
Introduction
Migrations are the process of rebalancing and syncing partitions after a cluster disruption event such as a link failure, node restart, etc. With Aerospike Enterprise v3.8.3, we have reduced the typical cluster migration time by 40x. Operations teams can now look forward to much faster upgrade cycles and static configuration changes. Similarly, the applications supported by Aerospike can now benefit from vastly reduced latencies during migration windows.
High-Level Design
The Rapid Rebalance algorithm streams record metadata from the immigrator to the emigrator in digest order. The emigrator uses the metadata in its local partition scan to determine which records need to be read from drive and shipped to the remote node. This decision uses the configured conflict resolution strategy to determine which version of the record should persist. In the event the emigrator’s version wins (and only then), the emigrator reads from storage and ships the record to the immigrator node.
Challenges
Since migrations operate over Aerospike’s fabric layer, which can reorder messages, sending metadata in an order other than random presented a challenge. We chose to use a sequence number for each message; the immigrator only sends the next sequence when the emigrator acknowledges the prior sequence number. The emigrator also tracks the latest sequence it has acknowledged. If it receives a sequence of lesser value, it will acknowledge the message, but not process it. This means that messages can only arrive in order. In the event of timeouts and retransmits, messages for a given sequence will be processed once at the most.
Our second challenge was that synchronously sending a single record metadata at a time will not perform well. Therefore, we chose to batch metadata in chunks of about 128KB, which is the size of the fabric layer’s pre-allocated buffers. The immigrator queues these batches to be sent to the emigrator. Each batch is then sent synchronously using the sequence method described above.
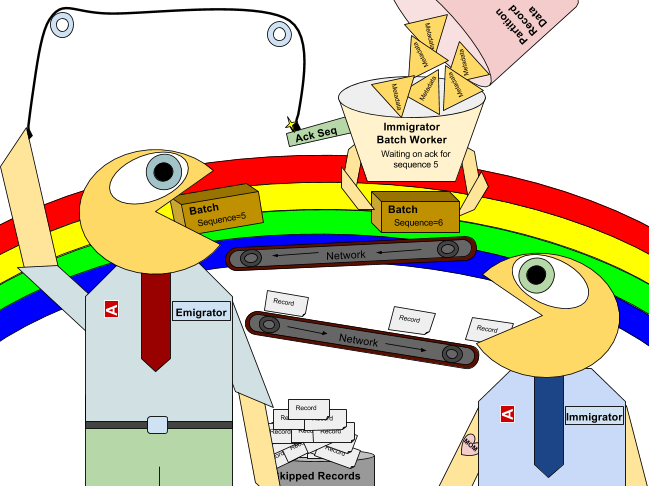
Figure 1. Illustration of the Rapid Rebalance process
The final challenge is the possibility for a migration to be slower as a result of sending the metadata. Consider the case where the emigrator’s partition contains far fewer records than the immigrator’s partition. In this case, the size of the metadata transfer may be larger than sending all of the emigrator’s records. To solve this problem, we settled on the following heuristic: if on average, the emigrator only sends a single record per metadata batch, then the algorithm is disabled for that particular partition migration.
Implementation
The outline of the algorithm is as follows:
The emigrator sends a partition migration start message to the immigrator, which includes the fact that it supports Rapid Rebalance, as well as the number of records in its partition.
The immigrator receives the start message, and determines if Rapid Rebalance should be enabled based on the record count ratio between the immigrator and emigrator’s partitions. It acknowledges (acks) the emigrator’s start message, including whether or not Rapid Rebalance will be used.
If the immigrator engages Rapid Rebalance, a producer and consumer thread is then triggered to generate and transmit metadata batches.
The producer thread scans through the partition records, creating metadata batches and inserting them into a queue.
The consumer pops a batch from the queue and sends it to the emigrator with the starting sequence number. The consumer will not continue to the next message until it has received an acknowledgment from the immigrator.
Meanwhile, the emigrator, which has received the start response containing whether or not the immigrator will support Rapid Rebalance for the current migration, proceeds to scan through the partition records for migration. If Rapid Rebalance is enabled, the emigrator blocks on the metadata queue until data arrives.
Upon receiving a metadata batch from the immigrator, the emigrator inserts the batch into the local queue and sends an acknowledgment to the immigrator.
On the emigrator’s metadata queue, the batch rendezvous with the emigrator’s record scan, where a decision is made whether or not to read and ship the local copy to the immigrator.
Conclusion
The Rapid Rebalance feature enables an operations team to deploy a server upgrade or static configuration change across a cluster in minutes rather than days. Rapid Rebalance also reduces the time interval during which migrations impact transaction latency from days to minutes. Overall, we like this change and the simplicity it provides. We look forward to hearing your real-world experiences with this new feature on our user forum!
Keep reading

Jul 21, 2026
KV cache tiering: Why GPU memory alone won't scale your LLM app

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX