
Data Science teams have the singular goal of building the most performant ML model in production. However, a model that is deployed in production is only as good as the data it’s trained with. In recent years, a Feature Store has gained momentum in the MLOps domain.
Why do you need a feature store?
A feature store serves data to your machine learning (ML) models to help accelerate your production readiness. Features can be in their raw form or pre-processed (cleaned, transformed, and/or reduced). In principle, you should be able to store data in both forms in a Feature store. Data is ingested in the raw format from disparate sources and then pre-processed using different data processing platforms such as Spark or Python libraries. For example, for a naive model that is based on linear regression to predict the desired salary (target variable), you can use “age” as a feature as shown in Figure 1. To improve the accuracy of the model, you could consider using “experience” and perhaps “job location” as features as well as a part of the feature selection step.
Figure 1: Using “age” as a feature for an LR model
Data science teams spend roughly 80% of their time on areas not related to model development and feature engineering represents a major component of that effort. Since the time investment is huge, you would ideally want to persist its output (i.e. features defined and selected during feature engineering) into a performant data store so that it can be leveraged cost efficiently by the wider data science audience within your company for operationalizing future ML models. This not only maximizes reusability but also streamlines data governance and compliance since there is a single source of truth for features within your company.
The features used for training a model must match up with the features used for online serving. Additionally the distribution of feature values must also be similar for best performance. Any mismatch introduces training/inference skew, which significantly impacts the model performance in production. A Feature Store provides a consistent view across training and inference stages to make training/inference skew a tractable problem. Above all, a Feature Store simplifies the feature discovery process to help significantly boost the productivity of your Data Science team.
A Feature Store architecture consists of online and offline stores for storing data. The online store has stricter latency requirements (millisecond IOPS) and is typically used to store recent data for online predictions or inference. It could also be used for batch predictions depending on the use case. On the other hand, an offline store has stricter throughput and scalability requirements and is extensively used for batch model training, analytical applications without realtime requirements and exploratory data analysis. The data moves from online to offline stores to keep the training data current to help address data drift. There are also scenarios where data from offline store is utilized to enrich the data in the online store. For example, for a propensity model you may want to enrich a user profile based on the historical spend pattern to accurately predict the target’s likelihood of responding to an offer. Further, a Feature Store also consists of a metastore to store features related metadata such as feature versions, associated models, creation time, etc. to accelerate the feature discovery process. A well designed Feature Store offers an easy to use serving interface via APIs, HTTP endpoints, etc.
Why use Aerospike as a feature store?
The purpose of this blog is not to provide a comparative analysis of various Feature Stores, but rather to present the reasons why Aerospike customers have been successfully using it as a Feature Store.
High throughput, low latency data access
Aerospike database is a highly scalable NoSQL database and its **Hybrid Memory Architecture** makes it ideal for AI/ML applications. It is typically deployed into real-time environments managing terabyte to petabyte data volumes and supports millisecond read and write latencies. It leverages storage innovations such as PMem or persistent memory from best of breed hardware companies such as HPE and Intel. By storing indexes in DRAM, and data on persistent storage (SSD) and read directly from disk, Aerospike provides unparalleled speed and cost-efficiency demanded by an AI/ML pipeline at scale.
Aerospike is typically used as an online store because it offers sub-millisecond read and write latency at scale and cost effectively. See the petabyte scale benchmark in AWS for more information. However, it could also be used to serve as an offline store because of its ability to support millions of IOPS. So, this offers you the convenient option to use the same database for both online and offline stores by changing the hardware configurations based on the price/performance considerations. Cross-Data Center Replication (XDR) ensures that data remains consistent across the offline and the onlines stores. A metastore could be modeled as a key-value datastore for fast metadata lookups. That makes Aerospike a good fit for the metastore as well.
Seamless interoperability with the border big data ecosystem
Aerospike database can be deployed alongside other scalable distributed software such as Kafka, Trino, Pulsar, Spark, etc. via the Aerospike Connect product line to enable you to build a performant Feature Store. Figure 2 represents the building blocks that span three key pillars of a Feature Store i.e. ingestion, feature engineering, and serving, that are built on top of a strong foundation like Aerospike database.

Figure 2: Pillars of a Feature Store
Apache Kafka or Apache Pulsar serves as an unparalleled streaming platform for data ingestion. The streaming connectors shown in the integration column of Figure 2 enable low latency and high throughput data movement in and out of Aerospike seamlessly for your respective use cases. Additionally, you can use the Message Transformer for performing lightweight transformations such as encryption, format conversions, etc. on messages as they stream in or out of the Aerospike database. This offers great flexibility to featurize raw data or pre-process existing features. If you plan to ingest data from Mainframe or DB2 for your fraud detection models, you can use Aerospike Connect for JMS to build a performant ingestion pipeline.
Apache Spark is considered to be second to none for feature engineering. Aerospike Connect for Spark enables your Spark application to read from and write to Aerospike easily using the familiar Spark DataFrame APIs. Further, data scientists can discover and analyze the features relevant to their models using Jupyter Notebooks. If SQL is your language of choice for feature discovery, you can use Trino and the Aerospike Connect for Presto.
The recently announced Aerospike Connect for ESP provides the ability to stream Aerospike change notifications (CDC-like) to HTTP endpoints and offers flexibility to transform inflight messages using the outbound message transformer. This will help you push a feature vector from the Feature Store to your inference server that exposes a REST endpoint. Alternatively, you can also pull features from the Feature Store using the Aerospike REST gateway.
Rich programming model
Aerospike offers a rich programming model for documents via CDT and key-value models, not to mention Aerospike expressions for powerful query capability. This comes in handy to address the feature leakage problem. Feature leakage is caused when you use data in model training that wouldn’t be available at the time of prediction. CDT allows you to model point in time data sets to keep feature values in the future from impacting the model accuracy. For example, If a patient was diagnosed as COVID positive on day=day_3, all feature values for pulse rate and body temperature for day > day_3 are irrelevant for a COVID detection model. So, you can query and create a new data set with pulse rate and body temperature values for days <= day_3. Figure 3 depicts the concept visually.
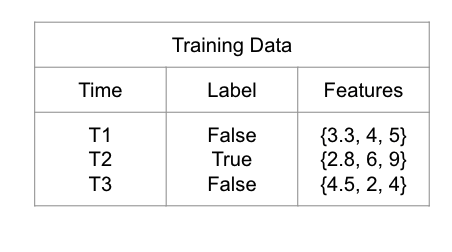
Figure 3: Point in Time feature set to address Feature leakage
Global scale with local optimization
By leveraging Aerospike’s multi-site clustering capability, you can basically create a Feature Store that stretches across multiple geos to help localize your AI/ML models. For example, if you have your Feature Store cluster spanning the US and Spain regions, you can combine certain features pertaining to the US consumers with the retail data pertaining to the Spanish market to derive new training sets that can be used to predict fashion trends in the Spanish market. In this case, a Feature Store with Aerospike cluster configured for Strong Consistency (SC) and multi-site clustering guarantees that all writes will be replicated across sites without data loss. ML applications can be configured to read with low latency from the local nodes running nearest to them. An entire copy of the cluster’s data is available in the nodes in your regions. This could be extended to other use cases such as cross-border e-commerce fraud detection.
If you put all the above building blocks together, this is what the high level architecture would look like conceptually as shown in Figure 4:
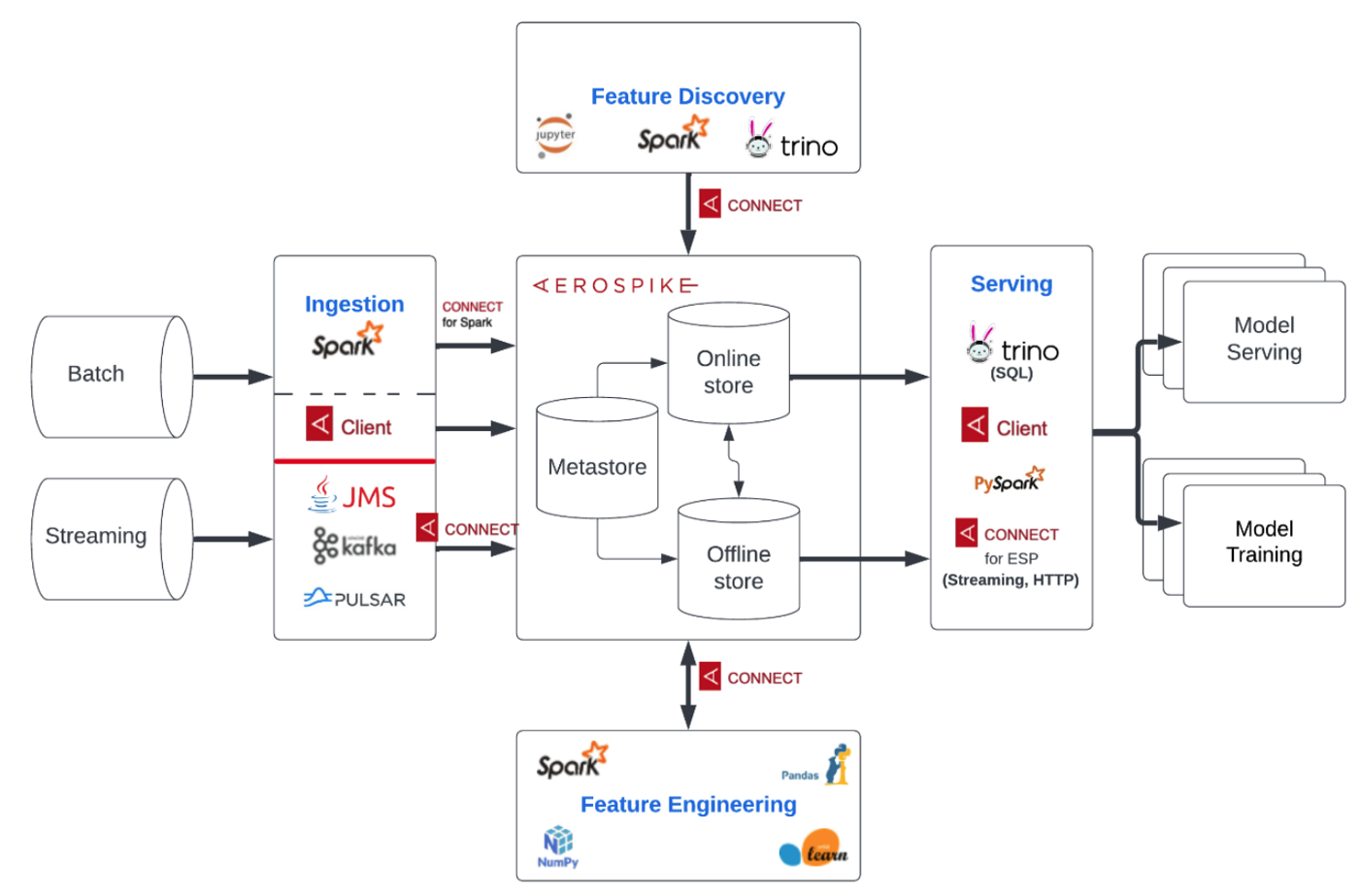
Figure 4: High Level Architecture (Conceptual View)
Aerospike feature stores in production
Here are a few examples of how Aerospike has been successfully deployed as a Feature Store in production environments.
Quantcast’s large-scale real-time feature store
Quantcast specializes in AI-driven real-time advertising, audience insights and measurement. They were looking to build an online Feature Store to help decision making around which Ads to show and how much to bid. The requirements that were shared with Aerospike were as follows:
Records: 10 Billion
Data storage: 8TB
Lookup latency: <=2ms
Lookups/Sec: 1 Million
Updated/Sec: 200K
As depicted in Figure 5, the personalized advertising platform involved ingesting audience’s attributes that represented an Ad opportunity, featurizing them, and writing them to the Aerospike database, which was set up as an online Feature Store. The feature sets were queried and enriched using the historical data stored in the offline Feature Store, and later fed to various ML models after some pre-processing. The ML models would essentially match up the user with the Ad unit based on several predetermined features to make the Ad targeting contextual. Based on the data shared in July 2020, the whole pipeline ran with an end to end latency between 20 (min) to 100 (max) milliseconds with Aerospike offering a p95 lookup latency of 2 milliseconds (down from 10 milliseconds in their legacy system). Further, they were able to meet their reliability criteria with 100% write success rate.
