What are database schemas?
A database schema is a structured framework that organizes data within a database. It defines how different elements, such as tables, fields, and relationships, are arranged to improve data integrity and accessibility. In database management, schemas are guided by a Database Management System (DBMS), software dedicated to creating, managing, and maintaining databases.
Schemas are categorized into two primary types: logical schema and physical schema. A logical schema represents the abstract structure of the database, focusing on elements such as entities, attributes, and relationships without considering physical storage. This high-level design helps database designers visualize and organize data conceptually. In contrast, a physical schema details the actual storage of data, emphasizing the underlying hardware and software infrastructure to optimize performance and storage efficiency. Understanding the distinction between logical schema and physical schema is important for database management to provide efficient data organization and reduce resources. The purpose of this blog post is to focus on logical schema.
While people often say that NoSQL databases such as Aerospike are “schemaless,” what they really have is a flexible schema. The advantages of a flexible schema are that they can store unstructured data such as imagery, and different records can have different types of data depending on user needs.
Database schema components
Integrating schemas from different data sources is important for any data management strategy. Schema integration combines multiple databases or data sources into one structure so users can retrieve and manage data as if it were within one database. This process helps validate data interactions while maintaining performance without affecting data integrity.
However, successful schema integration means meeting several requirements to help the schema be functional and scalable over time. This requires consistency, completeness, minimal redundancy, flexibility, and performance so that a well-integrated schema can handle a wide range of data sources and adapt to future changes.
Requirements for schema integration
Consistency: The integrated schema must maintain consistency across different data sources so data definitions are uniform and coherent.
Completeness: All necessary data from the source schemas must be included in the integrated schema so no information is lost.
Minimal redundancy: Redundant data should be minimized to reduce duplication and lower resource costs.
Flexibility: The schema should be adaptable to future changes, such as adding data types or modifications without extensive restructuring.
Performance: The integrated schema must support efficient query processing and data retrieval, maintaining high-performance levels even as the data volume increases.
Examples of schema integrations
Let's look at how different database technologies approach schema integration, demonstrating the practical strategies and tools that help meet these requirements for effective and scalable database management.
NoSQL example: NoSQL databases often use a flexible schema design for dynamic data structures. This flexibility makes it easier to integrate different data sources without the constraints of a fixed schema. However, because the schemas are so flexible—each data item can literally have its own schema—integrating the data sources into a single unified schema is complex.
SQL Server example: SQL Server uses views and stored procedures for schema integration. These tools abstract data from multiple tables into a unified view, providing a consistent interface for integrated data. SQL Server's support for common table expressions also helps consolidate and manipulate data from various data sources.
PostgreSQL example: PostgreSQL offers advanced features for schema integration, such as foreign data wrappers that provide access to external data sources as if they were part of the local database. This helps integrate data from different databases, supporting a unified schema across multiple systems. PostgreSQL's support for complex data types and JSONB also helps it handle diverse data structures in an integrated schema.
Database schema design
Database schema design involves a structured approach to defining how data is organized and managed within a database, which helps maintain data integrity, efficiency, and scalability.
What is a relational database?
A relational database is a type of database that stores data in tables related to each other through common data attributes. These relationships allow for complex queries and data manipulation while maintaining data integrity. Relational databases are based on the relational model, which organizes data into structured tables with rows and columns.
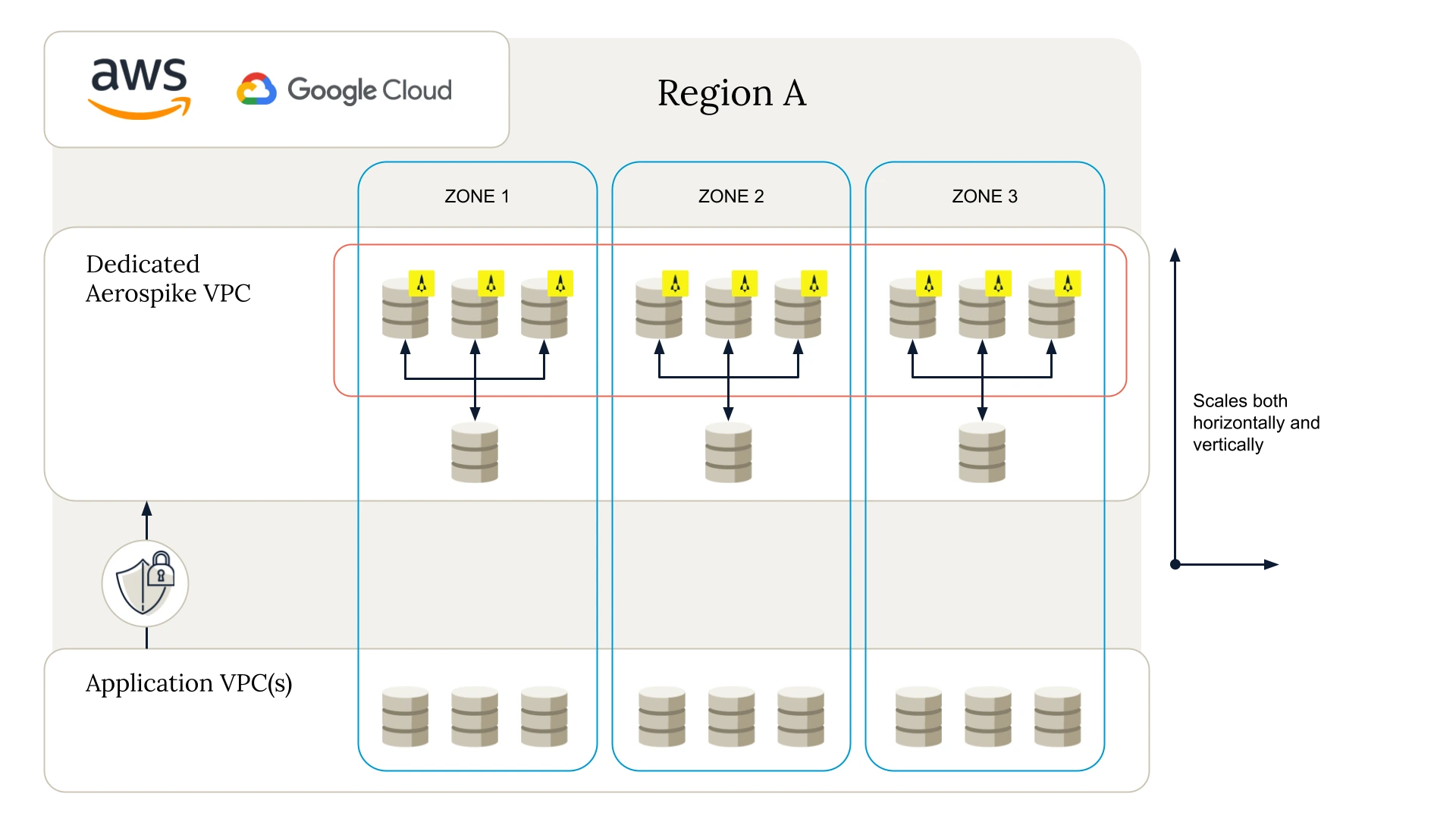
Steps to designing a database schema
Designing a database schema requires planning around business needs and data requirements. This involves defining entities, attributes, and relationships to support efficient data retrieval and analysis. For data warehousing, schema models such as the star schema are often used. By organizing data with a central fact table connected to dimension tables, the star schema optimizes performance for reporting and analytical queries, which is suitable for high-query environments.
Understand business needs
Analyze business processes and objectives.
Identify the data types to be stored and how they will be used.
Determine the volume and frequency of data transactions.
Define entities, aka tables
Identify the main entities or objects that need to be represented in the database.
Create a table for each entity, ensuring each table represents a single concept.
Assign a unique identifier, or primary key, to each table to distinguish individual records.
Define properties, aka fields
Determine the attributes or properties of each entity that need to be stored.
Define columns for each table, specifying the data type and constraints (e.g., not null, unique).
Consider future data needs and scalability when defining properties.
Define relationships
Identify how tables are related to each other based on business processes.
Establish foreign keys to represent relationships between tables and keep relationships between tables stay consistent.
Consider different types of relationships, such as one-to-one, one-to-many, and many-to-many.
In the figure below, the credit card payments table is considered to be the central fact table. It includes several measures of data credit card payment data, such as the percentage of full payments collected and the percent of minimum payments collected. In addition, it is attached to four dimension tables with additional information: location, date, credit card account, and customer group. Because the customer group includes items such as estimated income and age, business analysts can use these to answer questions to help their company make decisions, such as, “Are customers over the age of 40 more likely than customers under 40 to make full payments?”
Considerations for schema design
Normalization: Normalize the database schema to reduce redundancy while maintaining data integrity. This involves organizing tables and relationships to eliminate data duplication.
Denormalization: In some cases, denormalization—or allowing data duplication by storing it in multiple places to simplify and optimize access—may be necessary to improve query performance by reducing the number of joins needed.
Indexing: Use indexing strategies to improve query performance and perform data retrieval more efficiently
Comparison of schema design considerations
Aspect | Normalization | Denormalization | Indexing |
Purpose | Reduce redundancy | Improve query performance | Make data retrieval faster |
Advantages | Improves data integrity | Reduces join operations | Speeds search operations |
Disadvantages | May lead to complex queries | May increase data redundancy | Requires maintenance overhead |
Benefits of database schemas
While database schemas are less flexible, they can be important for efficient data management. They offer numerous benefits, including making databases work better and more securely.
Accessibility and security
Database schemas are important for data accessibility and security. Their structured frameworks mean schemas provide data retrieval and manipulation more efficiently so authorized users can access it more easily. Additionally, schemas establish security protocols, such as access controls and permissions, to keep unauthorized users from reading or changing sensitive data.
Access Control: Schemas let database administrators grant or restrict access to specific data tables or fields so only authorized personnel can view or modify data.
Data Integrity: Schemas enforce data types and constraints, maintaining data accuracy and consistency and keeping users from entering invalid data.
Administrator control
Database schemas help administrators control database management and maintenance. Schemas’ structure makes database updates, backups, and migrations simpler, minimizing potential errors and downtime.
Simplified management: Schemas simplify organized data categorization, helping administrators find and manage specific data sets.
Efficient updates: Clearly defined structures update databases systematically to keep the system consistent
Documentation
Well-designed database schemas serve as comprehensive documentation for database systems, demonstrating data architecture and relationships.
Schema diagrams: Visual representations of schemas help stakeholders understand the database structure, including tables, fields, and relationships.
Metadata: Schemas provide metadata that describes data properties, making it easier to understand and integrate data.
Optimization
Database schemas help make databases faster by making data storage and data retrieval more efficient, which is important in handling large volumes of data and complex queries.
Indexing: Schemas help create indexes, making data access and query execution faster.
Query Optimization: Structured schemas help make query planning and execution faster and more efficient.
Aerospike’s flexible schema approach
Aerospike, as a NoSQL database, is designed to be schemaless, giving developers the flexibility to adapt data without the hassle of complex schema migrations. That said, when integrating with SQL, Aerospike can work with schema-like structures through its SQL and JDBC adapters. These adapters infer schemas by sampling records for patterns or can use an existing schema if one’s already defined.
It’s worth noting that this schema handling happens at the adapter level, not in the database itself. Aerospike also integrates with tools like Trino, a powerful data aggregator, to make it easier to access and analyze data across different systems. This balance of flexibility and compatibility makes Aerospike a great fit for high-performance applications that need to handle both structured and unstructured data seamlessly.



What are database schemas?
A database schema is a structured framework that organizes data within a database. It defines how different elements, such as tables, fields, and relationships, are arranged to improve data integrity and accessibility. In database management, schemas are guided by a Database Management System (DBMS), software dedicated to creating, managing, and maintaining databases.
Schemas are categorized into two primary types: logical schema and physical schema. A logical schema represents the abstract structure of the database, focusing on elements such as entities, attributes, and relationships without considering physical storage. This high-level design helps database designers visualize and organize data conceptually. In contrast, a physical schema details the actual storage of data, emphasizing the underlying hardware and software infrastructure to optimize performance and storage efficiency. Understanding the distinction between logical schema and physical schema is important for database management to provide efficient data organization and reduce resources. The purpose of this blog post is to focus on logical schema.
While people often say that NoSQL databases such as Aerospike are “schemaless,” what they really have is a flexible schema. The advantages of a flexible schema are that they can store unstructured data such as imagery, and different records can have different types of data depending on user needs.
Database schema components
Integrating schemas from different data sources is important for any data management strategy. Schema integration combines multiple databases or data sources into one structure so users can retrieve and manage data as if it were within one database. This process helps validate data interactions while maintaining performance without affecting data integrity.
However, successful schema integration means meeting several requirements to help the schema be functional and scalable over time. This requires consistency, completeness, minimal redundancy, flexibility, and performance so that a well-integrated schema can handle a wide range of data sources and adapt to future changes.
Requirements for schema integration
Consistency: The integrated schema must maintain consistency across different data sources so data definitions are uniform and coherent.
Completeness: All necessary data from the source schemas must be included in the integrated schema so no information is lost.
Minimal redundancy: Redundant data should be minimized to reduce duplication and lower resource costs.
Flexibility: The schema should be adaptable to future changes, such as adding data types or modifications without extensive restructuring.
Performance: The integrated schema must support efficient query processing and data retrieval, maintaining high-performance levels even as the data volume increases.
Examples of schema integrations
Let's look at how different database technologies approach schema integration, demonstrating the practical strategies and tools that help meet these requirements for effective and scalable database management.
NoSQL example: NoSQL databases often use a flexible schema design for dynamic data structures. This flexibility makes it easier to integrate different data sources without the constraints of a fixed schema. However, because the schemas are so flexible—each data item can literally have its own schema—integrating the data sources into a single unified schema is complex.
SQL Server example: SQL Server uses views and stored procedures for schema integration. These tools abstract data from multiple tables into a unified view, providing a consistent interface for integrated data. SQL Server's support for common table expressions also helps consolidate and manipulate data from various data sources.
PostgreSQL example: PostgreSQL offers advanced features for schema integration, such as foreign data wrappers that provide access to external data sources as if they were part of the local database. This helps integrate data from different databases, supporting a unified schema across multiple systems. PostgreSQL's support for complex data types and JSONB also helps it handle diverse data structures in an integrated schema.
Database schema design
Database schema design involves a structured approach to defining how data is organized and managed within a database, which helps maintain data integrity, efficiency, and scalability.
What is a relational database?
A relational database is a type of database that stores data in tables related to each other through common data attributes. These relationships allow for complex queries and data manipulation while maintaining data integrity. Relational databases are based on the relational model, which organizes data into structured tables with rows and columns.
Steps to designing a database schema
Designing a database schema requires planning around business needs and data requirements. This involves defining entities, attributes, and relationships to support efficient data retrieval and analysis. For data warehousing, schema models such as the star schema are often used. By organizing data with a central fact table connected to dimension tables, the star schema optimizes performance for reporting and analytical queries, which is suitable for high-query environments.
Understand business needs
Analyze business processes and objectives.
Identify the data types to be stored and how they will be used.
Determine the volume and frequency of data transactions.
Define entities, aka tables
Identify the main entities or objects that need to be represented in the database.
Create a table for each entity, ensuring each table represents a single concept.
Assign a unique identifier, or primary key, to each table to distinguish individual records.
Define properties, aka fields
Determine the attributes or properties of each entity that need to be stored.
Define columns for each table, specifying the data type and constraints (e.g., not null, unique).
Consider future data needs and scalability when defining properties.
Define relationships
Identify how tables are related to each other based on business processes.
Establish foreign keys to represent relationships between tables and keep relationships between tables stay consistent.
Consider different types of relationships, such as one-to-one, one-to-many, and many-to-many.
In the figure below, the credit card payments table is considered to be the central fact table. It includes several measures of data credit card payment data, such as the percentage of full payments collected and the percent of minimum payments collected. In addition, it is attached to four dimension tables with additional information: location, date, credit card account, and customer group. Because the customer group includes items such as estimated income and age, business analysts can use these to answer questions to help their company make decisions, such as, “Are customers over the age of 40 more likely than customers under 40 to make full payments?”
Considerations for schema design
Normalization: Normalize the database schema to reduce redundancy while maintaining data integrity. This involves organizing tables and relationships to eliminate data duplication.
Denormalization: In some cases, denormalization—or allowing data duplication by storing it in multiple places to simplify and optimize access—may be necessary to improve query performance by reducing the number of joins needed.
Indexing: Use indexing strategies to improve query performance and perform data retrieval more efficiently
Comparison of schema design considerations
Aspect | Normalization | Denormalization | Indexing |
Purpose | Reduce redundancy | Improve query performance | Make data retrieval faster |
Advantages | Improves data integrity | Reduces join operations | Speeds search operations |
Disadvantages | May lead to complex queries | May increase data redundancy | Requires maintenance overhead |
Benefits of database schemas
While database schemas are less flexible, they can be important for efficient data management. They offer numerous benefits, including making databases work better and more securely.
Accessibility and security
Database schemas are important for data accessibility and security. Their structured frameworks mean schemas provide data retrieval and manipulation more efficiently so authorized users can access it more easily. Additionally, schemas establish security protocols, such as access controls and permissions, to keep unauthorized users from reading or changing sensitive data.
Access Control: Schemas let database administrators grant or restrict access to specific data tables or fields so only authorized personnel can view or modify data.
Data Integrity: Schemas enforce data types and constraints, maintaining data accuracy and consistency and keeping users from entering invalid data.
Administrator control
Database schemas help administrators control database management and maintenance. Schemas’ structure makes database updates, backups, and migrations simpler, minimizing potential errors and downtime.
Simplified management: Schemas simplify organized data categorization, helping administrators find and manage specific data sets.
Efficient updates: Clearly defined structures update databases systematically to keep the system consistent
Documentation
Well-designed database schemas serve as comprehensive documentation for database systems, demonstrating data architecture and relationships.
Schema diagrams: Visual representations of schemas help stakeholders understand the database structure, including tables, fields, and relationships.
Metadata: Schemas provide metadata that describes data properties, making it easier to understand and integrate data.
Optimization
Database schemas help make databases faster by making data storage and data retrieval more efficient, which is important in handling large volumes of data and complex queries.
Indexing: Schemas help create indexes, making data access and query execution faster.
Query Optimization: Structured schemas help make query planning and execution faster and more efficient.
Aerospike’s flexible schema approach
Aerospike, as a NoSQL database, is designed to be schemaless, giving developers the flexibility to adapt data without the hassle of complex schema migrations. That said, when integrating with SQL, Aerospike can work with schema-like structures through its SQL and JDBC adapters. These adapters infer schemas by sampling records for patterns or can use an existing schema if one’s already defined.
It’s worth noting that this schema handling happens at the adapter level, not in the database itself. Aerospike also integrates with tools like Trino, a powerful data aggregator, to make it easier to access and analyze data across different systems. This balance of flexibility and compatibility makes Aerospike a great fit for high-performance applications that need to handle both structured and unstructured data seamlessly.