Revolutionizing storage IO: The best just got better
The new partial flush feature and essential server configuration changes in Aerospike 7.1 are powerful tools for optimizing performance.

Aerospike Database 7.1 takes a big step forward in improving storage IO, building on our commitment to making the best even better. In this blog, we dive into the benefits of the new partial flush to storage IO feature introduced in this release. Whether you're new to our software or have been with us for a while, if you're considering upgrading to version 7.1, it's essential to understand the necessary changes to the server configuration. This knowledge will help ensure a smooth transition and that you get the most out of the latest enhancements.
Storage IO in Aerospike
Aerospike epoch, Jan 1, 2010, ushered in a new era in database storage. Our founders, Brian Bulkowski and Srini Srinivasan, were true visionaries who were way ahead of the prevailing design practices.
SSDs were quite expensive and not the storage medium of choice. Spinning disks with storage via a file system and network-attached storage were the preferred choices. Expecting SSDs to become ubiquitous in the future, Aerospike was envisioned from the ground up to store data on SSDs, treating them as raw block devices, with data written to SSDs directly without the need for a file system, in a log-structured fashion.
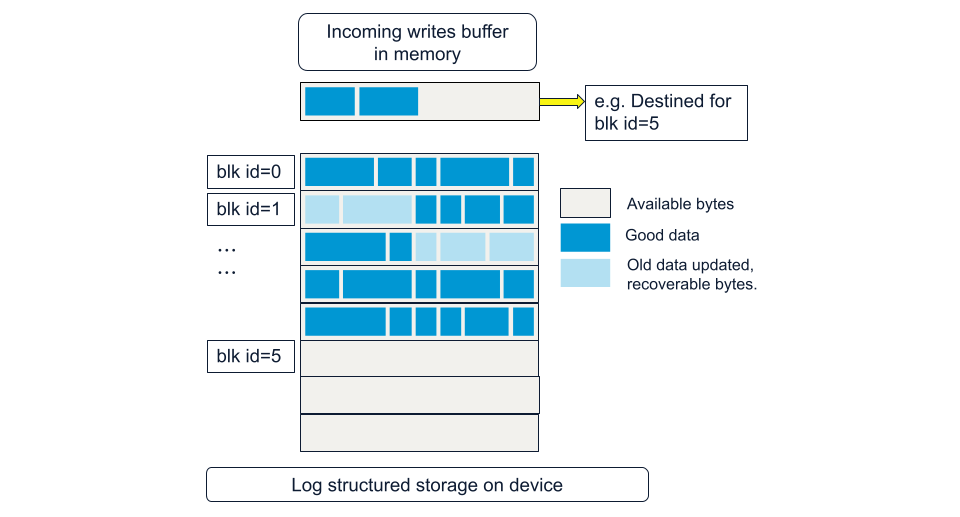
The option to store via the file system was still provided for those who might still want to deploy to file storage. However, the blocks written to files still followed the same structure as writes to SSD as raw block devices. The file system was a last stage intermediary between storage and Aerospike if users so wished.
The device is viewed as a bunch of write-blocks, each having a block-id. Super fast record writes are achieved by writing to a current in-memory buffer with an associated block-id tag, called the streaming-write-buffer (or SWB). When full, it is flushed to the target block-id.
This raises questions about durability. What if the server node "dies"? Is data acknowledged as "written" to the client, lost? After all, we wrote to an in-memory buffer.
This is indeed a legitimate concern and is mitigated by choosing a replication factor (RF). The record write is replicated to another node and written to its SWB before being acknowledged to the client.
It does leave the possibility of both nodes going down simultaneously, resulting in data loss. For those concerned, RF>2 is an option. Additionally, you can configure namespaces in rack-aware configuration and lose more than 1 node in the same rack simultaneously without losing data.
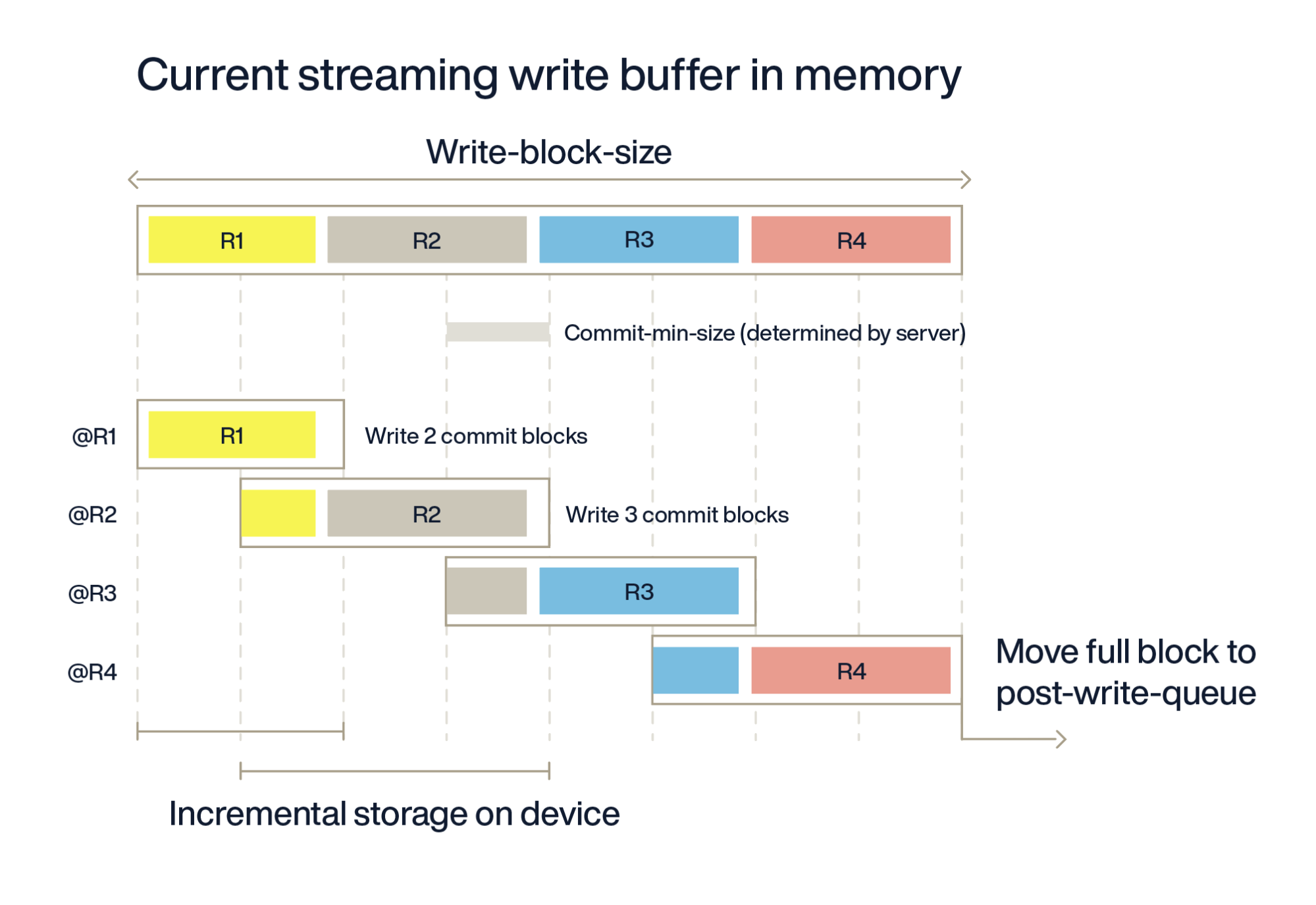
For the most strict users, Aerospike offers the strong consistency mode of a namespace configuration, with the option to flush to device on every record write (shown below as R1, R2, etc.) before acknowledging to the client. It is enabled by setting commit-to-device to true. As many commit-min-size blocks needed to cover the record are flushed as shown below for, e.g., R1, R2, and so on (commit-min-size was deprecated in version 7.0. Its previous default of 0 is now the implementation. i.e., determined by the server as the smallest size for the storage device, typically 4KB for SSDs, 512 bytes for file storage).
