to store service data, a service record has to include two additional bins:
Processed Events map: For idempotent processing of potential duplicate events, this event_id -> timestamp map has an entry for every event_id that has been processed.
Events To Publish map: For atomic recording of new events to publish, this event_id -> event_data map holds an entry for every new event_id that is to be published as a result of processing an event.
Service schema
How these fields are used is described in the following sections.
Consumer service pattern
Processing of an event takes place in the following two steps in a consumer service:
Determine the service data change: In this step, the service would read the service data with a predicate filter to check that the event is not already processed (that is, the event-id does not exist in processed-events map), and make appropriate modifications,
Atomically write the service data change and processed event: In this step, the service would write the data with the GEN-EQUAL check to ensure the data has not changed and the write is still valid (please refer to the details of the Read-Modify-Write or RMW pattern in this post), and record the event-id in processed-events map. Insertion of event-id key in the processed-events map will fail with FiteredOut exception if the event is already processed and therefore its event-id exists in the map.
The following pseudo-code illustrates this implementation approach.Note the single record multi-operation request operate() is executed atomically.
Pseudo-code for consumer service pattern
A service will periodically remove events from processed_events bin that have a timestamp older than a safe (long) duration.
Publisher service pattern
A service that wants to publish a new event in order to coordinate processing with consumer services will have the following additional logic:
Determine the event and associated data to publish: In addition to the core data such as event-id, timestamp, and topic, other data needed for downstream processing will need to be included.
Atomically record the new event to publish with the service data update as part of processEvent().
Pseudo-code for publisher service pattern
The Publisher process
The Publisher process ensures all events are published at-least-once while trying to avoid publishing an event more than once. Stricter requirements for event ordering can be handled by a service’s reader logic, for instance, by buffering events for some duration before processing them in order, and also dealing with out-of-order events.
A possible implementation would involve a service registering these two functions with the Publisher process: collect() and remove().
collect():
Scan from events-to-publish bin and return some or all events
remove():
Remove from events-to-publish bin the specified list of eventsThe Publisher process repeatedly executes this sequence:
Get a service’s unpublished events by calling collect(),
Post the events to the event bus,
Remove them from the service by calling remove().
Event publisher process
The possibility of multiple posts of an event arises because the Publisher process can fail anywhere during collect(), post, and remove() sequence. Because the sequence is not atomic, the Publisher process must process all events in a service’s unpublished list when it restarts after a failure, even though some of the events may already have been posted but not removed at the time of the failure.
Alternative event bus implementations
Standard event bus implementations include Kafka, JMS, and Pulsar. The event bus can also be implemented on top of Aerospike. It is possible for a service to also register process() with the Publisher for “in-line” (without posting to or reading from the event bus) processing of an event.
process():
Process the event with the same logic as processEvent() aboveSuch in-line event processing may make sense for multi-record transactions within a service. Publisher and subscribers services can reside on different clusters, in which case Aerospike’s Cross Datacenter Replication (XDR) enables a multi-cluster event bus. The details are beyond the scope of this post, and may be explored in a future post.
Conclusion
Microservices architecture requires that a database make it easy to maintain isolation, design data effectively, coordinate across services, and maintain data consistency. In this post, we showed how Aerospike supports control and design of data, and especially coordination and consistency across services. We examined an event based architecture for multi-service transactions, and illustrated with pseudo-code a general consumer-publisher service pattern.
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog