

Aerospike Database 5.6 introduces the set-index feature, which permits specific sets in a namespace to be directly indexed. Prior to 5.6, finding specific records in a set required scanning the namespace (expensive if the set is small relative to the namespace), or creating a secondary index, possibly requiring a new bin.
The question is when are set indexes a clear win? Intuitively, small sets clearly benefit from indexing. However, as the set size approaches that of the enclosing namespace, the cost of reading the records dominates, and largely negates the advantages of indexing. This blog describes a series of tests designed to provide a quantitative answer to this question.
Test Configuration
These tests were performed on-prem in Aerospike’s lab. The test bed comprised a 1-node Aerospike cluster and a client running on a separate machine over a 10GBit network. The server had the following characteristics:
Model: Supermicro Ultra SuperServer 1029U-TN10RT
CPU: 2 x Intel Xeon Gold 5220R Processor 24-Core 2.2GHz (96 vCPU total)
DRAM: 384 GiB DDR4 2933MHz
SSD: 5 x 3.2TB Micron 9300 MAX Series U.2 PCIe 3.0 x4 NVMe
Network: 10GBit Ethernet (RJ-45)
The test namespace comprised 2 billion records of 100 bytes. Within that namespace, six test sets were created:
Set A: 2 billion records (100% of the namespace)
Set B: 100 million records (5% of the namespace)
Set C: 1 million records (0.05% of the namespace)
Set D: 10,000 records (0.0005% of the namespace)
Set E: 1,000 records (0.00005% of the namespace)
Set F: 100 records (0.000005% of the namespace)
Test Matrix
For each test set, a scan was performed with and without set-index enabled, and the elapsed time measured. In addition, this basic test was run by varying some related parameters to assess the impact of indexing sets:
Storage in SSD: fetching records is ~1000x slower than the in-memory case.
Storage in DRAM: fetching records is very fast for in-memory namespaces.
4 scan threads: this is controlled by the single-scan-threads configuration parameter, and 4 is the default value.
128 scan threads: this is the maximum allowed value for single-scan-threads.
Results
The results for tests where data is stored on SSDs is shown in Table 1. This is the most important use case, because the cost of retrieving records from SSDs is several orders of magnitude higher compared to retrieving records from DRAM.
These results validate the hypothesis that smaller sets benefit greatly from indexing because the cost of maintaining the index is insignificant compared to the cost of retrieving a large number of irrelevant (because they are not in the set of interest) records.
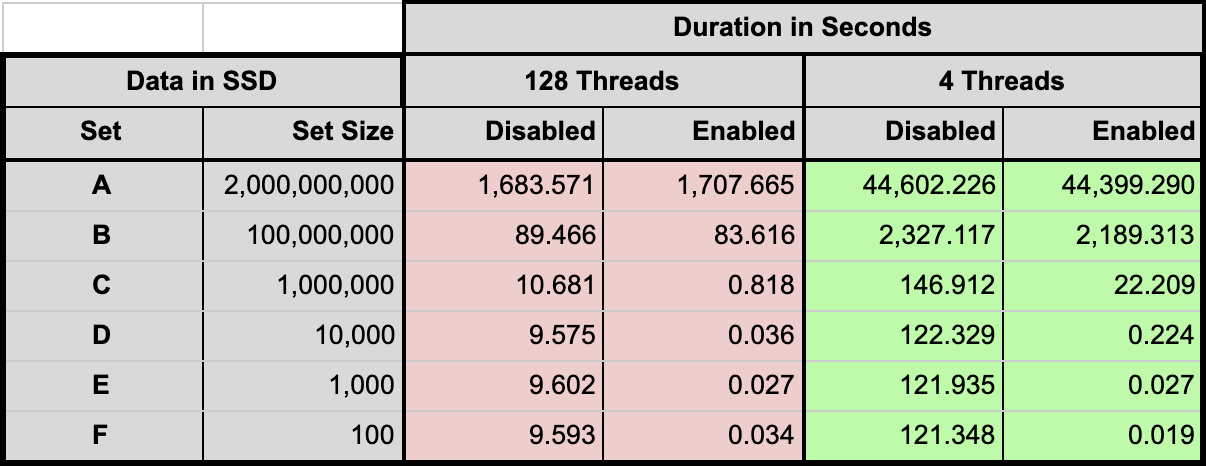
Table 1: Data in SSD
As the set size approaches that of the namespace the advantage diminishes because a larger percentage of the records retrieved are relevant to the scan. However, the cost of maintaining the index is not very high compared to SSD I/O, so even at the limit the additional DRAM and CPU consumed by the index causes only a small degradation in performance.