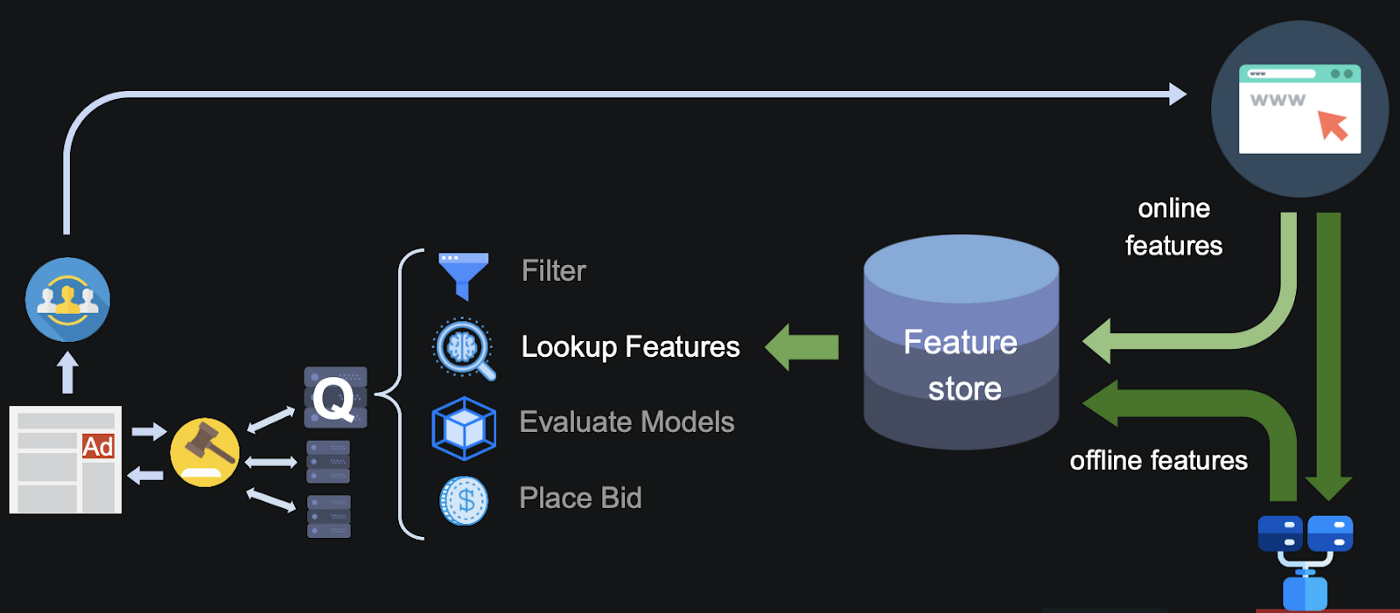
Figure 5: Quantcast’s architecture for supporting personalized advertising (Source: Quantcast at Aerospike Summit’20)
Powering Playstation personalization to millions
Sony PlayStation has been wowing gaming enthusiasts like myself for decades with their immersive gaming experience. I was thrilled to learn that Aerospike database serves as the online Feature Store for PlayStation’s personalization services platform. They did extensive benchmarking with competitive products before choosing Aerospike to support them with the following requirements for their feature store:
Users: 100+ million
Data storage: 5TB+
Features per user: 100+
Data retrieval: <10ms
Low TCO
As shown in Figure 6, the Machine Learning Platform engineers features using Spark and writes them to the Aerospike online Feature Store using the Spark connector. Subsequently, the PlayStation Services consume those features using Kafka and feed them to the various ML models for predictions.
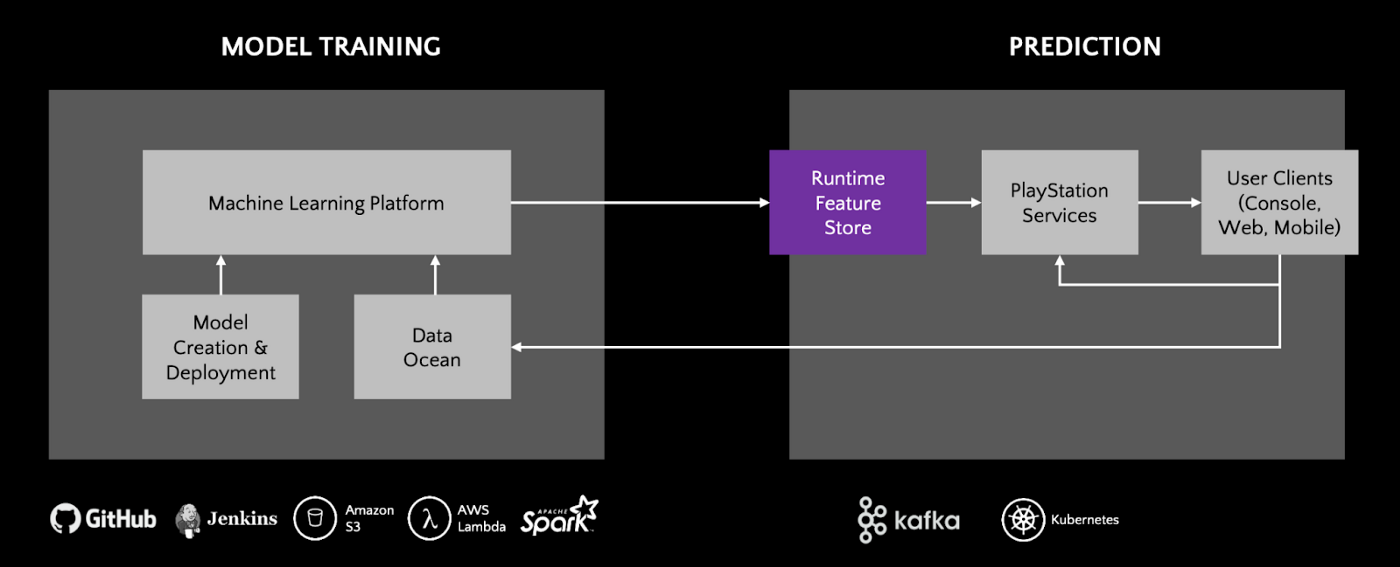
Figure 6: Sony’s architecture for supporting PlayStation personalization services (Source: Sony at Aerospike Summit’20)
Myntra’s home page personalization
Myntra, a major Indian fashion e-commerce company, was looking to personalize the user experience on their webpage by deploying a personalized ranking model that re-ranks the home page targeted cards(widgets) for their millions of users. They discovered that the feature look up was taking much longer than model prediction and was consequently leading to poor user experience. Hence, they decided to accelerate the feature lookup by switching to Aerospike database. They deployed it successfully and were able to improve the customer-experience, click-through rate (CTR), and subsequent revenues.
The details of Myntra’s journey with Aerospike were shared by Sajan Kedia from Myntra at the MLOps Conference.
What’s next?
The building blocks for architecting a highly performant Feature Store exist in the Aerospike platform. You can use it to drive AI/ML applications that matter to your business.
You can either partner or build additional features on top of Aerospike as a feature store to boost the productivity of your data science teams. Here are a few ideas:
Feature recommendations to automatically recommend new features to Data Scientists that are relevant to their models and notify them of new updates.
Feature drift detection to automatically check stored feature sets for drift over time and alerts users. Alerts can be used to trigger retraining to keep models accurate.
Feature versioning to test models with a particular version, and potentially learn from past features.
Feature security and RBAC for controlling access to sensitive features for compliance.
If this blog has inspired you to pursue your innovative ideas, please download the relevant Aerospike connector, full-featured single-node Aerospike Database Enterprise Edition, and refer to our documentation and below resources for a seamless trial experience.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works