Why is Aerospike’s HMA-based storage engine so performant?
Learn why Aerospike's storage engine stands out with its innovative Hybrid Memory Architecture (HMA) design, providing unmatched speed and reliability for demanding workloads.

NoSQL key-value stores (KVS) power some of the world’s most demanding applications, from real-time ad targeting and e-commerce recommendation engines to financial trading systems. Despite their diverse applications, these industries share a core need: a database that delivers low latency, high throughput, and rock-solid reliability for real-time decision-making. Crafting a storage layer to meet these stringent requirements is no small feat.
This blog explores how Aerospike’s innovative Hybrid Memory Architecture (HMA) drives its high performance, enabling efficient reads and high-throughput writes. Aerospike’s unique design sets a new standard for real-time database performance, making it the go-to choice for enterprises where speed and efficiency are non-negotiable.
A brief overview of storage engine designs
KVS must excel at handling write-heavy workloads while ensuring real-time access to key-value pairs. In a previous blog on the evolution of database storage engines, we examined how early relational systems and modern distributed databases approached these challenges. Here’s a quick refresher:
In-place updates: Early relational database systems
Slot-based indirection: A slot number tracks a record’s location within a block, enabling updates without modifying the primary index unless the record moves outside its original block.
Efficient reads: By leveraging a primary index that maps keys to record locations, systems that perform in-place updates ensure ultra-fast reads.
Write throughput limitation: Each record update triggers a separate I/O operation, significantly constraining write performance.
Out-of-place updates: LSM-tree-based systems
Buffered writes: Writes are batched in memory and flushed to disk in sorted runs, reducing the I/O overhead per record.
Sequential I/O optimization: Writing in sequential blocks leverages the inherent efficiencies of sequential I/O over random I/O.
Read overhead: Reads often require scanning multiple sorted runs, increasing latency. LSM-trees were originally designed for write-heavy scenarios, where real-time reads were secondary considerations.
Aerospike’s storage engine: Combining the best of both worlds
While databases like BigTable, Dynamo, Cassandra, CockroachDB, and YugabyteDB rely on LSM trees, others, such as MongoDB’s WiredTiger storage engine, default to in-place update-based storage with B+-trees. In this context, Aerospike’s storage engine is a game-changer. By integrating the best aspects of in-place and out-of-place update-based architectures, Aerospike achieves unparalleled performance in both reads and writes.
Out-of-place updates without sorted runs
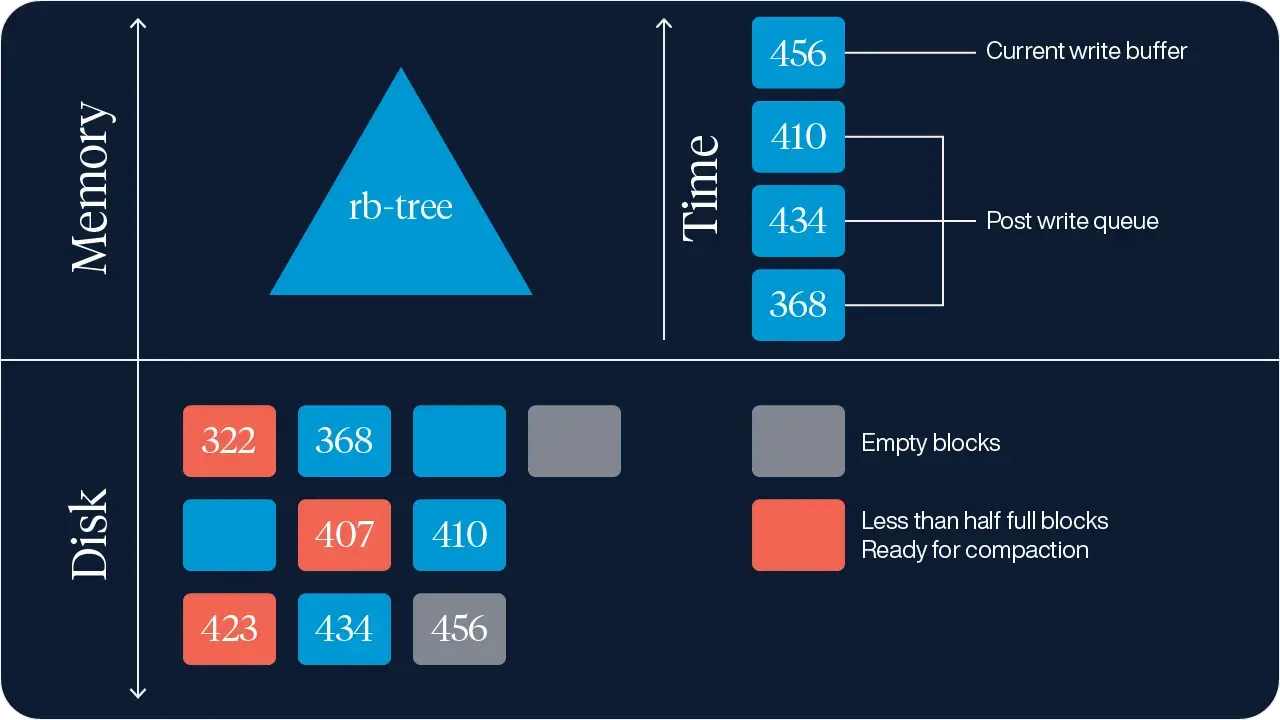
Aerospike employs out-of-place updates for record storage to boost write throughput but avoids the overhead of creating and maintaining sorted runs. Figure 1 shows a schematic of Aerospike’s storage engine architecture. Here’s how it works:
Write efficiency: Updates are buffered in memory (block 456 in Figure 1, which is empty on disk) and flushed to disk in a single I/O operation when the write block fills. The data on the disk is not sorted, however.
Primary index in memory: Aerospike’s HMA keeps the primary index entirely in memory (rb-tree), reflecting the new location of updated records instantaneously, i.e., the primary index performs in-place updates.
Predictable read performance: Reads consistently require at most one I/O operation, even for frequently updated records.
This design delivers the write efficiency of LSM trees while ensuring predictable, low-latency reads—a critical advantage for real-time applications.
Garbage collection: Simple yet powerful
Aerospike’s garbage collection (GC) mechanism is another key differentiator. We use the term GC in this blog to refer to defragmentation, since GC is more commonly used by LSM-trees, to make the equivalence clear to people familiar with LSM-trees. Unlike LSM trees, which incur significant overhead during compaction, Aerospike employs a straightforward and efficient GC process:
Block consolidation: Periodically, blocks that are less than half-full are identified and consolidated. In Figure 1, blocks 407 and 423 are less than half-full and can be compacted into one block, freeing up the other for future use.
Index-driven cleanup: GC moves the live records in a less than half-full block to a different block. The memory-resident index allows GC to quickly recognize which records in the block are current and update its location when it is moved without any additional IO.
Minimal overhead: GC involves consolidating blocks less than half-full (e.g., 407 and 423 in Figure 1). This process requires just one additional write per compacted block. Aerospike’s simple compaction algorithm significantly reduces computational and I/O costs compared to LSM-tree compactions.
Why prioritize memory for the primary index?
A common question arises: why did Aerospike choose to store the primary index in memory, given that memory is a scarce resource? The answer lies in achieving the highest performance and predictability for key-value stores.
Let’s first address the feasibility of fitting the primary index in memory. Modern cloud infrastructure provides a minimum memory-to-disk ratio. For instance, local NVMe instances often offer at least one byte of memory for every 30 bytes of disk. Aerospike’s primary index comfortably fits within this ratio for datasets where the average record size exceeds 3 KB. Aerospike deployments often handle latency-sensitive, real-time workloads requiring multi-region (or multi-cloud) replication for high availability. Local NVMe instances offer the most reliable and cost-effective storage for such use cases. In short, the memory required for the primary index is effectively included in the resources of these cloud instances. Aerospike does allow the primary index to be on disk where it is valuable (e.g., small records and limited memory) but that is not the focus of this blog.
Caching entire records might seem like an alternative use of memory, and is discussed in detail in the blog, Caching doesn’t work the way you think it does. The key points are:
Caching does not help with end-to-end latency. Access to memory occurs within nanoseconds, whereas SSD access takes microseconds, and network delays—even within an availability zone—can range from hundreds of microseconds to milliseconds. The latency of end-to-end requests is typically not determined by disk I/O for individual records but by network latency. Next, even if an application were to batch hundreds of database requests in a single network request, caching is unlikely to help with end-to-end latency. The hundreds of requests make a cache miss very likely, and thus, the latency is dictated by the request missing the cache.
Caching may increase throughput, but prioritizing memory for the primary index proves more impactful for overall throughput. The entire write cycle, from updating a record to garbage collecting older versions, is highly efficient because the primary index resides in memory. The primary index is updated during record writes and read extensively during garbage collection. If memory were allocated to caching records instead, the database would lack the high-throughput primary index reads essential to Aerospike’s efficient garbage collection. Having said this, customers can use any extra memory left over after the primary index is accommodated in memory in HMA for a post-write queue (shown in Figure 1 above). This can be used by applications that need to access recently written data as well as asynchronous Cross Datacenter Replication (XDR). Customers can also enable the file system read caching to serve as a read cache, but the main goal here is to argue why prioritizing memory for the primary index is more valuable than for a cache.
Explore Aerospike’s Hybrid Memory Architecture
Aerospike’s Hybrid Memory Architecture represents a breakthrough in storage engine design, blending the best features of in-place and out-of-place update approaches. By prioritizing memory for the primary index, Aerospike ensures high-throughput writes and consistent low-latency reads, even under the most demanding workloads.
From real-time analytics to fraud detection, Aerospike empowers enterprises to deliver fast, reliable, and scalable solutions. Its unique architecture isn’t just about keeping pace—it’s about setting the pace in the race for real-time database performance.