This can be seen more clearly when the data are graphed, as shown in Figure 1. These data are plotted on a log-log scale to make the pattern more obvious. Here the results with set indexes enabled are shown with solid lines and circles as data markers; disabled results are depicted with dashed lines and diamonds as data markers.
Regardless of the number of threads used to perform the scan, as set size increases, performance with an index asymptotically approaches that of the un-indexed case. With this particular set of test cases, that convergence occurs when the set reaches 100 million records (approximately 5% of the namespace).
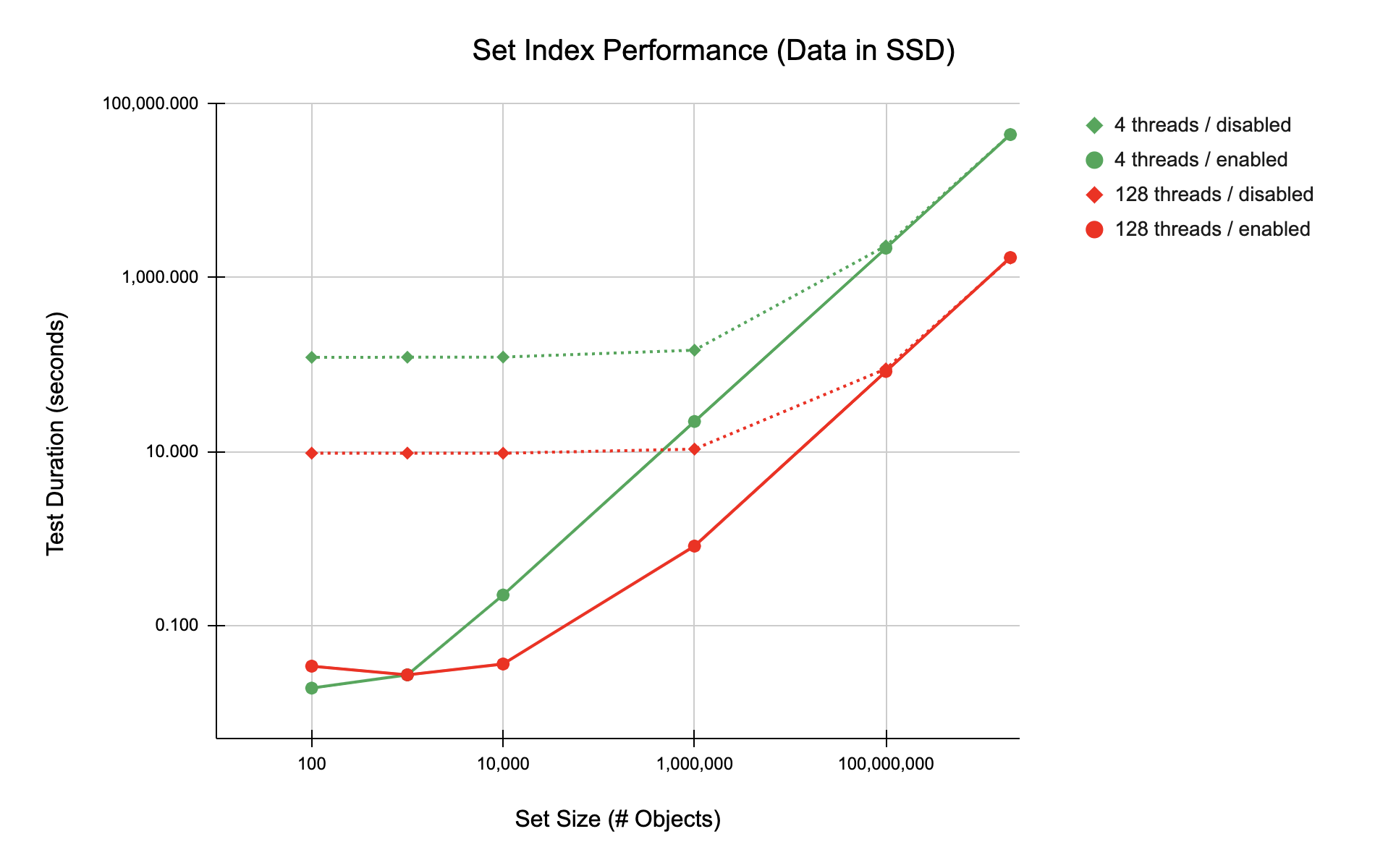
Figure 1: Data in SSD
Effect of Using In-Memory Storage
The same suite of tests were run with an in-memory namespace, and the results are shown in Table 2. Although the overall durations are much shorter because of the faster record retrieval, the same overall pattern still holds: the smaller the set, the greater the benefit from indexing.