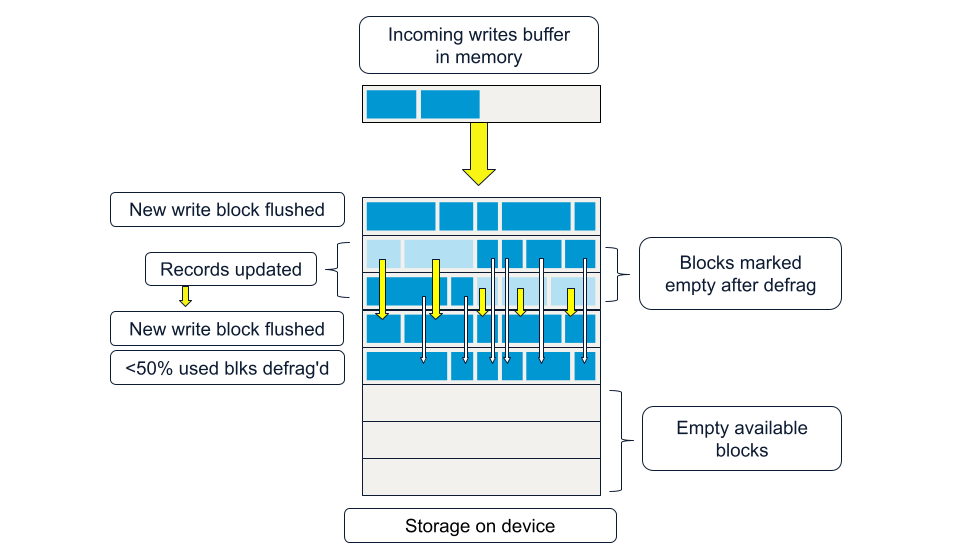
The other issue is, since the block is only flushed when full, what if you have slow writes? By slow writes, we mean it takes multiples of flush-max-ms worth of time to fill the entire write-block-buffer. There is an additional configuration parameter, flush-max-ms (1000 ms) default. If the SWB is sitting around waiting to be filled, it is flushed, partially full, as many times as necessary, every 1000 ms, till it is full, then one final time. This causes the SSD controller to deal with defragmentation on the device, but from Aerospike's logical view of the drive, it is an overwrite of the same block-id multiple times.
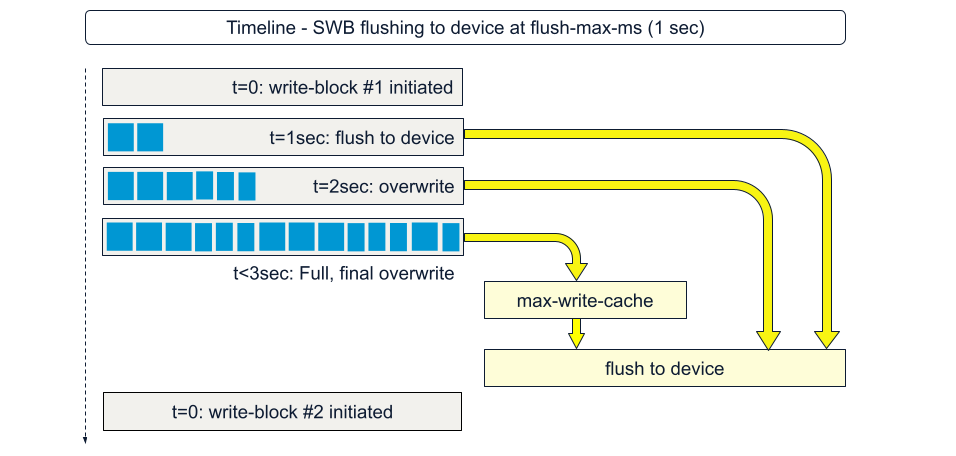
This seems rather inefficient for users who have slow or occasional writes and a read-heavy workload. Why not flush just a partial block size and flush progressively, regardless of record boundaries? This implementation required us to add an end-of-record marker to the current record data structure.
Aerospike record on device was structured originally as:
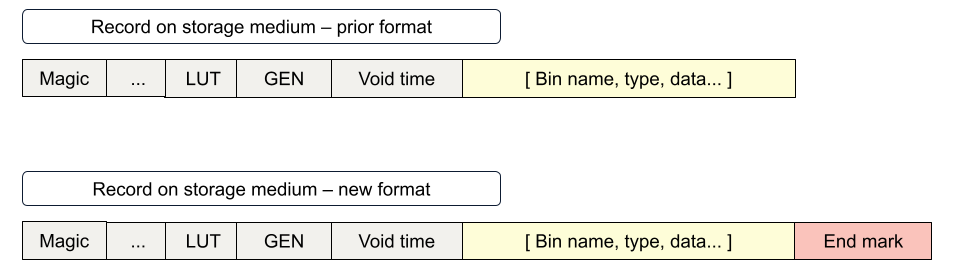
In version 6.0, we introduced a 4-byte end-of-record marker.
Although a simple change, it had implications for legacy users, especially in corner cases where the records were less than four bytes shy of the write-block size. (Aerospike does not allow a record to be split across multiple write blocks.) With all other compelling features introduced in server version 6.0, our customers made the transition.
Armed with the End Mark, it was now possible to flush the SWB partially. A record could be split across two flushes, and with a clear "End Mark", its integrity would be preserved.
Introducing partial flushing
Armed with the record end marker, version 7.1 introduces partial flushing, which will make our slow writes customers very happy without sacrificing performance for any other type of create or update workloads. It will also greatly benefit those using network-attached storage such as EBS by reducing network IOPs used for moving unused bytes in a partially filled block during multiple flush-max-ms flushes, as shown in the figure above. Application architects and developers striving for performance will appreciate the new configuration parameters that can be tuned based on their application workload.
Noteworthy configuration changes
write-block-size configuration parameter is deprecated. This is now internally set to a fixed 8MB (max) size. Version 7.1 will fail to start if you still have write-block-size configured.
Users can still limit their maximum record size using max-record-size parameter which defaults to 1 MB, the original write-block-size default, and effective default maximum record size prior to 7.1. Of course, users wanting to store larger records can set max-record-size to as high as the 8MB limit.
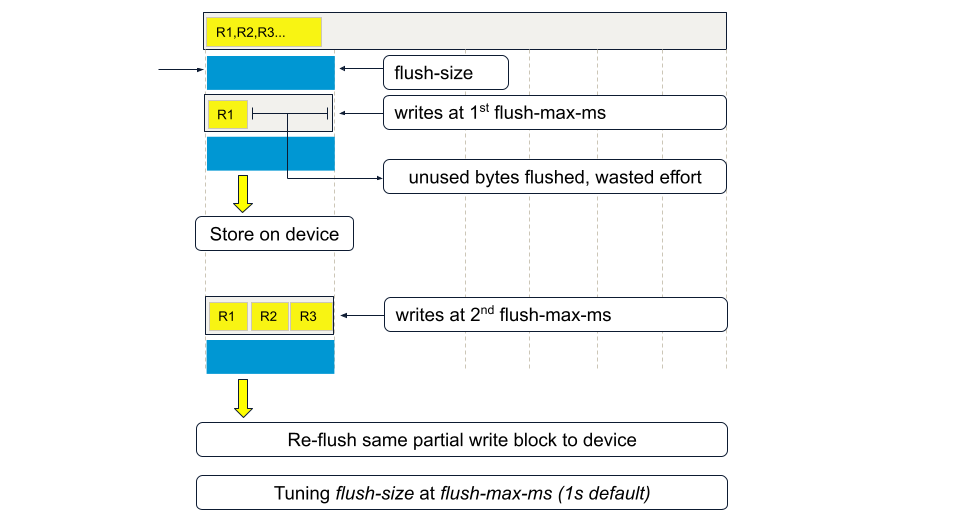
A new dynamic configuration parameter, flush-size, default 1MB, is introduced. The 8MB write-block will now be flushed on writes in 1MB chunks. Likewise, during defrag, which does large block reads, and earlier would read the entire write block size worth of data, will now read a write block for defragging purposes in flush-size (1MB default) increments.
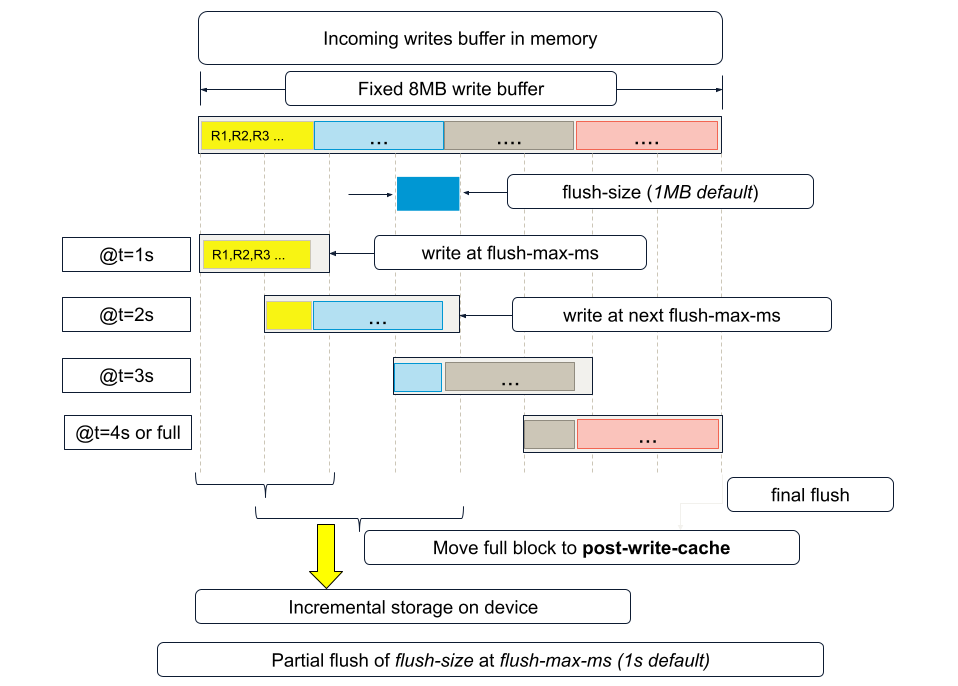
The segments below the partial flush-size blocks indicate which partial flush-size blocks were flushed to disk in this cycle.
When does partial flushing happen?
When data has been sitting around in the partial write block for flush-max-ms time interval, and there have been new writes to the flush-size block since the last partial flush. For example, in the above figure, if after writing R1, R2, and R3 at t=0, they get flushed at t=1, and no further writes happen, these blocks will not be re-flushed at t=2. It would be redundant to do so.
With partial flushing enabled, flush-max-ms of 1000 ms may be tuned lower without paying the earlier penalty of excessive full write block size (8MB now) flushing. While this figure looks very similar to the commit-to-device workflow discussed earlier, there are two notable differences.
First, commit-to-device is flushed for every new record written by the application, whereas in the above partial flush scheme, the flush-size may have multiple records. This also means that while for commit-to-device in SC mode, a commit-min-size of 4KB is typical for SSDs and made non-configurable in version 7.0, for partial flushing, a flush-size of 1MB is default and can be further tuned per the next section. Partial flushing is only triggered after a wait of flush-max-ms and as many flush-size blocks as needed are written to the device.
Second, which has a significant latency impact, in commit-to-device mode, the client does not get acknowledgement of a successful write until the flush-to-device is done. Here, in partial flushing, the client is still writing to the in-memory write buffer, and the successful write is acknowledged to the client upon receiving write-to-buffer acknowledgement from the replica node(s).
Partial flush statistics and tuning flush-size
There are new per-device stats to tune the configuration parameters for optimal performance.
partial_writes (number of partially full flush-size block flushes) and defrag_partial_writes are now available in addition to writes (number of final flush-size block flushes) and defrag_writes, which are stats for final writes of these flush-size blocks.
For example, if flush-size is set to 128KB and 25KB size records are being written at one record every sec, with flush-max-ms at 1000 or 1 second, there will be 25 x 5 ( = 125KB) … 5 partial_writes and one final writes stat count increment as this 128KB flush-size block fills up.
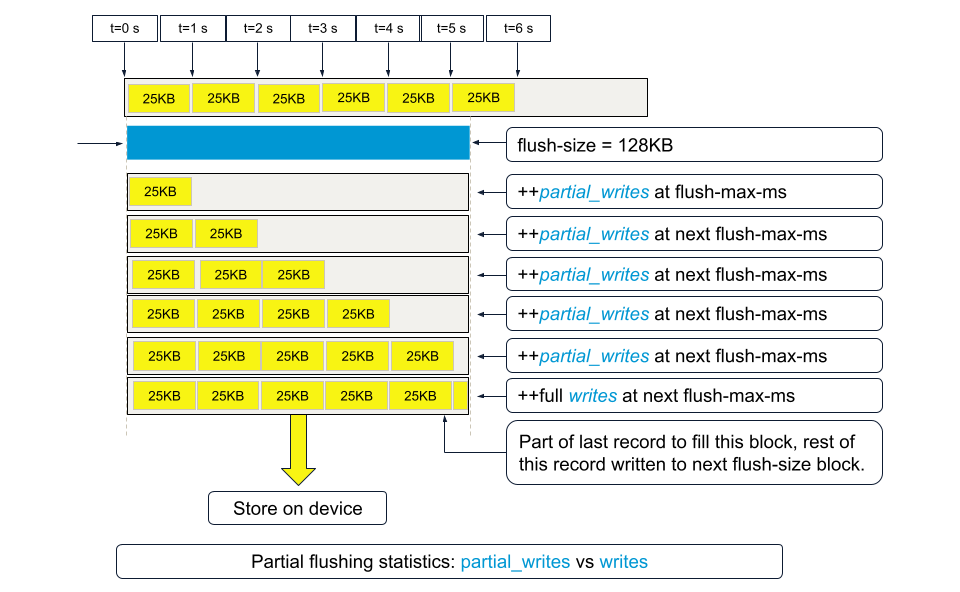
As the figure shows, we repeatedly flush the same flush-size block as it gradually fills up. We flush unused bytes, decreasing every cycle as the block fills up.
When partial_writes >> writes, consider using a smaller flush-size to prevent flushing the same block again and again.
On the other hand, if the record size is 600 KB and a record is written at t=0, there will be four full writes (128KB x 4 = 512KB) on record write, then one partial_write flush of the last 128KB block at the end of flush-max-ms.
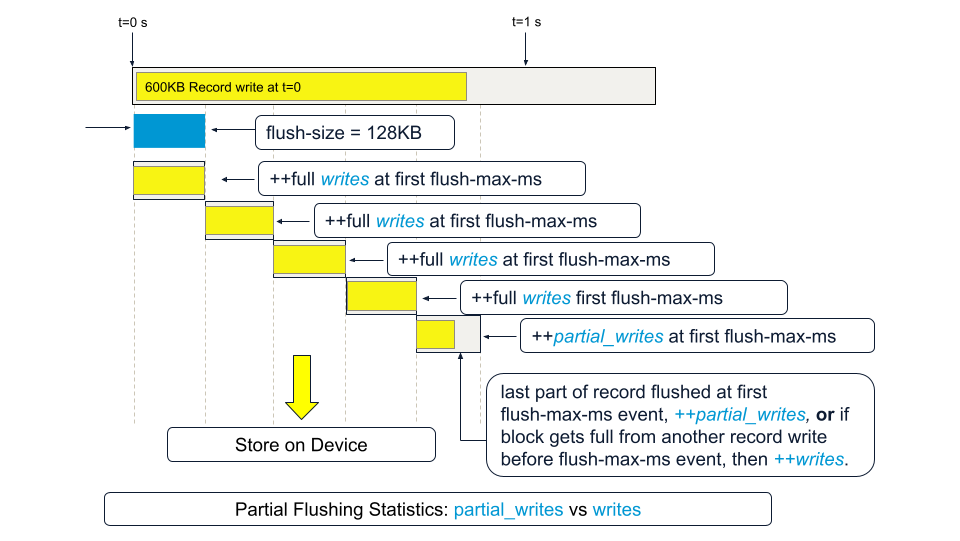
Here, we observe writes >> partial_writes. We can increase the flush-size in this case.
A flush size smaller than ideal does not result in overlapping flushes, though SSDs may not provide optimal I/O performance at small flush sizes. In this case, you may choose the flush size that is better for the specific SSD. This data may be available from ACT (Aerospike Certification Tool) testing of the SSD. 128KB has historically been the sweet spot for SSDs, but newer SSDs may be just as performant at higher multiples of 128KB.
When writes >> partial_writes, consider using a larger flush size as long as ACT testing does not show poorer IO performance for the specific SSD.
Device flushing vs. client write contention
In the partial flushing implementation in version 7.1, we removed the lock contention for the full write block between incoming writes and the flush-to-device operation. Prior to 7.1, if a flush operation was triggered by flush-max-ms event, incoming client writes to the buffer block had to wait for the buffer lock to continue to write to the same buffer. While this was usually not an issue, in server 7.1, it should further improve performance for certain device storage options that can exhibit an occasional "hang" or slow down during the flush operation, causing incoming client writes to wait for the buffer lock.
post-write-queue: Deprecated
In server version 7.1, the post-write-queue configuration parameter has found its end of life. In server versions prior to 7.1, post-write-queue specified the number (256 default) of write-blocks (1 MB default) in the post-write cache, primarily benefiting Cross Datacenter Replication (XDR) which reads the most recently written records for shipping to remote destination(s).
It is now replaced with post-write-cache, which is sized in storage bytes with a default value of 256MB. (This keeps effective memory consumption the same for folks using defaults.)
Other configuration changes
Besides the configuration parameters related to the LRU Cache feature in version 7.1, which are discussed in a separate blog, there are two other configuration changes in version 7.1 - indexes-memory-budget and evict-indexes-memory-pct. These are related to primary index memory management per namespace and are unrelated to the partial flushing feature.
The takeaway
Aerospike Database 7.1 will greatly enhance performance for users with high read / slow or low write workloads while still performing much better for other workloads for default configurations compared to version 7.0. Do pay close attention to the deprecated configuration parameters (write-block-size and post-write-queue) and reconfigure the Aerospike cluster to the new configuration parameters (flush-size and post-write-cache). Tune the flush-size to the expected write load to achieve optimal performance.