Fast data access connector that enables businesses to use ANSI SQL to rapidly access and query data stored in Aerospike via Presto-Trino.
AEROSPIKE CONNECTOR FOR PRESTO-TRINO
Fast data access connector for Presto-Trino

No more slow, SQL-based data analyses
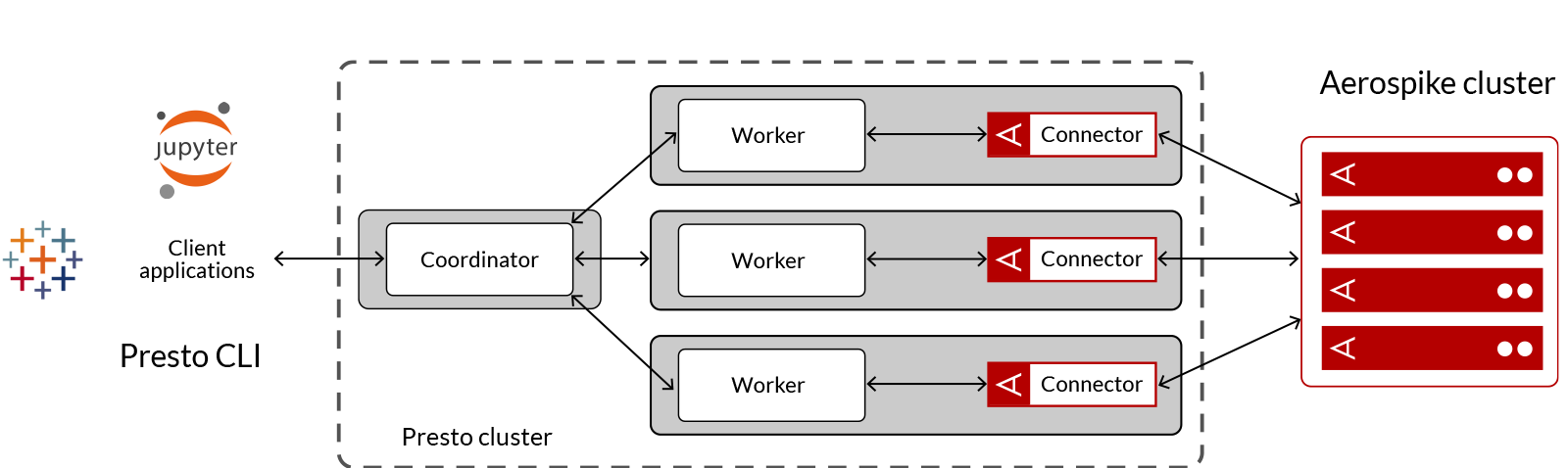
Real-time insights generated from always accurate, strongly consistent data are the foundation for smart business decisions. And Business Intelligence tools such as Tableau, MicroStrategy, Looker, or Qlik, which are staples in the business decision process, favor SQL as the language of choice for data analysts and data mining. The Aerospike Connect for Presto enables businesses and data analysts to use ANSI SQL to rapidly access and query data stored in Aerospike via Presto, a highly parallel and distributed SQL query engine.
Benefits
Why Aerospike Connect for Presto
Run ANSI SQL queries in-place on massive amounts of data stored in the Aerospike real-time data platform without complex and error-prone processes of copying data unlike other analytics systems.
-

Easy Integration with BI Tools
Analyze data stored in Aerospike through your favorite Business Intelligence tools like Tableau, Qlik, Looker, and many more for visualization and reporting. -

Build AI/ML Models
Move quickly from proof-of-concept to production of AI/ML models by pre-processing data stored in Aerospike using Python to create powerful models using popular libraries like Pandas, NumPy and Scikit-learn. -

Accelerate Time to Insight
Drastically reduce time to insight by combining Aerospike’s massive parallelism for speeding up interactive and ad-hoc Presto queries. -

Deploy with Ease
Deploy the Presto Connector using Docker containers to enable the analysis of datasets running queries on ANSI SQL.
Key features and capabilities of Aerospike Connect for Presto

Run ANSI SQL queries on massive amounts of data in-place
Query data stored in Aerospike without the need for complex and error-prone processes of copying data over to other analytics systems, which significantly helps with governance and compliance.Federate queries across multiple Aerospike clusters or between Aerospike and other databases
Enterprise database deployments are typically polyglot in nature, but you can now deploy Aerospike into an ecosystem of DBs that consist of Cassandra, PostgreSQL, Oracle, and others.Analyze Aerospike data via common BI tools
Create insightful dashboards using Tableau, Qlik, Looker, etc., by accessing Presto over JDBC to analyze data stored in Aerospike.Supports massive parallelism
Supports massive parallelism by allowing you to use up to 32,768 Spark partitions to read data from an Aerospike namespace. Each namespace can store up to 32 billion records across 4,096 partitions.Query records with different schemas within the same set in Aerospike
Aerospike is a NoSQL schemaless database, but Connect for Presto reconciles those differences and offers a SQL experience that you are familiar with, while leveraging the benefits of a NoSQL database.Leverage massive parallelism of Aerospike for speeding up queries
It can scan 4,096 partitions in parallel to load data into and up to 32K Presto splits across your Presto cluster and uses the recently released Aerospike expressions for pushdowns to the database.Leverage Presto Cost Based Optimization (CBO) via row count for query optimization
Aerospike Connect for Presto is one of the few Presto connectors that supporting CBO for speeding up Joins in Presto.Deploy anywhere
Deploy in cloud or Kubernetes environments to help you leverage Managed Presto Services offered by multiple Cloud providers.Learn more about Connect for Presto
Use Cases
Enhance your analyses across multiple use cases with Aerospike Connect for Presto
Aerospike Connect for Presto makes it easy for enterprises to address various use cases by utilizing ANSI SQL to query data stored in Aerospike and other databases via Presto.
Interactive Queries
Run interactive queries to generate insights for business-critical decisions using large data sets using Presto CLI or any SQL editor that supports Presto JDBC drivers.
BI Dashboarding
Use BI tools such as Tableau, Looker, or Qlik, to connect to Presto and analyze data stored in Aerospike and create real-time dashboards and deliver high-quality data insights quicker than before.
Data Preparation for AI/ML
You can analyze data stored in the Aerospike Database via Presto using the Jupyter Notebook with the PyHive Presto Python library. Create AI/ML models using popular Python libraries such as Pandas, NumPy, or Scikit-learn, and quickly progress from proof-of-concept to production.
Resources
Learn more about Aerospike Connect for Presto.




