Blog

概要
このブログでは、Aerospike 3.8.2.3とCassandra 3.5.0の2つのNoSQLデータベースを、昨今のインターネット・アプリケーションに典型的な、読み込み・書き込みが混在する負荷環境下で実施した12時間のベンチマークの結果をまとめています。このベンチマークでは、YCSB (Yahoo! Cloud Serving Benchmark)を採用し、この結果を再現できるように、詳細な情報をご呈示しています。
その結果、Cassandraに比べ、Aerospikeはスループットが14倍、読み込みのレイテンシが42分の1、書き込みのレイテンシが24分の1(共に95パーセンタイル)を達成しました。
Aerospikeのパフォーマンスが高いということは、Cassandraに比べて少ないサーバ台数で対応できることを意味し、プロジェクトに必要なハードウエア費用と保守費用を大幅に低減できます。サーバ台数が少ないということは、ラック面積の削減にも繋がります。言い換えると、同数のサーバによるクラスタでは、AerospikeはCassandraに比べて14倍のリクエストを扱うことができるということです。
はじめに
オペレーショナル・データベースやNoSQLデータベースのベンチマークは数多くありますが、そのほとんどが非常に短い時間(通常、一時間に満たない)で実施されたものです。Aerospikeは、そのデータベース・マニフェストにおいて、短時間の小規模なテストの問題点を指摘し、十分な時間をかけてベンチマークを行うことを提案しています。今回、AerospikeとCassandraの各々のオープンソース版に対し、12時間のベンチマークを行いました。サーバとして、データセンタに使われるような、Xeonプロセッサ、32GBのメモリ、SSDとしてIntel S3700、10GbEネットワークを使用しました。
全てのデータベースは、長期に渡る健全性を確保するため、定期的なバックグラウンド・タスクが走ります。しかしながら、そのようなタスクは、リソースを使い、その結果、パフォーマンスの低下を引き起こします。そのようなタスクを特定の負荷のために注意深くチューニングしたり、あるいは、停止させたりすることにより、より良い結果を得ることができるかもしれません。しかしながら、そのような設定では、長期間に渡る継続的な運用は難しいでしょう。このベンチマークでは、両データベースを各々、開発元であるAerospike社と、Apache Cassandraの商用ベンダの一つであるDatastax社の各々から公表されている方法に基づき設定し、12時間に渡ってベンチマークを実施しました。
このブログで最も重要なのは、このベンチマークの結果を再現できるように、非常に詳細な説明をしていることです。そこでは、Aerospike、Cassandra、YCSBのインストール方法や設定方法を記載しています。その目的は、どなたでもこのベンチマークを容易に再現できることですが、さらには、今回の設定方法に対する批評ができること、個々のプロジェクトに応じた負荷を試せること、異なるハードウエア環境でベンチマークを行えることを目指しています。
ベンチマークの結果には、大きな差がありました。AerospikeはCassandraに比べて14倍のスループット(図1)をたたき出しています。また、Aerospikeのレイテンシは、Cassandraに比べて、読み込みの95パーセンタイル値が42分の1、更新の95パーセンタイル値が24分の1であることがわかります(図2)。
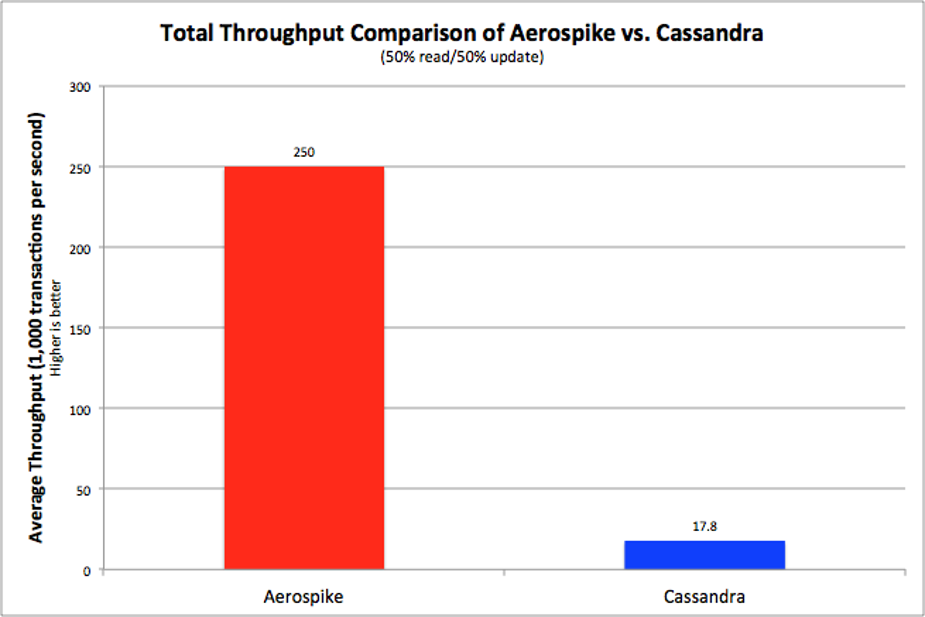
図1. スループットの比較(高い方が良い)
図2. レイテンシ(95パーセンタイル値)の比較(低い方が良い)
後述しますが、Aerospikeはスループットとレイテンシが非常に良いということだけではなく、そのバラツキが非常に少ないことにご注目ください。即ち、あるリクエストに対し、より一貫性が高く、そのレスポンスがどの程度の時間で返ってくるのかを予想できるということです。これは、アプリケーション開発者や運用者にとり、非常に重要な特性と言えます。
The Yahoo! Cloud Serving Benchmark (YCSB)
YCSB (The Yahoo! Cloud Serving Benchmark) は、その名の通り、元々はYahoo!で開発され、NoSQLデータベースのパフォーマンス測定のためのベンチマーク・ツールとして広く知られ、高い評価を得ているものです。その機能、それが発生させる負荷、それをサポートする製品の拡張に対し、コミュニティからの多くの貢献があります。
AerospikeとCassandraの双方とも、インターネット向けのシステムにかかる負荷を模擬できるYCSBに対応した機能を有しています。ベンチマークは2つフェーズに分かれています:データをロードすることと負荷をかけることです。その両方とも、YCSBはスループット、レイテンシ、その他の統計量を測定できます。
公平な比較ができるように、ベンダのベストプラクティスを用いて設定を行い、同じハードウエア上で、種々の負荷の下、最低12時間の測定を行っています。
YCSBの設定方法
今回のベンチマークでは、YCSBのリクエスト分散方式として、Zipfianではなく、様々な読み込み・書き込みの負荷を発生できるuniform(デフォルト)を採用しました。これは、Zipfian分散では、かなりの処理(多くの場合、80%)がストレージではなく、DRAMのキャッシュで行われるため、配下のインフラストラクチャのパフォーマンス性質を隠してしまうためです。一方、uniform分散では、より多くの処理がストレージにアクセスするため、ベンチマーク対象の両データベースのアーキテクチャや実装コードの効率性に、より焦点が当たったものになります。
ストレージの有効利用はシステムの効率性の観点から非常に重要であるため、DRAMに入りきらないデータを使うようにYCSBを設定しました。これにより、ストレージがシステム全体のパフォーマンスに影響を及ぼすようになります。
読み込み・書き込みが同じデータ・ストアに対して実行されるように、読み取り・書き込みが混在する負荷とすべく、それらを50:50に設定し、ロック、同時処理、並列処理による影響があるようにしました。
ベンチマークは12時間、連続稼働させ、測定を行いました。その目的は、開始直後のピーク・パフォーマンスを評価するのではなく、ディスクのデフラグメンテーション、ギャベージ・コレクション、圧縮等の定期的なバックグラウンド管理プロセスが走るだけの十分な時間、システムを稼働させることにより、システムの真のパフォーマンスを把握するためです。実際、これらのプロセスは、システムのスループットとレイテンシに対して影響を及ぼします。レイテンシを平均値や合計値のみで評価することは、時間に関する情報が含まれないことから、評価に十分な指標とは言えません。そこで、YCSBにレイテンシのヒストグラムを測定できるように機能追加を行いました。この指標に関し、YCSBの拡張として、正式なYCSBレポジトリに対するプル・リクエスト#753を提出しました。これは、システムのレイテンシを詳細に理解するために重要であり、YCSBの利用をより活発にするものと信じています。
YCSBの詳細な設定方法、稼働方法については、“Recreating the Benchmark – Aerospike and Cassandra: Benchmarking for Real”にて詳細に説明しています。
サーバ当たりのDRAM搭載量
今回のベンチマークにあたり、サーバにどの程度のDRAMを載せるのかに悩みました。Cassandraのすべてのチューニング・パラメータと無数の使用可能なハードウエア構成を確かめましたが、DRAM量については確信が持てませんでした。Cassandra WikiのCassandra Hardwareページでは、少なくともサーバ当たり8GBから16GBを推奨しています。一方、Datastax社のCassandra Planningページでは、より多くのDRAMは特に行のキャッシュの効果が読み込み時にあるため、16GBから64GBを推奨しています。総合して、32GBは良い出発点と考えました。
重要 – メジャー圧縮は有効にしていません
今回のベンチマークを通して、可能な限り、同じハードウエアを使い、同様の設定をすることに注力しましたが、完全に調整できなかった大きな違いがありました。それは、Cassandraにおけるメジャー圧縮です。ただし、これを使うことにより、さらにCassandraのパフォーマンスを低下させることになります。
Cassandraのチューニングの多くは、マイナー圧縮の設定に関するものでした。このマイナー圧縮は、頻度高く(数分毎)実行されるので、12時間のベンチマークの中で必然的に発生します。しかしながら、本当に公平な比較をするために、メジャー圧縮の影響を考慮する必要がありますが、通常、この圧縮は毎週といった頻度で実行されます。実際のベンチマークを行うにあたり、メジャー圧縮を入れることはしませんでした。ただし、このメジャー圧縮が実行されることにより、Cassandraのスループットとレイテンシの値はさらに悪くなることにご留意ください。
Aerospikeは、メジャー圧縮・マイナー圧縮という概念はありません。代わりに、デフラグメンテーションと呼ぶ圧縮機能がベンチマーク中に連続的に走っています。
ベンチマーク条件
適切なユースケースを想定し、いくつかのフェーズにてベンチマークを実行しました。
データとパラメータを以下に設定。
4億件のユニーク・レコード
1レコードあたり、100バイトのフィールドが10個(計1,000バイト)
リプリケーション・ファクタ:2(マスタとそのレプリカ)
強い整合性
ベンチマークのパラメータに従い、ハードウエアを選択。
必要なツールのインストール(例えば、NTP、iostat、dstat、htop等)。
3台のサーバを推奨設定にて構成し、クラスタが正常に動作することを確認。
用意したサーバで最適なパフォーマンスを得るように、各データベースを設定。短時間(10分)稼働させ、正常に動作することを確認。推奨設定については、下記リファレンスを参照。
4億件のレコードを挿入。
Cassandraのみ:圧縮が終了し、初期準備段階が終了するのを待つ。圧縮終了までの時間(72分)のため、準備段階の時間は2時間48分から4時間に長期化。
OSのファイルシステムのキャッシュを消去(Cassandraのみ;Aerospikeはファイルシステムを使用しないため)。
12時間、負荷をかける。
データ収集、グラフの作成、結果の解析。
両データベースとも、ステップ5〜9を繰り返す。
結果
概要
得られた結果は、大きな差がありました。表1は、その結果と2つのデータベースの値の比率です。
表1. 結果のまとめ
表1の最終行は、AerospikeのCassandraに対する相対値です。即ち、どの指標に関しても、Aerospikeが明らかに高パフォーマンスであることを示しています。
データのロード時間(データ挿入率)
ベンチマークの実行の際に、AerospikeとCassandraでは、データのロード時間に顕著な差がありました。それゆえ、実行準備の総時間を両データベースで比較することにしました。その結果を、表2と図3にまとめました。
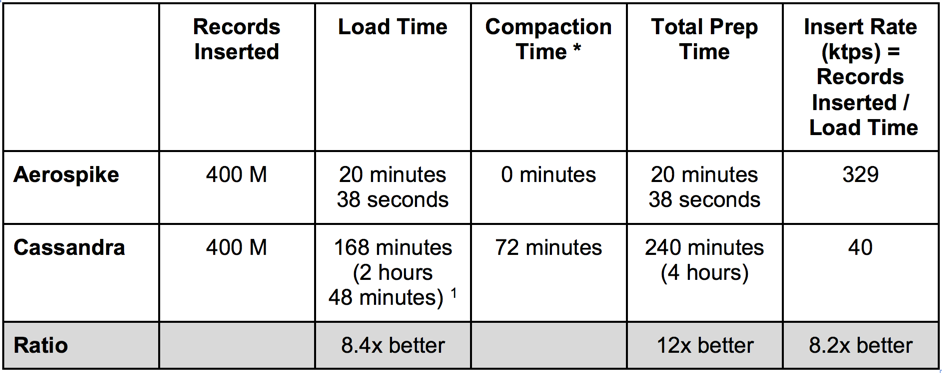
表2. データ挿入率
Aerospikeのデータ挿入率は、Cassandraの8倍以上となりました。この値は、負荷が無い状態で、YCSBのデータのロード時、即ち、書き込みが100%の状態で測定しました。Cassandraの圧縮を考慮すると、両データベースのパフォーマンスの差はさらに広がり、12倍となります。Cassandraは書き込み速度が高いことで有名ですが、上記のように、Aerospikeは、圧縮が落ち着くまでの時間も必要なく、同じ量のデータを著しく速くロードできます。
図3. データ挿入率の比較(高いほど良い)
読み込み時の結果:スループットとレイテンシ
ベンチマークの際は、読み込みと書き込みを混在させた負荷をかけています。その結果として、同じハードウエアで動作させたAerospikeとCassandraは、平均して、前者が14倍の読み取りスループットを達成しています(図4参照)。また、注目していただきたいのは、そのバラツキがAerospike(赤い線)では無視できる程度であるのに対し、Cassandra(青い線)では非常に大きいことです。
図4. 読み取り時のスループット(高いほど良い)
Aerospikeは、スループットが高いのにも関わらず、レイテンシは低くなっています。多くのユース・ケースでは、バラツキが少ない、即ち、レスポンス時間が予想できることは非常に重要です。図5は、95パーセンタイルでのレイテンシをを示したものですが、Aerospikeは、42分の1という圧倒的に低いレイテンシとなっているだけではなく、バラツキが非常に少ないレスポンス(赤い線)を返していることが分かります。
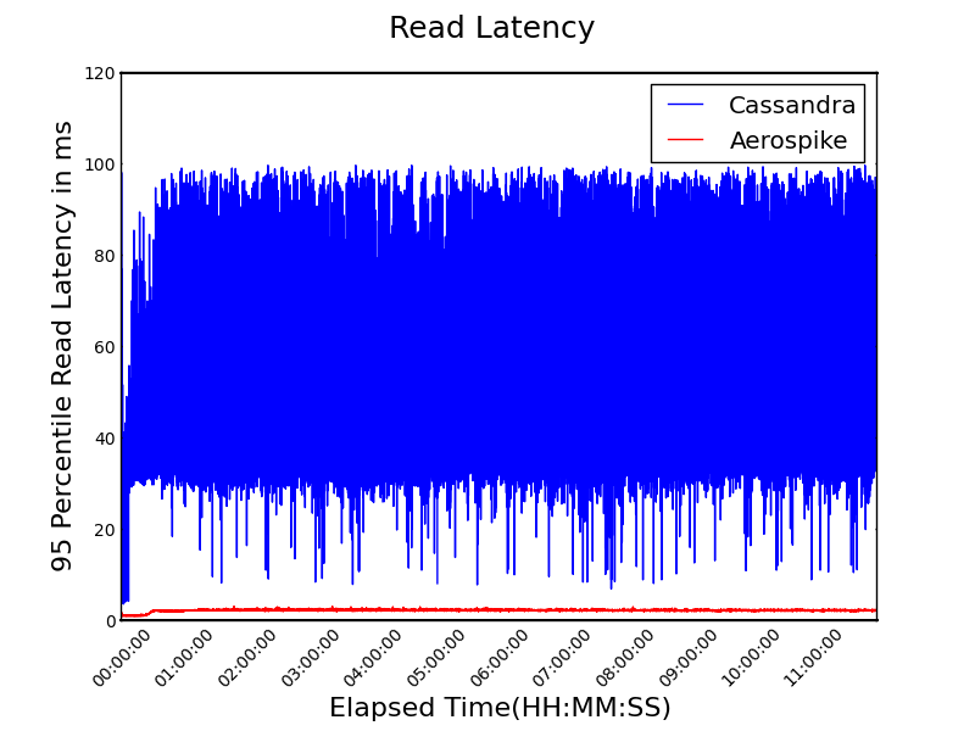
図5. 95パーセンタイルでの読み込みレイテンシ(低いほど良い)
対照的に、Cassandraは、単に平均レイテンシが42倍ということだけではなく、そのレスポンス時間の高低の差(バラツキ)が非常に大きいということです。これでは、どの程度のレスポンス時間を想定したら良いのか分かりません。
開始後30分程度の間、両データベースともレイテンシが増加しています。Aerospikeにおけるレイテンシの増加は、SSD上におけるギャベージ・コレクションであるデフラグメンテーションが発生し始めているためです。Cassandraに関しては、確証があるわけではありませんが、たぶん、圧縮等のバックグラウンドのプロセスに依るものと思われます。
更新時の結果:スループットとレイテンシ
読み込みと書き込みが混在する負荷の下、更新のパフォーマンスも検討しました。プロセス配下に存在する読み込みと書き込みの競合により、スループットの低下とレイテンシの増加が想定されます。しかしながら、AerospikeはCassandraに比べて、平均スループットで14倍(図6)、平均レイテンシで24分の1(図7)を達成し、その実装の効率性を証明しています。
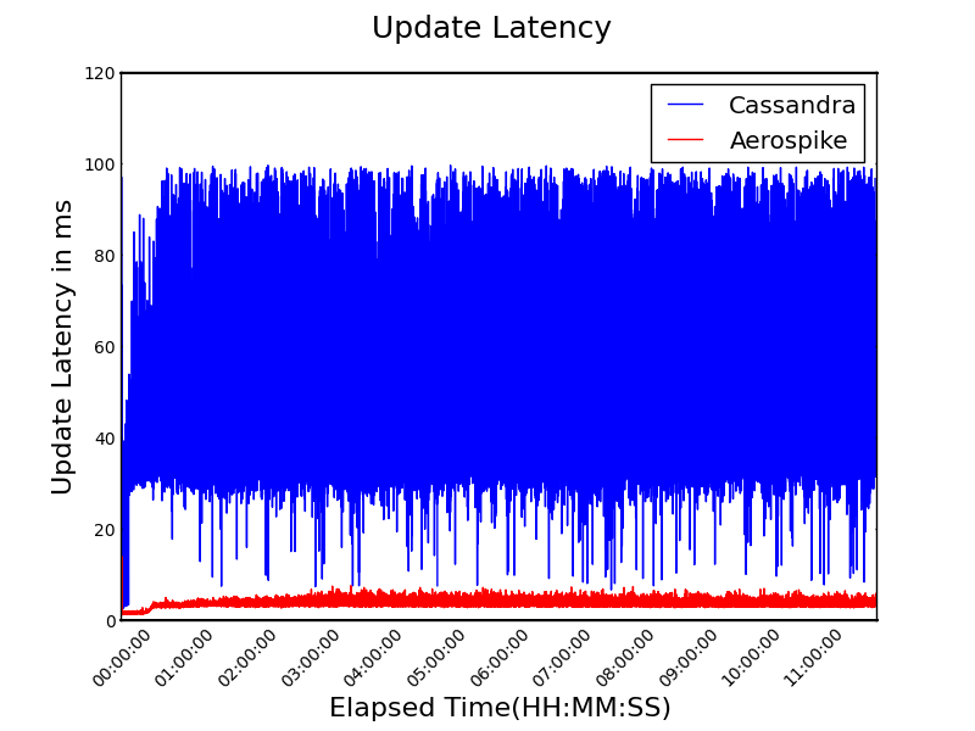
図7. 95パーセンタイルでの更新レイテンシ(低いほど良い)
95パーセンタイルでの更新レイテンシ(図7)で明らかなように、Cassandra(青い線)は、非常にバラツキが多く、即ち、レスポンス時間が一定では無いことが分かります。読み込み時のレイテンシの時と同様に、約30分程度の時間、レイテンシの増加が見られます。これは、種々のシステム・プロセス(例えば、圧縮やデフラグメンテーション等)が開始されたため、システム性能に影響が出ています。Aerospike(赤い線)のバラツキはCassandraに比べて非常に小さく、レスポンス時間の予想が容易にできることが分かります。
結論
今回のベンチマークを通して、混在負荷環境下において、AerospikeはCassandraに比べ、以下のすべての項目でCassandraを凌駕しています。
14倍のスループット
42分の1の読み込みレイテンシ
24分の1の更新レイテンシ
8倍の書き込みスループット
今回のベンチマークで得られた結果は、非常に興味深いものだと考えています。特に、Cassandraは、DRAMを超えるデータに対して、高スループットと低レイテンシのために設計されていると認識されているのですが、Aerospikeは、Cassandraに比べて、極めて高いパフォーマンスを非常に少ないバラツキで提供できることが明らかになりました。つまり、Aerospikeのパフォーマンスは、一貫性が高く、予測可能なものであり、ジッターの少ないものでした。
ITや収益の観点から、このことは、以下を意味します。
Aerospikeは、将来の成長を低コストで実現できます。
同様のサイズのAerospikeクラスタは、14倍のトランザクションを以下のレイテンシで処理可能です:
42分の1の読み込みレイテンシ
24分の1の更新レイテンシ
Aerospikeは、TCO (Total Cost of Ownership)を大きく削減できます。
Aerospikeは、クラスタのサイズを14分の1にできる可能性があります
Aerospikeは、バラツキの少ない一貫したパフォーマンスを提供できます。
Aerospikeは、アプリケーションの運用(キャパシティ・プランニング)がより簡単です
ぜひとも、御社の環境で、想定される負荷の下、今回のベンチマークを再現し、AerospikeとCassandraの違いをご確認ください。その結果、Aerospikeのパフォーマンスが優れ、ビジネスの観点から非常にメリットがあり、費用対効果が著しいことをご理解いただけるものと確信しております。
不必要な論争を避けるため、今回のベンチマークを正確に再現できるようにように、設定の詳細をご開示しています。今回の結果に対し、皆様と議論をできればと思っておりますので、今回のベンチマークに対するご意見、ならびに、AerospikeやCassandraを実運用されているご経験を共有していただけるのであれば、ぜひとも、フォーラムにご投稿ください。いろいろな観点から、議論をさせていただければと思っております。
弊社が実施したベンチマークを再現する際には、“Recreating the Benchmark – Aerospike and Cassandra: Benchmarking for Real”をご参照ください。
無料のAerospike Enterprise Trialをご希望であれば、ぜひとも弊社にご連絡ください。
ベンチマークに使用したソフトウエア、ハードウエア
ソフトウエア
ベンチマークには、AerospikeとCassandraの双方とも、オープンソース版を使用しました。実施時点での最新版を使用しましたが、それらのバージョンは、Aerospike: Community Edition version 3.8.2.3、Apache Cassandra: version 3.5.0です。稼働環境のOSはCentos 6.7、JavaのバージョンはOracle Java Hotspot 8.0.60を使用しました。
ハードウエア
使用したハードウエアは、データセンタで普通に利用されるようなものを選択しました。従って、特別なハードウエアを用意することなく、容易に再現できるものと思います。AerospikeとCassandraは異なるハードウエア要件を必要とするため、両データベースの稼働に問題のない下記のハードウエアを選択しました。
表3. ベンチマークに使用したハードウエア
補足 A – Cassandraのベンチマークの際の注意点
インストレーションとハードウエア選択
Cassandraには非常に多くの考慮すべきオプションがあるため、インストールと設定の際には、種々の選択をする必要があります。著名なCassandra専門家から学んだものを基に、公平で理にかなったベンチマークを実施することを目指しました。
今回のベンチマークでは、Apache Cassandraのオープンソース版を使用しました。2016年4月13日に、バージョン3.5.0がリリースされましたが、そのバイナリ・バージョンをApacheのサイトからダウンロードしました。パッケージ化されていない(JavaベースのApacheプロジェクトでは良くあること)ため、単純に解凍しディレクトリに展開しました。
CassandraプロジェクトではSSDを使う場合が多いものの、その設定に関する情報はあまり多くはありません。SSDを最適化するための推奨パラメータが幾つかあるのですが、その中でも重要なものとして、使用するファイルシステムの選択があります。Apache Cassandraのサポートを提供し、専門家として認識されているDatastax社の推奨を参考にしようとしましたが、推奨ファイルシステムに関する記述は見つかりませんでした。それゆえ、Al Tobeyのチューニング・ガイドがXFSを強く推奨していたため、これを採用しました。各々のSSDをXFSファイルシステムでフォーマットし、Cassandra設定ファイルに個々のデータ・ディレクトリとして追加しました。
また、デフォルトのシステム・ファイル・ハンドルの数値を増やしました。これを増やさないと、長時間のベンチマークで、ファイル・ハンドルを使い切ってしまうためです。その場合、Cassandraは、ワーニングを出すこと無く、停止してしまいます。ここでも、Al Tobeyのチューニング・ガイドを参考にして、sysctlとlimits.confを修正しました。
ベンチマーク条件を公平にするため、Cassandraのデータ・ロード後の圧縮が終了するのを待ちました。圧縮の量をモニタし、圧縮が終了した後に、ベンチマークを開始しました。
チューニング・パラメータ
圧縮スループットのチューニング:ベンチマークのテスト・ランの際に経験したことですが、データ・ロード直後に負荷をかけると、Cassandraは圧縮のために遅くなり、クラッシュすることすらありました。なぜでしょうか?Cassandraのデフォルト設定の毎秒16MBの圧縮は、ベンチマークやストレス・テストには適していないためと思われます。圧縮を調整するため、種々の設定を試したのですが、最終的には、一定の負荷を12時間かけた場合、期待する圧縮率をその間、維持できないことが分かりました。多くの人がコメント(例えば、Ryan Svihlaのブログ:“How I Tune Cassandra Compaction”)していますが、低いトラッフィクの時間帯で十分、対応できるように圧縮の設定をすべきということです。
しかしながら、今回のベンチマークでは、一定のトラッフィクで最大値を見つけようとしていますので、低トラフィックの時間帯がある訳ではありません。一度、あるレベルを超えてしまうと圧縮が追いつかなくなるため、実際のアプリケーションでは、最大の運用持続できるレベルを測定することをお薦めします。結局、12時間に渡る最大レベルの継続的なスループットを得るためには、圧縮を使わないようにしなければならないことが分かりました。
Row Cacheのチューニング:Row Cacheを使うかどうかの判断も必要です。また、使う場合、今回のベンチマークの負荷に適切な値を設定しなければなりません。Row Cacheは、高いヒット率を達成する場合にのみ推奨されるものですが、そうでない場合、パフォーマンスの低下を引き起こします。今回の負荷、即ち、均一な分布の負荷の場合、キャッシュのヒット率はあまり高くないと評価しました。想定されるデータ・サイズからすると、Row Cacheはノード当たり約120GB程度と推定されたのですが、今回のサーバは32GBのメモリであることから、Row Cacheを使用しないこととしました。
Key CacheとJVMヒープサイズのチューニング:Key Cacheを最適化するための実用的なガイドラインをなかなか見つけられませんでした。JVMのヒープサイズについては、Datastax社はDRAMの4分の1、8GB以下に設定することを推奨していたため、今回は、これを採用しました。均一な負荷の場合、95%という最適なヒット率を得るためには、Datastax社の推奨に従うとKey Cacheは、各サーバで11GB以上が必要となり、JVMヒープサイズの8GBを大きく超え、最適なKey Cacheを設定することはできません。何回の実験の後、Key Cacheを大きくするとレイテンシが増加することを発見しました。それ故、今回は、Key Cacheを1GBとしました。
Javaギャベージ・コレクションのチューニング:Cassandraに対する種々の負荷に、どのギャベージ・コレクタが良いのかという議論は多数あります。我々は、ギャベージ・コレクタとして、CMSとG1GCを試してみました。これら2つの間では、パフォーマンスに大きな違いはありませんでしたが、より普及した推奨に従って設定したいと考え、長時間のベンチマークのために、G1GC(G1ギャベージ・コレクタ)を採用しました。
Datastax社は、4GB以上のヒープサイズの場合、G1GCを推奨しています。以下は、ギャベージ・コレクタの選択の際に参照したドキュメントです:
https://www.infoq.com/articles/Make-G1-Default-Garbage-Collector-in-Java-9
https://sematext.com/blog/2013/06/24/g1-cms-java-garbage-collector/
圧縮タイプの選択:Cassandraでは、圧縮に関し、2つの選択肢があります:サイズ階層化とレベル化です。前者は書き込み負荷が高い場合、後者は読み込みと更新の負荷が高い場合に推奨されています。今回のベンチマークではYCSBを利用し、読み込み50%、書き込み50%という混合負荷を使用したため、レベル化圧縮を採用しました。採用理由については、以下のDatastax社のリンクをご参照ください:
http://www.datastax.com/dev/blog/leveled-compaction-in-apache-cassandra
http://www.datastax.com/dev/blog/when-to-use-leveled-compaction
読み込み・書き込みスレッドのチューニング:両パラメータの推奨値に関して、Datastax社は、書き込みスレッドをサーバのコア数と同じにすることを推奨しています。デフォルトの読み込みスレッドも、Datastax社の推奨に従い設定した結果、十分なパフォーマンスを達成していると思われます。
コミット・ログのチューニング:書き込み時のデータ永続性のため、コミット・ログへの書き込みを行いました。これは、Aerospikeの特性と同等のものであるためです。ちなみに、今回のベンチマークでは、コミット・ログへの書き込みをしない場合でも、測定結果への影響はほとんどありませんでした。
クライアントのチューニング
両データベースで同じ環境を作るため、比較的少ないスレッド数から始め、スループットが上限に達するまで、徐々にスレッド数を増加させました。Aerospikeはクライアントのスレッド数を1,500まで増やすことが出来ましたが、Cassandraではそこまでは到達できませんでした。最終的には、両データベースが12時間のベンチマークを完了できるように、クライアントのスレッド数を800に設定しました。
整合性
Cassandraでは、整合性をいろいろと設定できます。今回のベンチマークでは、書き込みにTWO、読み込みにTWOを選択しました。これは、Aerospikeと同等にするためです。この整合性レベルでは、アプリケーションが書き込み後に古いデータを読み出すという、いわゆるダーティ・リード問題を避けることができます。また、これは、Aerospikeのデフォルトの整合性モードと同等のものです。短時間のテストを実施し、整合性レベルのONEとTWOの比較を行いましたが、その差は2,000 OPSでした。これは、AerospikeとCassandraを比較するという観点からは大きな差にはなりません。
補足 B – Aerospikeのベンチマークの際の注意点
初心者にも簡単にインストールしていただけるように、弊社はいくつかの機能を提供しています。例えば、容易なインストレーションとバージョン管理のために、種々のLinuxの標準のパッケージを配布しています。さらに、Aerospikeは、サービスとしてインストールされます。
Aerospikeは、設定のためのファイルが一つだけです。そこには、DRAMとストレージ・デバイス、スレッドの数、クラスタを構成する他のノードのアドレスが定義されます。ハードウエアに依存するパラメータであるスレッド数やメモリ量に関しては、Guidelines from Aerospike for service-threadsを参照しました。
Aerospikeは、Cassandraの圧縮と同等の機能として、デフラグメンテーションがあります。これは、設定された間隔で継続的に稼働しています。今回のベンチマークにように、非常に高い書き込み負荷の下にあるシステムの場合、間隔をゼロにすることが推奨されています。ぜひとも、ストレージ情報に関するページをご覧ください。
Aerospikeは、SSDをrawデバイスとして使用するため、ファイルシステム(例えば、XFSやEXT4等)を選択する必要はありません。また、独立したコミット・ログも使用しません。このようなシンプルさゆえ、ハードウエアの選択や種々の設定が容易になっています。
脚注
Cassandraのデータロード時間は、実際の書き込みのみの時間としています。ベンチマークの開始前に、Cassandraの圧縮が終了するのに必要な72分間の待機時間を設けました。これは、公平で信頼性の高いベンチマークを行うためです。Aerospikeでは、圧縮と同等のものを別の方法で行うため、ベンチマーク開始前に待つ必要はありません。
今回のマザーボード上のハードディスク・コントローラは、低価格のRAIDコントローラを通過します。そのため、クエリに対し、若干のレイテンシが追加されます。SSDは、RAIDアレイの一部ではありませんが、レイテンシに影響を及ぼします。その結果、マザーボード直接か高級なRAIDコントローラに接続された場合のSSDと同等のパフォーマンスには至りません。Cassandra、Aerospikeの両方とも、同じ設定を使用しました。
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog