Blog

As the world adapts to the virtual, online mode of streaming data, a mighty crowd gathered to learn about the underpinnings of how to manage said streams; the 2020 Kafka User Summit, held online August 24-25. So why did 30,000 plus folks register to learn the latest; what is the latest, and why did Aerospike choose to sponsor and present?
Why is Kafka so important in 2020?
As we’ve all noticed; an incredible amount of day to day life; both work and personal is now online, and the demand for stream processing is increasing every day. Thinking about only the volume of data is not sufficient — but processing data at faster rates and making insights out of it in real-time is very essential so that organizations can react to changing business conditions in real-time.
And hence, there is a need to understand the concept “stream processing “and technology behind it.
Ergo; the many sessions offered at the (fully virtual) Kafka Summit 2020. The sessions; now available online, covered a full range of topics from technical and industry trends fueling Kafka’s growth as well as examining future-ready architectural changes to both the data and control planes.
While the sessions looked at a host of fascinating use cases; new digital-native (Nuuly), online travel (Expedia), global banking (Citigroup), or retail business (Lowe’s), one that cut to the heart of the “what should I be doing’ that drives attendance at events like these, was a deep dive into the principles and trade-offs between Kafka, distributed log systems other Kafka-like messaging hubs. Their benchmarks summary is really useful when you’re thinking about what you might need to accomplish in your organization. (You know how we love benchmarks. But not bad ones.)
We also appreciated the ‘take a step back’ thought provoking session by Sam Newman whose Tyranny of Data talk suggests tech leaders rethink the data infrastructure to ensure that data works for us, rather than us for it. Hear here! Finally, a shout out to the organizer of this event, Tim Bergland, who gave the closing keynote and summary of his highlights (which he kindly put up on YouTube for easy access.)
Why Aerospike and Kafka?
As Aerospike’s mission is delivering the absolute maximum value (at the exact moment it’s needed) from vast amounts of data at the edge, the core and in the cloud; connection is a key compliment to our unique architecture. And as we wrote in our blog before the conference, one of Aerospike’s superpowers is fast data access, so it is no surprise that it is often part of a larger event-driven architecture consisting of one or more data stores, messaging systems and information processing systems at companies who are capably planning for streaming at scale.
In our session “Distributed Data Storage & Streaming for Real-time Decisioning Using Kafka, Spark and Aerospike” our Director of Product Management Kiran Matty showed an eager audience just how possible it is to eliminate the wall between transaction processing and analytics by synthesizing streaming data with system of record data, to gain key insights in real-time. (Note: you will have to “register” to watch this session at present time – but it is free.)

When asked for his perspective on using Kafka connectors vs others, he answered “We do not want to be prescriptive with which connector our customer should use. It is guided by the use case and their architecture. Of course though – we can definitely suggest a technology if the customer is early in the deployment cycle.”
Matty continued “Kafka is ideal for smaller messages and enjoys a pretty broad ecosystem of connectors. However, competitive technologies such as Pulsar also have their pros as well. Whichever messaging technology they choose, Kafka, JMS, or Pulsar, we have a connector for it.”
But at the end of the day; for this audience making choices about designing a streaming platform, it’s all about latency – you want to reduce the latency as much as possible. And since Kafka is estimated to be the connector of choice in nearly 80% of enterprise companies today; it has to be low latency across a host of different types of databases…. Systems of Records; Systems of Engagement; Systems of Insight. For companies dealing with legacy mainframes, and a host of disparate repositories of mission critical data, having the right connectors and the right modern data layer is the key to future success.
But seeing is believing; so if we’ve been enticed to read this far about the summit; let us leave you with an invitation to watch the demo we presented at the event. In this ‘no registration required’ demo you’ll see George Casaba, Aerospikes Director of Technical Product Marketing highlight how our Kafka Connectors fit into Inbound and Outbound Kafka configurations; as well as discussing how Aerospike and Kafka are ideally suited for use cases that are crucial to enterprises.