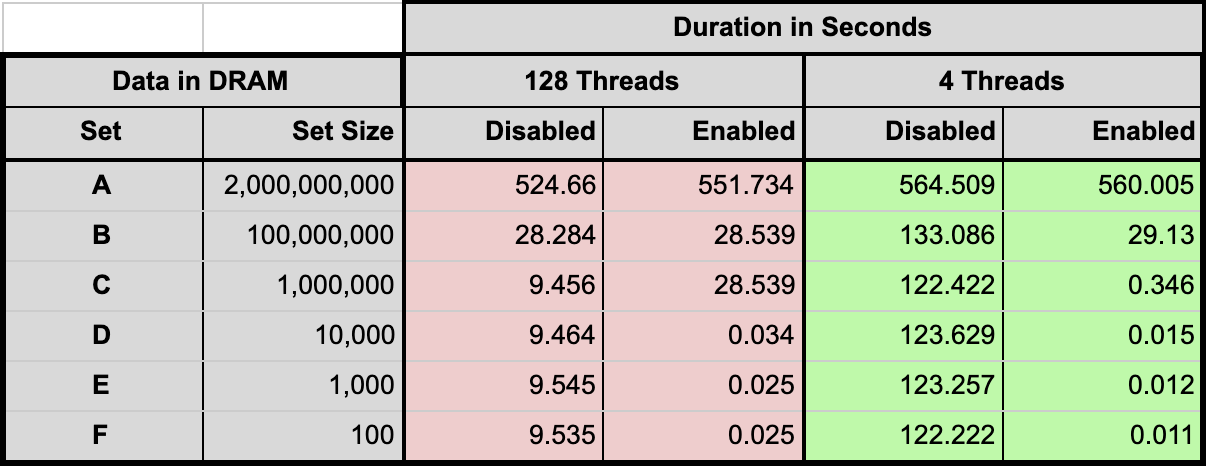
Table 2: Data in DRAM
Effect of Increasing Scan Threads
By default, scans use 4 threads, and as a general rule this is sufficient for most applications. Using 128 threads reveals some additional subtleties. Referring back to Figure 1, the asymptotic convergence is very pronounced and uniform. Most likely this is because SSD I/O predominates regardless of the number of threads.
The results for in-memory namespaces (Figure 2 below) are not so tidy. Using 4 threads, indexes outperform until the set size is nearly the entire namespace. With 128 threads, at 1 million records, indexing the set actually gives worse performance.
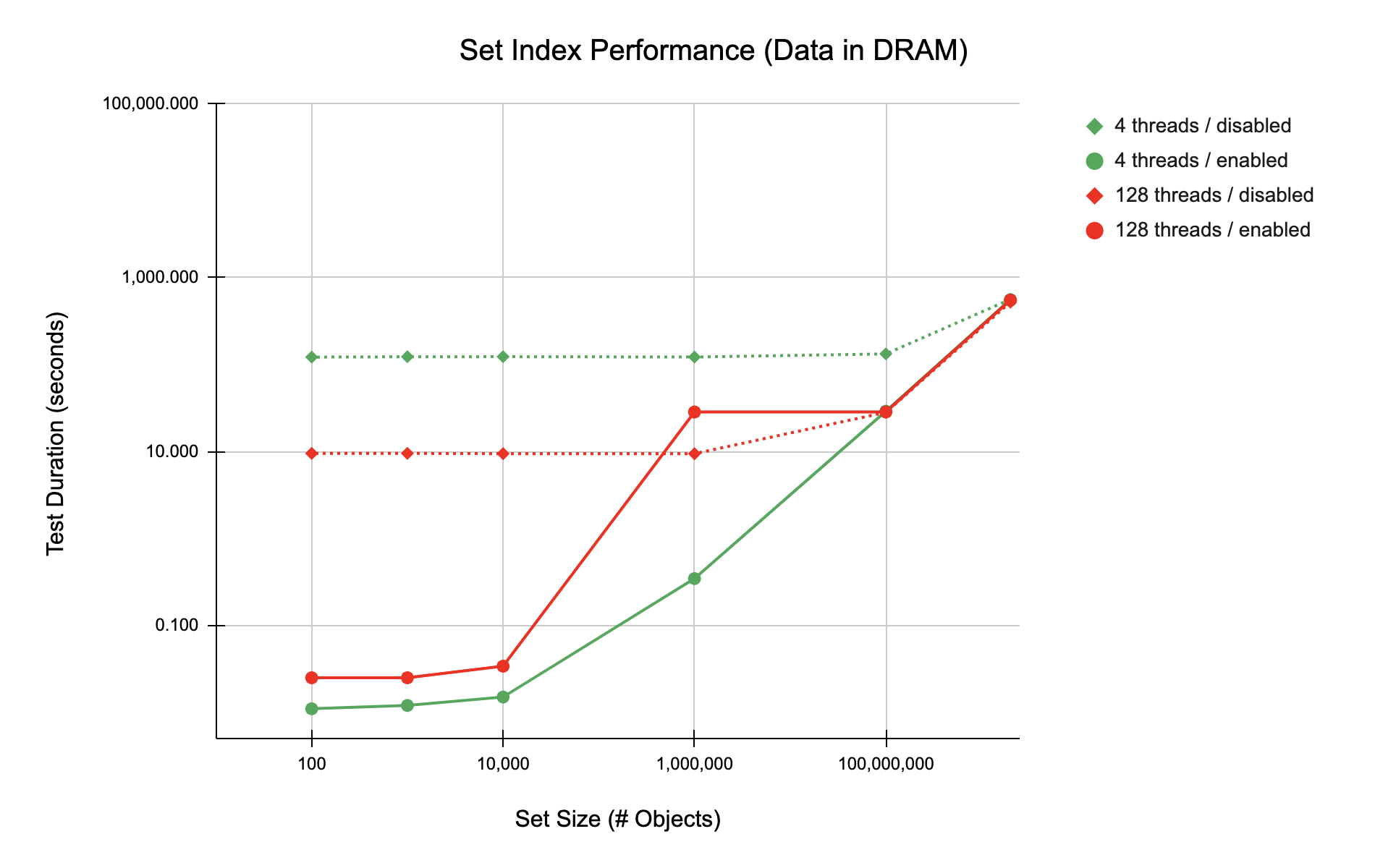
Figure 2: Data in DRAM
Although further tests would be needed to definitively understand the differences, a couple of observations are in order. The primary one is that 128 threads is overkill for the in-memory case; indexing with 4 threads monotonically outperforms 128 threads until set size reaches 100 million records.
Secondarily, without the “ballast” provided by expensive SSD I/O, caching and context switching (too many threads chasing too little work) may introduce non-linearity that is relatively more visible.
Conclusion
The answer to our original question is absolutely yes! With Aerospike 5.6 set indexes are a clear win. The new set index feature provides a range of set sizes that greatly improve scan times with a small cost in memory. The above data and tests outline a starting point for you to start exploring set indexes in your own use cases.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works