Aerospike is pleased to announce that Aerospike Connect for Kafka has been certified for the Confluent Platform.
The Aerospike database is a highly scalable NoSQL database and its hybrid memory architecture makes it an ideal database for streaming workloads. It is typically deployed into real-time environments managing terabyte-to-petabyte data volumes and supports millisecond read and write latencies. It leverages bleeding-edge storage innovations such as PMem or persistent memory from best of breed hardware companies such as HPE and Intel. By storing indexes in DRAM, and data on persistent storage (SSD) and read directly from disk, Aerospike provides unparalleled speed and cost-efficiency. It can be deployed alongside other scalable distributed software such as Kafka, Presto, Spark, etc. via the Aerospike Connect product line for data analysis. The Confluent Platform is an enterprise-ready platform that complements Kafka with advanced capabilities designed to help accelerate application development and connectivity and enable event transformations through stream processing.
The certified Aersopike Kafka connector leverages both the Confluent Platform and Aerospike to offer a low latency and high throughput streaming pipeline. It transforms messages from Kafka to the Aerospike data model and vice-versa with limited configuration (see below). It also provides routing options to route user-specified namespaces, sets, records, or bins to a specific Kafka topic for downstream consumption. The Kafka connector supports various message formats such as Avro, MessagePack, JSON, FlatJSON, and also supports the Schema Registry that is bundled into the Confluent Platform for schema management and evolution.
Aerospike | RDBMS | Kafka |
Namespace | Database | Topic |
Set (Optional) | Table | Topic |
Record | Row | Event or Message |
Bin | Column | Message Fields |
The Aerospike and the Confluent teams worked together to certify that the combined platform consisting of the Aerospike database and the Confluent platform is suitable for various event streaming use cases. Typical use cases include fraud detection, offloading Mainframe data, creating 360-degree customer profiles, Industrial IoT, etc. that demand low latency and high throughput.
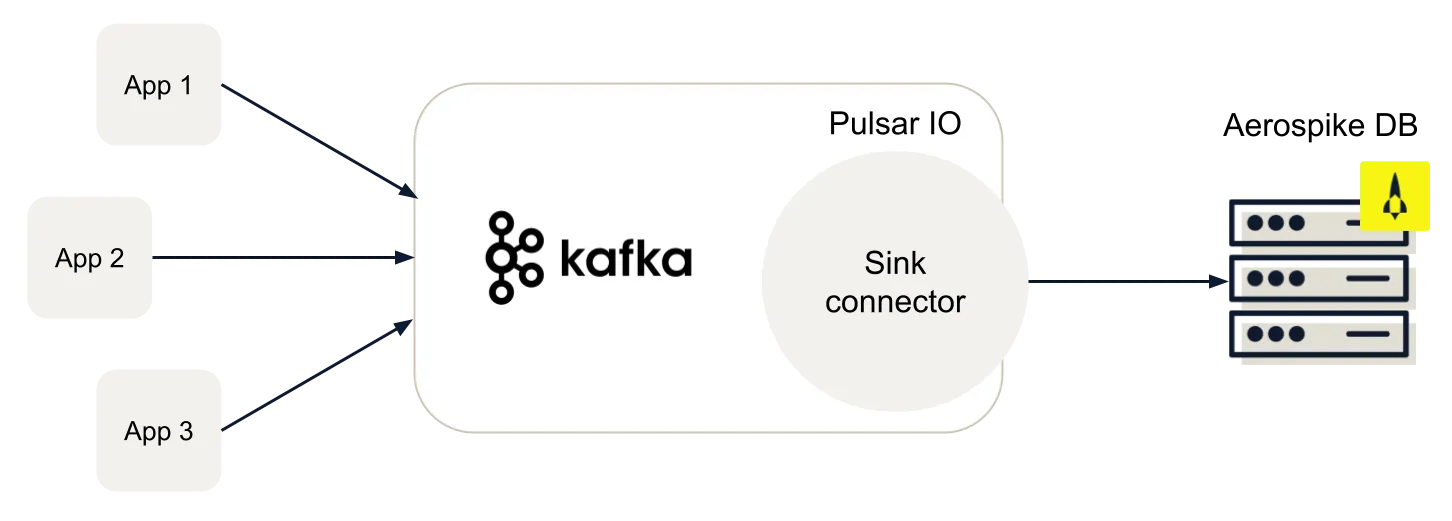
The Certified Aerospike Kafka sink Connector utilizes Kafka Connect, a framework included in Apache Kafka that integrates Kafka with other systems securely and at scale. It enables Aerospike customers to use Kafka to write data to Aerospike from systems that typically do not have any integration with Aerospike such as legacy databases, Mainframes, IoT systems, etc., but have a connector for Kafka. Aerospike database is used for long term storage of up to petabytes of data, which is later rapidly served via Aerospike clients or an Apache Spark-based analytics system. See Figure 1.
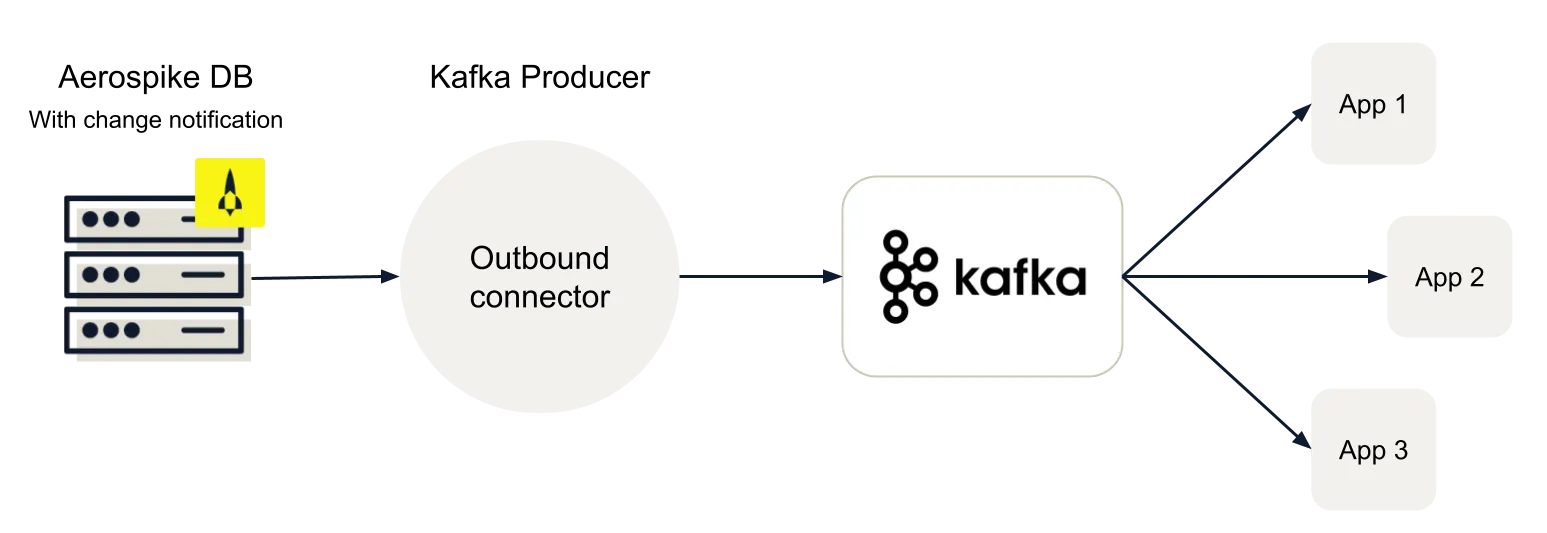
The Certified Aerospike Kafka source Connector utilizes Kafka Producer API to stream change notifications (similar to Change Data Capture (CDC) in RDBMS) to downstream applications via Kafka. The downstream applications are basically notified that a record has been inserted, deleted, or updated in Aerospike for further processing. It supports the Confluent Schema registry to allow schema management and evolution. In this deployment scenario, the Aerospike database is used as an edge system for high velocity ingestion and applying back pressure so that the downstream system can catch up. It could also be used for filtering out sensitive information in the edge system for compliance. See Figure 2.
To download the Certified Aerospike Kafka Connectors, please visit Sink Connector and Source Connector. For more details on the Aerospike Kafka connector, please visit Aerospike Connect for Kafka.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works