To summarize what you’ll see in the demo:
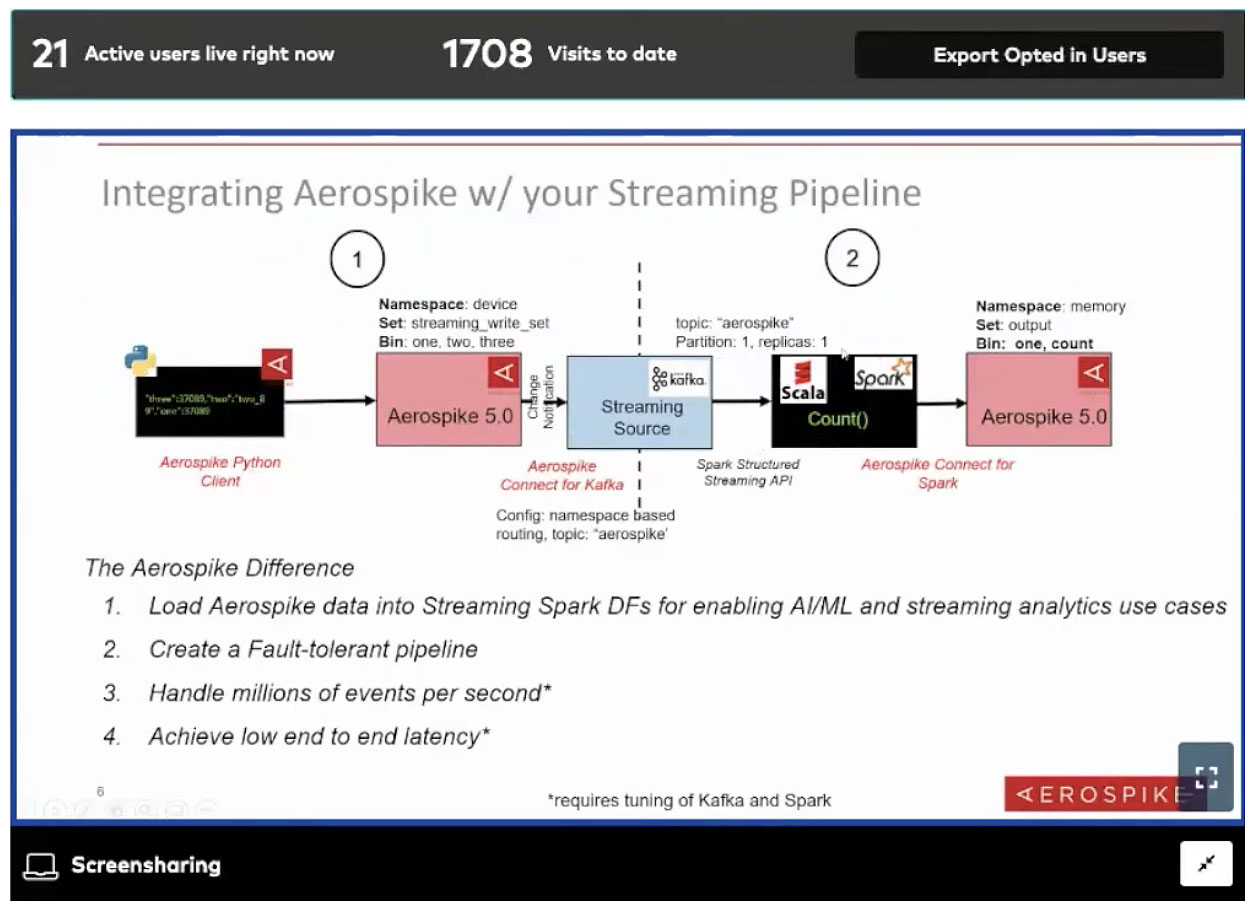
An overview of Aerospike Database 5.0 to see how it can be used for low latency writes via a Python client of up to one hundred million data points, which is further streamed via Change notifications to downstream Kafka system via the Kafka connector using the new XDR protocol in Aerospike 5.0
An overview of Aerospike Connect for Kafka and Spark
A live demo using Aerospike Python Client where we push one hundred million data points into the Aerospike database.
We see data that has been collected, analyzed (counted), and pushed back in real time into Aerospike, showing a histogram of how many times a specific number occurred and for each value in the one bin or column.
While it is by design very basic, we hope that our audience will use this demo as a baseline and create interesting applications that include AI/ML and real-time analytics.
If you are more of a reader than a video watcher, may we also invite you to see our Aerospike Connect for Kafka.
And… watch this space for new news about key connectors coming on September 15.
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog