
Telcos all over the world have been commercially deploying advanced technologies related to AI/ML.
Still, a lot more can be done.
A recent report from telecom consultancy firm STL Partners of more than 150 processes across network operations, customer channels and sales & marketing, found that telcos can reap financial benefits amounting to more than 8% of annual revenues by leveraging analytics, AI, and automation. According to STL, this value is measured on a yearly basis in dollars and as a proportion of total revenue for a “standard telecoms operator”. The value, both in terms of cost reduction and new revenue generation, is realized through a wide variety of components that include network planning/operations automation, services personnel optimization, revenue assurance, and customized cross-selling/up-selling.
AI/ML and data
It’s not exactly news anymore that any industry can benefit from intelligent implementation of AI/ML.
Our solution brief articulates the role of data, and more specifically, data preparation, in a successful AI/ML operation. Machine learning models run better with more data and fast data. The more iterations and the more training, tuning and validation you can do within the target time window, the better the results. Across the data science community, the consensus is that the key challenges lie in data preparation and model creation and tuning (combinedly referred to as “plumbing”) as models are constantly evolving. This relates to the classic “Garbage In, Garbage Out” argument and highlights the role of “High-Quality Data” in AI/ML operations.
The Aerospike advantage
Aerospike’s real-time data platform is designed to ingest large amounts of data in real-time for parallel processing, while also connecting to compute platforms and notebooks and ML packages. In terms of data volume, our “Petabyte Scale Benchmark” paper summarizes how, in collaboration with Intel and AWS, we ran operational workloads at petabyte scale in AWS on just 20 nodes. On the speed dimension, in the same benchmarking exercise, we realized >5M TPS (<1 ms latency in 100% cases) for 100% read workload and a combined ~4M TPS for 80/20 read/write workload.
This kind of industry-leading data volume and speed numbers matter when you move data between the Aerospike Database and use Aerospike Connect for Spark in a massively parallel fashion. Once the data is in the Spark DataFrame, you can bring to bear any of the popular AI/ML libraries and frameworks of your choice to create highly performant AI/ML models based on the use case. Further, you can explore data in Aerospike using Jupyter or Apache Zeppelin notebooks, leveraging Spark’s built-in support. The beauty about this architecture is that it separates compute (Spark) and storage (Aerospike) so that you can right-size them independently to achieve lower TCO. Last but not least, you can deploy it anywhere with Kubernetes (using Aerospike Kubernetes Operator) and Docker.
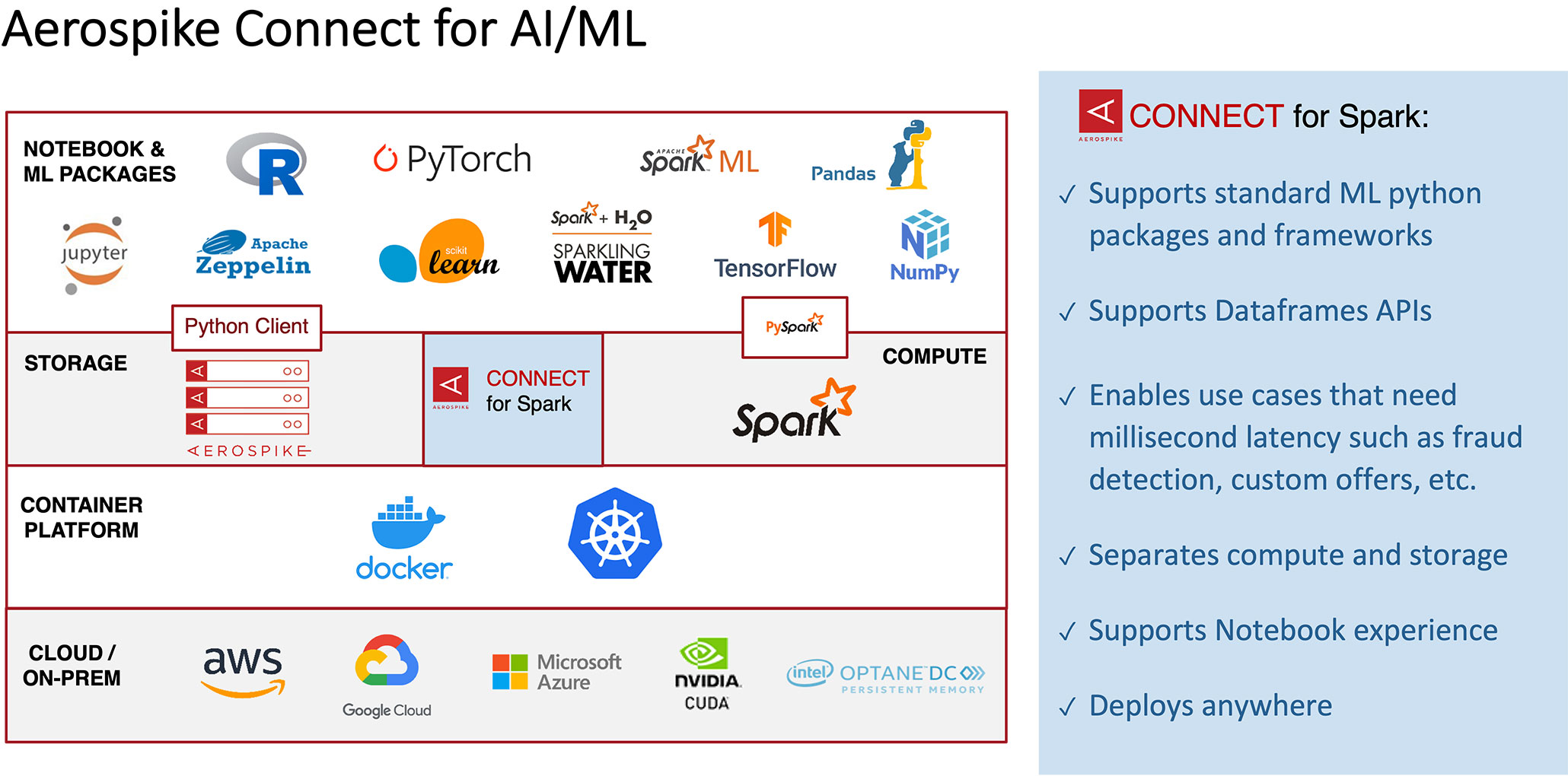
The sequence of tasks that the Aerospike real-time data platform performs to close the loop of an AI/ML operation end-to-end is summarized in our solution brief. Specifically, it helps with loading the training data, preparing and exploring that data as well as creating an AI/ML pipeline. In this scenario, the Aerospike real-time data platform serves as the system of record (SoR) database with the ability to store up to petabytes of data.
The Aerospike SoR database accomplishes these by taking advantage of our deep experience of working with the Spark ecosystem, including the best-in-class (i.e. fastest available) Spark connector that we provide (i.e. Aerospike Connect for Spark). Consider:
For loading the training data, Spark and our connector for Spark are used to load the data from AS SoR into Spark Dataframes.
For data preparation, Spark jobs for cleansing, enriching, transformation, and pre-processing (e.g. normalization) are run in a very I/O intensive manner. Further, for data exploration, analysis and understanding of data take place as it’s a key aspect of the AI/ML pipeline – you must understand your data before feeding it to AI/ML models (thus using Jupyter or Zeppelin notebooks to do so).
For creating an AI/ML pipeline, the enriched/transformed data is made available to the AI/ML platform via the Spark APIs. Any Spark DataFrame-to-ML package conversions take place here.
Still, our role in the AI/ML value chain does not end there.
Creating a low-latency inference pipeline
Aerospike can also create a very efficient, low-latency inference pipeline. The way we do it is by ingesting data from disparate data sources into an edge data system (composed of the Aerospike Real-time Data Platform using an Aerospike C client). Aerospike’s edge database can:
Optimize the ingest rate for millions of events per second so that the SoR DB that runs AI/ML or analytics workloads can catch up.
Run queries at the edge to check the applicability of the ingested data.
Filter out unnecessary data while preserving as much of the native dataset as possible.
Allow multi-site clustering where datasets at multiple physical sites behave as a single cluster of data.
Streaming source for Spark
It’s worth mentioning that along with the Aerospike database, Kafka can also be used as a streaming source for Spark.
The diagram below shows an Aerospike inference pipeline involving Aerospike data platforms (both as edge system and as system of record), Kafka and Spark.
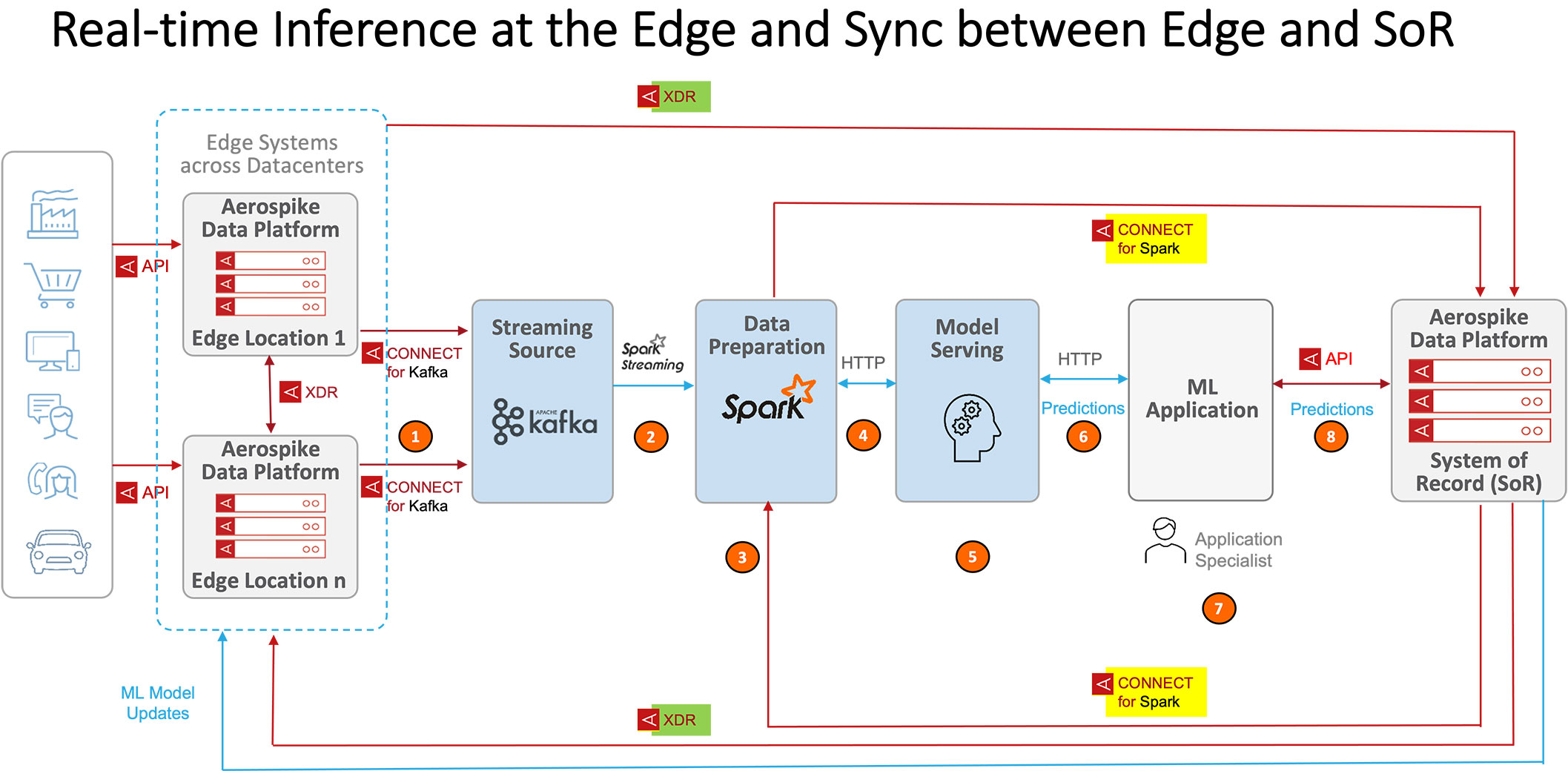
Cross-Datacenter Replication (XDR) and Spark Connector for AI/ML
Apart from our high performance and massive volume support – and the best-in-class “Aeropsike Connect for Spark” (labeled in yellow in the figure) – there is another crucial element that makes our AI/ML story more powerful. That’s the Cross Datacenter Replication (XDR) feature enabled between the edge data system and SoR database (labeled in green).
This XDR works like magic and syncs the two data systems (at the edge and at the core/SoR) in near-real time, where the only impact (in terms of latency) comes from the physical network connectivity across deployment locations. Through XDR, we can make sure that the latest events captured at the edge are made readily available to the SoR from which the data loading, preparation and subsequent steps happen to accomplish the AI/ML jobs. The bidirectional nature and filtering capabilities (to select which data and data attributes should be allowed to pass) add additional layers of flexibility to the data flow.
Our AI/ML capabilities are not static. Apart from the relevant core functionalities of the database itself, there are constant upgrades happening, especially on the Spark side to stay ahead of the competition.
Basically, where we (Aerospike/Spark combo) shine is where the models are very “data hungry,” requiring massive amounts of inputs. In addition, there is the ultra low-latency, i.e. fast response piece. When we have a short time window to do a test using a model, a super-fast database can be the difference between completing the task inside (pass) or outside (fail) of the stipulated window.
Quite obviously, this resonates well in many financial services use cases. One of our clients looks up on average 200 pieces of data per good/bad transaction decision that needs to be done in 350ms. So, if you’re not returning each read on average in under 2ms, you will be outside the Service Level Agreement (SLA).
Many Telecom use cases
Now, we can make the same argument for many telecom use cases. In the emerging area of Multi-Access Edge Compute (MEC), commonly referred to as telco edge in the telecom context, an often-cited use case is real-time cross-selling/up-selling in online gaming. The idea is to analyze the gamer’s in-game engagements in real-time, extract intelligence and act on that in the form of cross-selling/up-selling offers while the user is still playing games and engaged with the edge application. Quite understandably, telecoms would like to automate these tasks (in this case, personalized offers) based on the latest AI/ML algorithm. The success of that algorithm will depend, in large part, on the fast response of the underlying data platform. Other telecom use cases that are very strong candidates for such AI/ML based improvement/tuning would include fraud detection and churn prediction.
If you are thinking of introducing telecom edge use cases with market-leading AI/ML capabilities, we would like to hear from you and work with you by leveraging our work on both telco and non-telco areas. In the non-telco space, we have established references of customers running sophisticated AI/ML models on our data platform for fraud/identity management and personalized recommendation type use cases. We see direct relevance of those use cases (and many more) in the telecom space.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works