Blog
Why we tested AWS Graviton4 for Aerospike
AWS Graviton4-based I8g instances offer significant advantages for AdTech workloads, including 6X throughput and improved latency.
Blog
AWS Graviton4-based I8g instances offer significant advantages for AdTech workloads, including 6X throughput and improved latency.

Aerospike customers run high-performance, real-time applications where both ultra-low latency and high throughput are mission-critical. In AdTech, milliseconds determine whether an ad is placed and directly impacts revenue. In fraud detection, a delayed decision can be the gateway for fraudulent transactions.
Many customers currently use AWS Graviton2-based Amazon EC2 I4g instances, which provide strong price performance for these workloads. With the launch of AWS Graviton4-based Amazon EC2 I8g instances, AWS introduces new storage-optimized EC2 instances I8g featuring third-generation AWS Nitro SSDs for even better performance.
We tested these two instances to evaluate whether these upgrades translate into real-world benefits, focusing on throughput, latency, and SLA compliance under real-time AdTech workloads.
To evaluate the performance of AWS Graviton4-based Amazon EC2 I8g instances against AWS Graviton2-based Amazon EC2 I4g instances, we designed a workload that mirrors real-world AdTech demands, focusing on ultra-low latency, high availability, scalability, and cost efficiency.
We benchmarked two distinct datasets running concurrently, simulating how AdTech platforms operate under production conditions.
User profile database (80/20 read/write): Stored both indexes and data entirely on Flash (SSDs) for low-latency, high-volume reads.
Campaign database (50/50 read/write): Stored using Hybrid Memory Architecture (HMA)—indexes in DRAM, data on Flash—to optimize read/write balance.
Infrastructure: 9-node Aerospike clusters of each type with 16 load-generation servers.
Replication factor: 2 (ensuring high availability). Note: RF2 is a standard practice for Aerospike.
Compression: Lz4 (4:1 ratio) to reduce storage requirements.
Latency SLA constraints:
Reads: P99.9 under 1.0ms
Writes: P99.9 under 2.0ms
The goal: Measure maximum sustainable TPS before violating these SLAs.
| Dataset | Storage | Workload mix | Records | Uncompressed size |
|---|---|---|---|---|
| User profile database |
All-Flash (SSDs) | 80/20 read/write | 50 billion | ~100 TB |
| Campaign database | Hybrid (Indexes in DRAM, data on Flash) | 50/50 read/write | 600 million | ~2 TB |
We ran a mixed read-write workload at a baseline of 150K TPS and assessed whether it met our representative SLAs:
1ms P99.9 for reads
2ms P99.9 for writes
We gradually increased throughput until the SLA thresholds were violated.
This process was repeated for both I4g and I8g.
Results:
Graviton2-based I4g.16xlarge-based clusters sustained up to 193K TPS before exceeding the SLA.
Graviton4-based I8g.16xlarge-based clusters sustained up to 1.16M TPS before exceeding the SLA.
This represents a 6X improvement in max sustainable throughput.
Note: For clarity, throughout this article, "read latency" refers to the P99.9 read latency—the time within which 99.9% of all read operations complete.
I8g.16xlarge clusters demonstrated substantial improvements over I4g.16xlarge, particularly at high throughput, by reducing tail latencies.
Performance at scale: Our tests ranged from 150K transactions per second (TPS) to over 3 million TPS. At around 400K TPS, I8g.16xlarge clusters delivered 30% faster read latency compared to I4g.16xlarge. However, as TPS increased to 750K and over 1M TPS, I8g.16xlarge delivered over 80% and over 90% latency gains, respectively.
Throughput gains while maintaining SLA constraints: Under strict latency SLAs of 1ms (P99.9) for reads and 2ms (P99.9) for writes, I8g.16xlarge delivered six times the TPS compared to I4g.16xlarge’s TPS delivery.
SLA-driven performance: We measured how long clusters of each instance could sustain increasing throughput while maintaining SLA thresholds.
| Instance | Read TPS | Write TPS | Total TPS |
|---|---|---|---|
| I4g.16xlarge |
153,255 | 40,110 | 193,365 |
|
I8g.16xlarge |
919,530 | 240,660 | 1,160,190 |
| Improvement | 6x | 6x | 6x |
As you can see in Table 2, an AdTech platform running on I8g can process 6X more bids while maintaining these strict SLAs. Since every processed bid translates to a revenue opportunity, this dramatically increases monetization potential without compromising response times. Similarly, fraud detection and personalization engines can analyze 6X more transactions in real time, reducing risk and improving customer experience at scale.
AWS tests show that I8g delivers clear advantages over I4g:
Better compute – Graviton4 delivers up to 60% higher compute performance and improved memory bandwidth.
Better storage – I8g instances use 3rd-generation AWS Nitro SSDs, reducing storage I/O latency by up to 50% and variability by up to 60%.
To better understand the hardware differences between I8g and I4g instances, Table 3 summarizes their key specifications:
|
I4G (i4g.16xlarge) Graviton2 |
I8G (i8g.16xlarge) Graviton4 |
|
|---|---|---|
| vCPU | 64 | 64 |
| Memory (GiB) | 512 | 512 |
| Storage |
2nd Gen Nitro SSD 4 x 3,750 GB = 15,000 GB |
3rd Gen Nitro SSD 4 x 3,750 GB = 15,000 GB |
Another way to analyze performance is to look at worst-case latency–specifically P99.9, the time in which 99.9% of requests complete. Instead of focusing on the maximum TPS before SLAs break, this view shows how tail latency behaves under increasing load.
In the user profile workload (which is read-heavy), read latency starts to diverge significantly between the Graviton2-based I4g.16xlarge cluster and the Graviton4-based I8g.16xlarge cluster as the TPS increases:
I4g.16xlarge: Once throughput reaches ~400K TPS, read latency begins climbing rapidly and surpasses the 1ms SLA. By the time the cluster reaches its maximum throughput of about 1M TPS, the P99.9 read latency hits 18ms, effectively saturating the system.
I8g.16xlarge: In contrast, I8g.16xlarge clusters remain below SLA thresholds even as throughput scales beyond 1M TPS. In our tests, read latencies stayed under 3ms– even at 3M TPS– a clear indication that I8g.16xlarge handles significantly higher load without tail latency spikes.
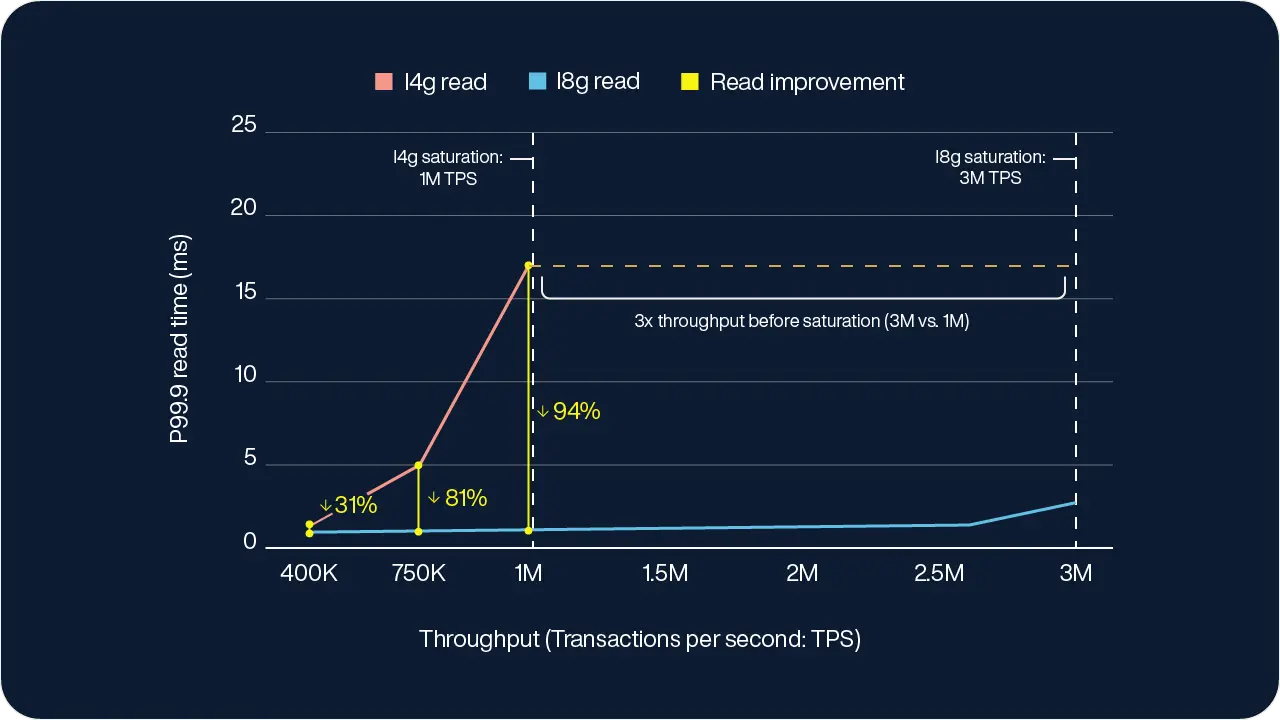
In the more write-intensive campaign workload, the gap in performance is even more evident.
I4g.16xlarge: As TPS rises above 400K, P99.9 write latencies quickly exceed the 2ms SLA. By the time it reaches ~1M TPS (its saturation point), write latency spikes to just under 120ms. making it unsuitable for real-time demands.
I8g.16xlarge: Even as the I8g.16xlarge cluster scales far beyond 1M TPS, P99.9 write latency remains under 4ms– again demonstrating how much additional headroom Graviton-4 based systems provide.
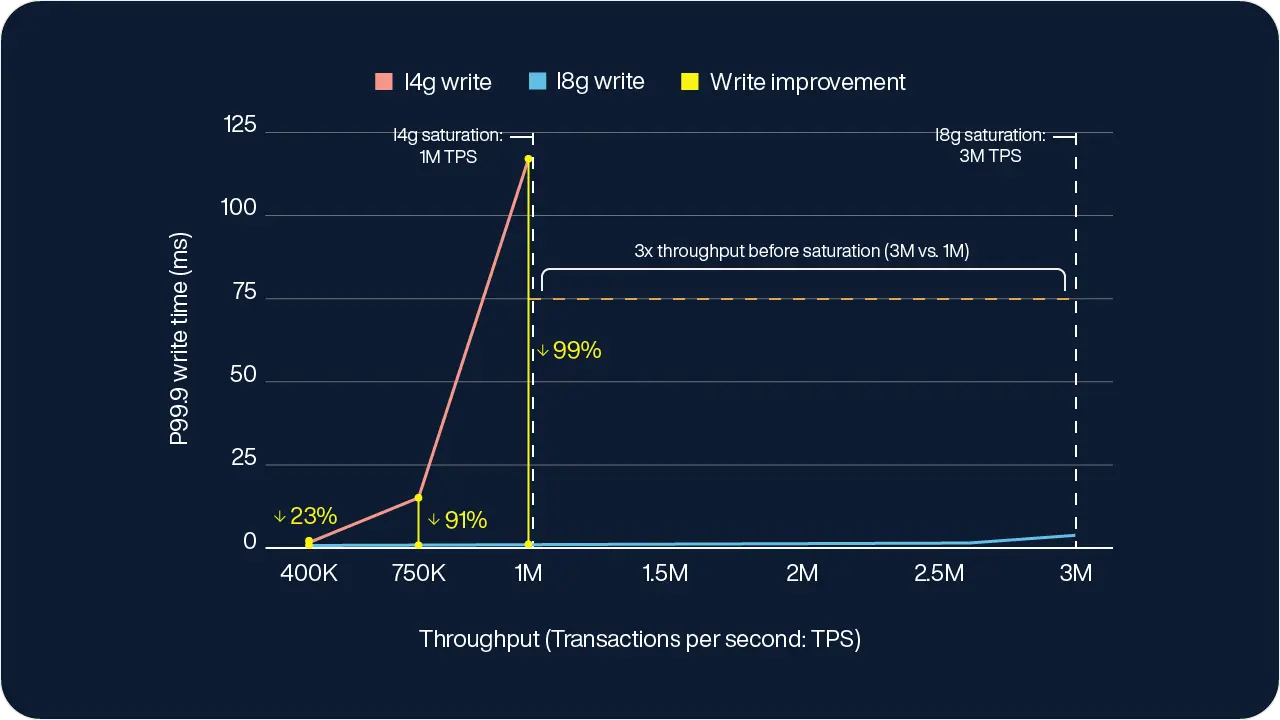
As shown in the charts, I4g.16xlarge data stops at ~1.1M TPS, marking the point where the system is unable to service additional requests. Meanwhile, the I8g.16xlarge clusters continue scaling up to 3M TPS before reaching the cluster’s maximum throughput.
This amounts to processing 3X more transactions at a fraction of the latency, underlining why I8g.16xlarge is ideal for real-time workloads that demand ultra-low, predictable latencies at scale.
Graviton4-based I8g instances improve both storage and compute performance, ensuring higher throughput and lower latency at scale.
For real-time applications, avoiding latency spikes is as important as high average speed. One of the biggest challenges in high-performance databases is latency variability—unexpected spikes in response times, even under steady workloads. These variations can occur due to background storage operations and other system-level factors.
The latest 3rd generation AWS Nitro SSDs minimize these fluctuations and deliver up to 50% lower storage I/O latency and up to 60% lower storage I/O latency variability versus the 2nd generation AWS Nitro SSDs in I4g instances, according to AWS testing. While I4g.16xlarge instances can achieve similarly high TPS numbers, they do so at the cost of much higher latency. In contrast, the 3rd generation Nitro SSDs in I8g.16xlarge enable more consistent storage performance, reducing unpredictable delays.
For Aerospike customers, this translates to greater reliability for real-time workloads, ensuring that latency-sensitive applications can operate at higher scale without performance disruptions.
According to AWS testing, Graviton4 provides up to 60% better compute performance and improved memory bandwidth compared to Graviton2, allowing Aerospike to handle significantly larger transaction volumes while maintaining low latencies. The combination of faster storage and more efficient compute enables real-time applications to scale more efficiently while keeping response times predictable.
Our testing shows that Graviton4-based I8g instances outperform Graviton2-based I4g instances in both speed and efficiency. I8g provides:
94-99% lower tail latencies at high TPS, ensuring critical transactions are completed on time.
6X higher TPS while maintaining SLA guarantees, allowing more real-time decisions per dollar spent.
3rd-generation AWS Nitro SSDs reduce storage latency and variability, eliminating performance spikes that can degrade real-time processing.
For customers pushing the limits of Graviton2-based I4g instances, Graviton4-based I8g instances offer a clear path forward—handling significantly more queries with predictable, low-latency performance while keeping infrastructure costs in check. To maximize real-world impact, we recommend benchmarking with your own workloads to quantify the gains in your specific environment.
Running the latest version of Aerospike on AWS Graviton4 not only delivers up to 6X more throughput and dramatically lower tail latencies but also translates directly into increased revenue opportunities and cost savings for customers. Our benchmarks are fully reproducible—check out our GitHub repository —to confidently harness these results and drive your business forward.
For a deeper understanding and more insights, explore these additional resources.
See more


