Blog

This is the first in a series of articles describing a simplified example of near real-time Ad Campaign reporting on a fixed set of campaign dimensions usually displayed for analysis in a user interface. The solution presented in this series relies on Kafka, Aerospike’s edge-to-core data pipeline technology, and Apollo GraphQL
Part 1: real-time capture of Ad events via Aerospike edge datastore and Kafka messaging.
Part 2: aggregation and reduction of Ad events via Aerospike Complex Data Type (CDT) operations into actionable Ad Campaign Key Performance Indicators (KPIs).
Part 3: describes how an Ad Campaign user interface displays those KPIs using GraphQL retrieve data stored in an Aerospike Cluster.

This article, the code samples, and the example solution are entirely my own work and not endorsed by Aerospike. The code is available to anyone under the MIT License.
The use case — Part 1
A simplified use case for Part 1 here consists of capturing Ad events from Publishers, Advertisers and Vendors in an Aerospike edge datastore and publishing via Kafka
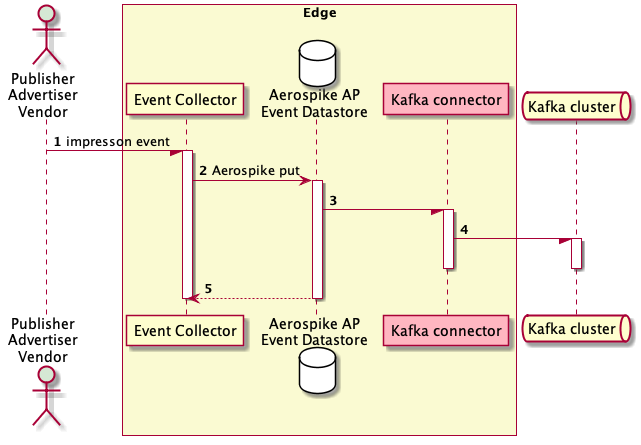
Impression sequence
Companion code
The companion code is in GitHub. The complete solution is in the ‘master’ branch. The code for this article is in the ‘part-1’ branch.Javascript and Node.js is used in each service although the same solution is possible in any languageThe solution consists of:
A Publisher Simulator — Node.js
An Event Collector service — Node.js
Aerospike configurations enabling Kafka
Docker compose yml
Docker containers for:
Aerospike Enterprise Edition (https://dockr.ly/2KZ6EUH) Zookeeper (https://dockr.ly/2KZgaaw) Kafka (https://dockr.ly/2L4NwVA) Kafka CLI (https://dockr.ly/2KXYEn4)
Docker and Docker Compose simplify the setup to allow you to focus on the Aerospike specific code and configuration.
What you need for the setup
Aerospike Enterprise Edition
An Aerospike user name and password
An Aerospike Feature Key File
from Aerospike Support containing features:
sdb-change-notification
asdb-strong-consistency
mesg-kafka-connectorDocker and Docker Compose
Setup steps
To set up the solution, follow these steps. Because executable images are built by downloading resources, be aware that the time to download and build the software depends on your internet bandwidth and your computer.1. Clone the GitHub repository with one of the following options• To get the whole repository use:
$ git clone https://github.com/helipilot50/real-time-reporting-aerospike-kafka
$ cd real-time-reporting-aerospike-kafka
$ git checkout part-1
To get part-1 only use:
$ git clone --single-branch --branch part-1 https://github.com/helipilot50/real-time-reporting-aerospike-kafka
2. Edit the file docker-compose.yml and add you Aerospike customer user name and password

3. Copy your Feature Key File to project etc directory for the Edge and Core datastore; and to the edge exporter:
$ cp ~/features.conf /aerospike/edge/etc/aerospike/features.conf
$ cp ~/features.conf /aerospike/core/etc/aerospike/features.conf
$ cp ~/features.conf /edge-exporter/features.conf4. Then run
$ docker-compose up
Once up and running, after the services have stabilized, you will see the output in the console similar to this:
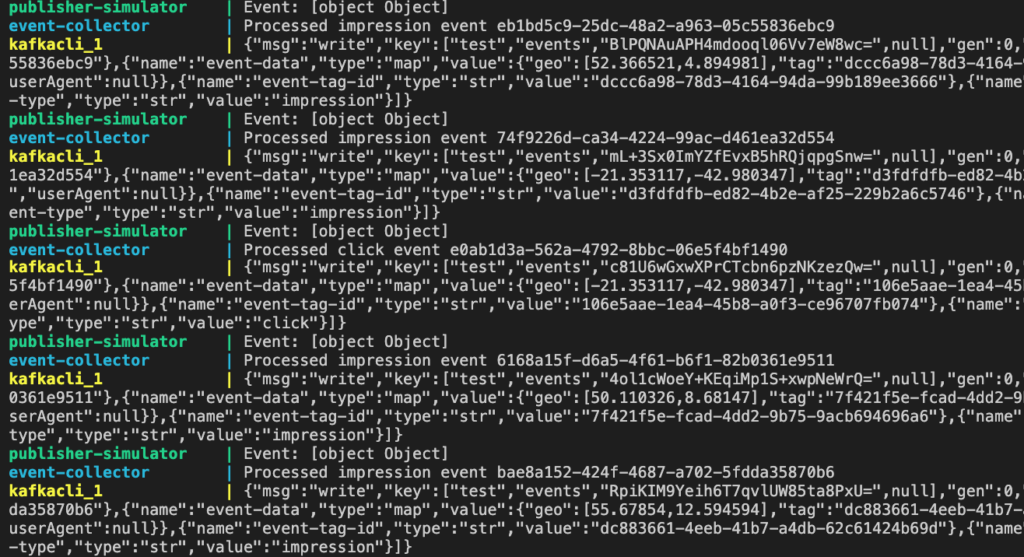
Sample console output
How do the components interact?
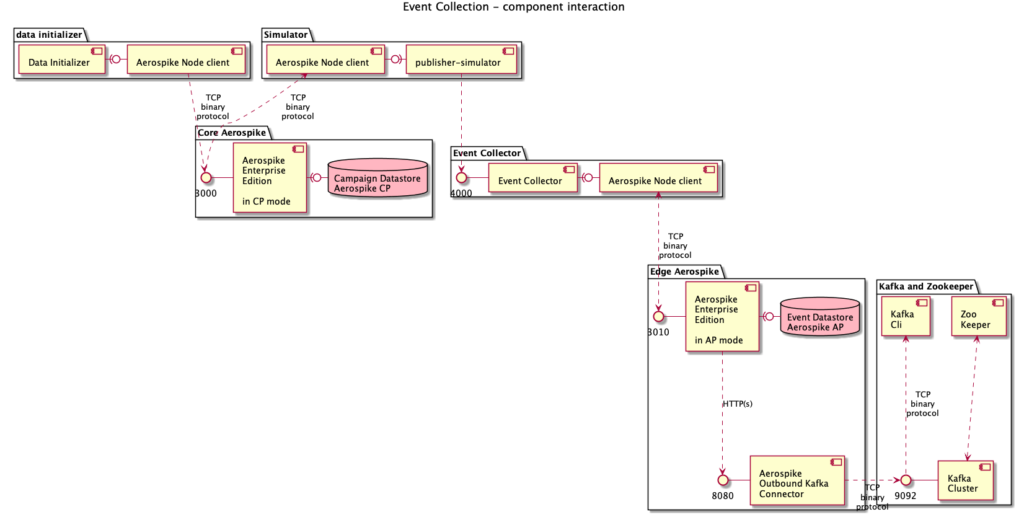
Component Interaction
Docker Compose orchestrates the creation of several services in separate containers:
Zookeeper zookeeper — a single instance of Zookeeper to maintain the naming and configuration for Kafka (and other things)
Kafka kafka — a single node Kafka cluster
Kafka CLI kafkacli — Kafka C is used to view the messages in the Kafka topic
Aerospike Edge edge-aerospikedb — a single node Aerospike Enterprise cluster in Availability Mode. Availability is important to ensure every event is captured in real-time. The Dockerfile and other files for the Aerospike Enterprise server is located in the edge-aerospike directory. This container also mounts four volumes at runtime.
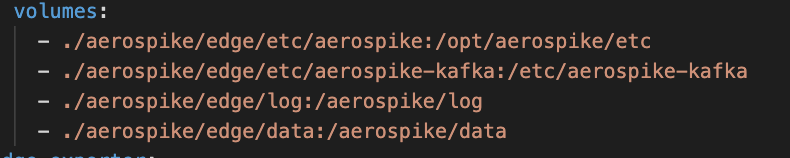
Edge container volume mounts
Aerospike Core core-aerospikedb — a single node Aerospike Enterprise cluster in Strong Consistency mode. Consistency is necessary as Campaign KPIs are used for payment a.k.a they represent money. The Dockerfile and other files for the Aerospike Enterprise server is located in the core-aerospike directory. This container also mounts three volumes at runtime.

Core container volume mounts
Edge Exporter edge-exporter — A single instance of the Aerospike Kafka Connector service. The edge-exporter directory contains the Dockerfile and feature.conf that define the connector service. This container also mounts two volumes at runtime

Kafka Connector volume mounts
Data Initializer data-initializer — A node.js program to initialize Campaign data and Tags in the core data store.
It runs briefly at the start of the docker-compose sequence, checks for data, writes sample data if none exist, and then terminates.
Publisher Simulator publisher-simulator — A Node.js program that produces random events to simulate the activity of publishers, advertisers and vendors. Each event is decorated with simulated Geo and User-agent data.
These events are generated with a completely contrived ratio and serve as an example only. In the real world, most events are impressions, with one click for every thousand impressions and one conversion in fifty clicks.
The publisher-simulator directory contains the simple node source, package.json and the Dockerfile.
Event Collector event-collector — A node.js REST API service implemented using Express. This service is a simple API that receives an Event from a Tag via a POST request and stores the event data in the edge datastore. The event-collector directory contains the node source, package.json and the Dockerfile.
Both the Event Collector and the Publisher Simulator use the Aerospike Node.js client. On the first build, both containers download and compile the supporting C library. The Dockerfile for both containers uses a multi-stage build that minimises the number of times the C library is compiled.
How is the solution deployed?
Each container is deployed using docker-compose on your local machine.
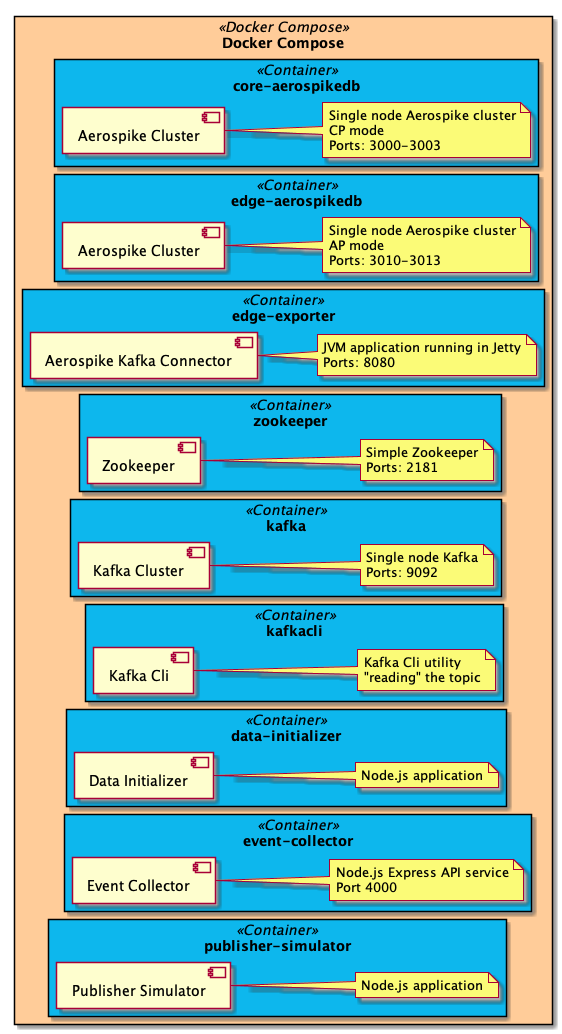
Deployment
How does the solution work?
Connecting to Aerospike
The code to connect to an Aerospike Cluster is similar in each component. You provide one or more address and ports in an array to the Aerospike.connect() method.
console.log('Attempting to connect to Aerospike cluster', asHost, asPort);Connecting to Aerospike
The Aerospike client iterates through the array of IP addresses and ports until it successfully connects to a node. It then discovers all nodes in the cluster.
Data initializer
The data initializer creates 100 Campaigns with 1000 Tags per Campaign in the Core datastore. This forms the basic data for the entire simulation.
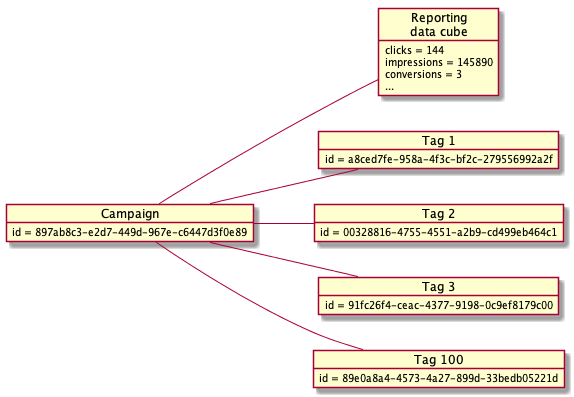
Data model
Campaigns are created with an Aerospike simple put operation with Bins representing the indexable fields of a Campaign and a Complex Data Type (CDT) is initialized to form an elementary data cube for KPIs.
Campaign data
For each Campaign, one thousand Tags are created. A Tag is actually JavaScript tag added to a web page to reference the Creative and provide Ad events. Tags have unique Ids and are related to a Campaign via an Execution Plan. In this example, a Tag record is created with a reference to the Campaign.
Tag to Campaign mapping
For the simulator to send events with valid Tags, Aerospike is used as an associative array allowing an index lookup to retrieve a Tag Id, with a simple numeric index referencing the Tag Id.
Indexing Tags with a numeric key
Publisher Simulator
The Publisher Simulator emits an Ad event on a defined interval to simulate the action of people interacting with an Ad. The interval between events deliberately large so we can see the whole sequence.
Every interval, the simulator:
Creates a random event
Reads a random Tag from the Campaign data stored in Aerospike
Simulates the Publisher/Advertiser/Vendor id
Sends the event to the event collector
Creating random event types with a known set of Tags
This simulator can be scaled up by changing the interval and running multiple containers.
Event collector
The Event Collector is a Web API implemented with Express.
Each event type has a specific route where the user agent is added to the body of the message and the writeEvent() method is called passing the body of the message.
Web API using Express
Events are received from the Publisher/Vendor/Advertiser and stored in an Aerospike edge data store. This store acts as high availability and low latency buffer between the event collector and Kafka.
The raw event is classified by assigning some elements of the event to Bins and then stored using a put operation.
Storing events in Aerospike
Edge Exporter
The Edge Exporter is the Aerospike outbound Kafka connector running in a container. Each time a record is written to Aerospike it is exported to Kafka based on setting in the aerospike.conf file on each node in the Aerospike cluster.
aerospike.conf
To enable Aerospike to export to Kafka, a features.conf file is required to be available to both the Aerospike Kafka Connector and the Aerospike Cluster.
features.conf
Scaling the solution
How fast will it be? —This depends on the technology and hardware used.
Ad Event data is captured in real-time in the edge Aerospike cluster. Aerospike scales horizontally by adding nodes to the cluster. In fact, Aerospike’s ability to scale is one of its most powerful features. Likewise, Kafka is also designed to scale easily. Both technologies have extensive documentation and guides on scaling for throughput, latency, availability and capacity.
Aerospike and Kafka go hand-in-glove. Some of the benefits of Aerospike as a front-end to Kafka are as follows:
Aerospike gives you a high-throughput, low-latency, datastore configurable to prioritise high-availability or strong consistency at a lower TOC with Flash memorySSDs.
Ad Event data is captured in real-time, so Kafka service needs less capacity than otherwise.
Ad Events are log-level data stored in Aerospike. These data can thus be used for even more analytics with the Aerospike Spark Connector or other analytics tools.
The Aerospike Kafka Connector runs in the Jetty web server, and can be “Dockerized” and scaled like any other microservice.
For microservices in Docker containers, Kubernetes is my favourite way to orchestrate for production with excellent autoscaling and high availability features and several CI/CD tools integrate directly with it.
Orchestration with Kubernetes and tools like Drone and Helm Charts, enables your Developers to focus on development, and your DevOps not to hate the Developers.
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog