Blog
What are the limits of Redis scalability?
Learn where Redis hits scaling walls, from soaring RAM costs and single-thread limits to fragile clustering and persistence trade-offs, and when to switch to elastic databases.
Blog
Learn where Redis hits scaling walls, from soaring RAM costs and single-thread limits to fragile clustering and persistence trade-offs, and when to switch to elastic databases.
Redis started as an in-memory caching and message brokering solution for a single project and has grown into an entire ecosystem of flavors, clones, modules, and modalities. These include (among many other, smaller variants, some of which may or may not play well together):
Redis Community Editions/Open Source
Redis Software/Redis Cloud
AWS Elasticache
GCP Memorystore
Azure Cache for Redis and Azure Managed Redis
Valkey and its variations
So when the question is, "What are the limits of Redis scalability?" what's really being asked is, "Will Redis or a Redis-like system help my application scale, or will it turn into an expensive bottleneck?"
It wouldn't be fair to write an article about where Redis falls short without acknowledging that it's both popular and good at its original use case. As a cache and pub/sub solution for small applications and microservices, Redis excels at being easy to implement and use, while also being highly performant.
Redis is rarely the best technical solution, but the ease of use and large, mature community make it a fantastic tool for devs and founders at the start of their journey. Think of it like bicycling: A 10-speed Huffy from a local big-box store is probably the best place to start for someone who hasn't been on a bike in years. By the time they're shopping for spandex and entering triathlons, though, they probably want to upgrade to something made with carbon fiber from a specialty shop to stay competitive.
So, how do developers know they're at the spandex-carbon-fiber-triathlon stage with Redis? By understanding where Redis scaling stops being easy and starts limiting an application's ability to grow. Or better yet, by planning for scale from the beginning and bypassing "easy" solutions in favor of durable, lasting, elastic DBMS options.
Memory-based: Redis was built to be memory-first. At a cost ratio of 50:1 per gigabyte, RAM gets expensive.
Single-threaded event loop: While Redis has implemented multi-threaded I/O post Redis 6.0, core data access is still single-threaded, limiting parallel read/write on a single instance.
Horizontally oriented: Strict limits on server RAM capacity and the lack of multi-threaded data access mean growing data quantities require horizontal scaling. Vertical scaling is not really an option for high data volumes.
Naive proxy-based clustering: Horizontal scaling is clumsy and can require refactoring code and remodeling data because some commands just… break when transferred to a cluster implementation.
Steep persistence penalty: Redis's persistence options, whether Redis on Flash, Append-Only Files, or RDB, all add significant latency while still being less durable than other databases.
Optimization decisions: Core design decisions within Redis (e.g., resources split between network and read-write operations, unoptimized data locality, AOF/RDB failover bypass, manual resharding) make it unlikely that these limits will go away anytime soon.
Having started as an in-memory cache service, Redis is still largely reliant on DRAM for storage and speed. The default way to store data is still in DRAM, and all of the perceived speed advantages Redis has are the result of DRAM being much faster than most other storage media.
This creates a big problem for anyone trying to use Redis beyond a certain volume of data, perhaps due to high user counts. RAM is expensive. On average, a gigabyte of RAM costs about 50x a gigabyte of SSD storage (about $5 vs. $0.10). Scale that out to terabyte-scale and you're looking at cost differences in excess of $50,000.
If a sudden spike in data volume occurs (for example, an application going viral), it won't just result in a slightly degraded user experience; it will result in out-of-memory issues, rapid evictions, and overall experience-breaking issues that cause users to leave and never come back.
To get around this, Redis and many Redis-like systems have implemented bolt-on "on Flash" solutions (e.g., Redis on Flash, RocksDB, Elasticache Data Tiering, etc.). These approaches add cheaper flash storage on the back-end, but at the cost of significantly more latency, canceling out most of the advantages of using Redis in the first place.
Moving data from RAM to SSD and back in these systems is not a seamless process, and every transfer adds I/O and processing time, along with all of the other potential issues a tacked-together, multi-tier cache approach can introduce. And even this approach runs into problems:
Memory is the primary tier, so you still run into hard caps quickly.
Memory is still required for traditional memory tasks, like per-connection I/O buffering, which further eats into capacity.
Since SSDs were added long after Redis became popular, some key Redis data types don't like using SSD layers, leading to a potential need to refactor and remodel, or keep running into intermittent errors.
While the Redis-like approach to multi-tier storage isn't ideal, the theory behind it isn't just solid — it's actually the state of the art for applications that need RAM latency with flash scale. Approaches like Aerospike's Hybrid Memory Architecture (HMA) are designed to incorporate RAM and flash from the ground up, offering direct access to NVMe flash as block storage rather than having to pass through the OS file system.
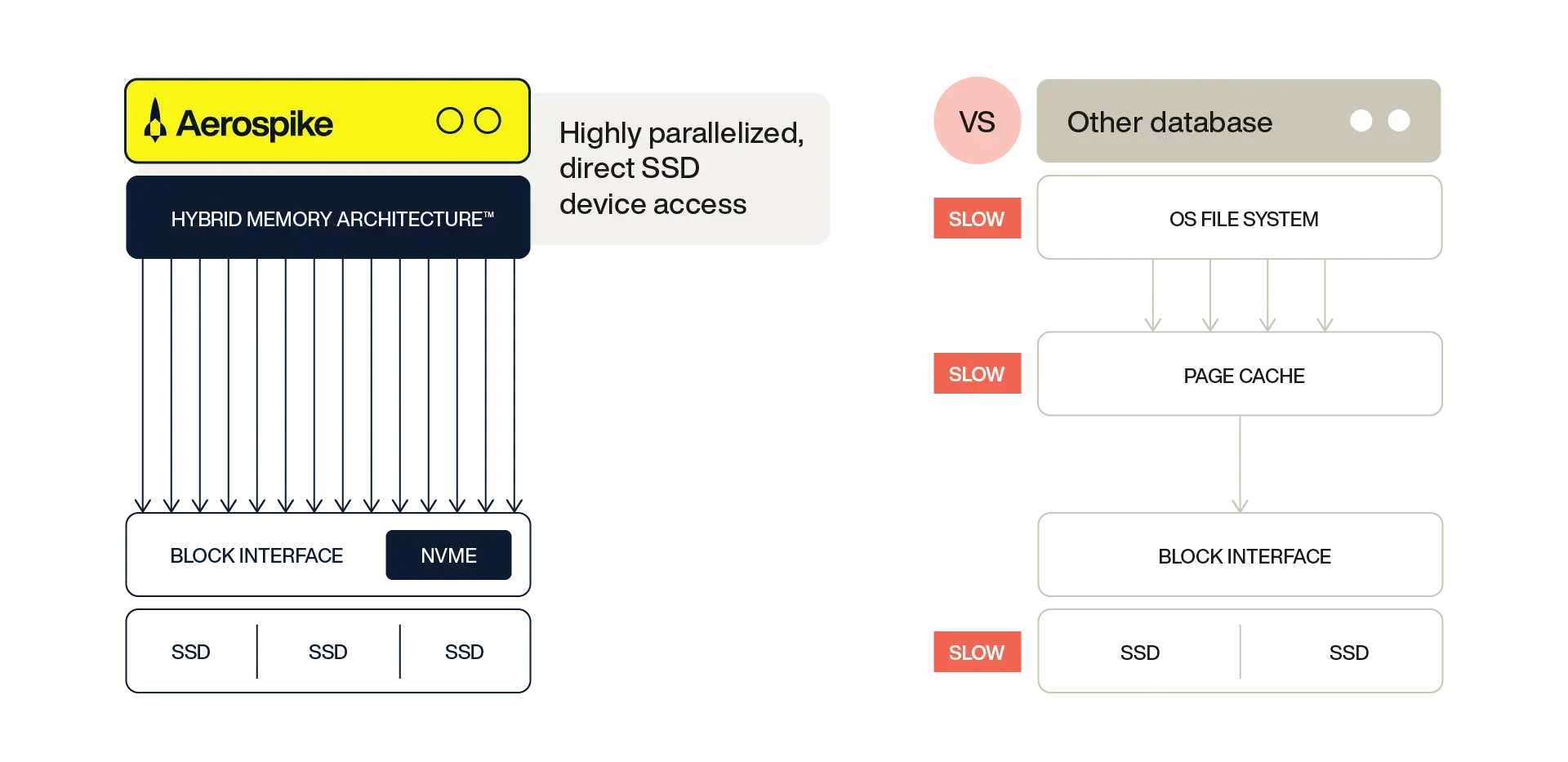
The minimal I/O latency introduced (sub-millisecond if splitting keys and values between memory and flash, and sub-5 milliseconds if using all-flash) is offset by high parallelization in reads and writes. And it's low enough that it's unlikely to even be noticed, given the reality of network latency in moving data from user to server and back in the first place. Parallel writing directly to SSDs not only creates faster reads and writes but also reduces network saturation as clients can perform transactions and close the connection rather than waiting in the queue.
When you run out of memory (best-in-class servers are currently capped at about 10 terabytes) or encounter latency from single-threaded data access, the obvious solution is to scale out and distribute the load. Horizontal scaling is a hallmark of modern DBMSes, but it's also unnecessarily cumbersome with Redis.
For starters, basic functionality that's taken for granted in modern data platforms and that works perfectly fine on single-instance Redis can just break when moved to Redis Cluster. A standard MGET that worked on a single-instance implementation will start throwing CROSSSLOT errors on Redis Cluster if the keys happen to be in different slots. Applications that rely heavily on complex scripting may need to completely rewrite their LUA scripts before migrating to Redis Cluster. They will need to make significant changes to core application data interfaces.
The problem is with how Redis Cluster handles sharding: data is sharded across nodes using hash slots, where every key is mapped to a specific slot, and there is no native ability to coordinate multi-key operations across shards. Imagine the lift to migrate from a single instance to a cluster, only to suddenly lose atomic multi-key transactions and hours of scripting.
There are workarounds available using proxies, but these only mask the problem; they don't fix it. Other solutions, like using hashtags ( {} ), solve some of the underlying key splitting issues but pull architecture into logic, which is bad practice and can cause more problems if the application ever moves off Redis. The bottom line is this: applications that don't start on clustered Redis will always be vulnerable to CROSSSLOT errors and could require a major engineering lift, right in the middle of a heavy scaling period, to even run on Redis Clusters.
Ignoring how weird it is that Redis works differently with a single primary than it does in a cluster, getting Redis Cluster up and running still adds a considerable operational lift and doesn't come close to solving all of the primary scaling problems Redis runs into.
For starters, scaling horizontally doesn't dramatically change the cost problem: RAM is expensive whether it's deployed across one server or a hundred. It makes an impact around the margins — smaller DIMMs are cheaper than larger ones, and hardware capable of running the theoretical maximum is more expensive than hardware that can handle more standard RAM amounts — but it's not "tech company scaling" cheaper. And the savings from using more mundane equipment are often offset by the operational overhead of deploying and managing additional nodes.
Many cloud service providers (including Redis Cloud) can hide the messy bits behind a simplified front-end, but at a cost. Applications using Redis Open Source can require significant manual intervention to deploy and manage new nodes in Redis clusters.
While Redis can experience growing pains when moving from a single-instance to a clustered deployment, most modern NoSQL (and NewSQL) DBMSes are built to be elastic. This is true for clustering elasticity (the ability to add or remove nodes, often automatically, based on demand) and data elasticity (the ability of a data model to adapt to clustering changes).
While starting development with an elastic DBMS may seem like overkill, especially during early stages when much of an application lives locally on a single, small on-prem server, doing so drastically improves the scaling experience later. Nothing is more frustrating than watching user counts rise and being unable to meet demand because the data structure or access needs to be reworked to increase node count. To set up for scaling success, look for DBMSes that include:
Automated provisioning and deployment in response to demand
Native cluster-aware client libraries
Integrated rack-aware capabilities if high availability or data durability is a core requirement
Data models that work the same whether running a single instance or a global cluster
A well-built, modern elastic DBMS can be so robust and performant that a separate cache layer becomes unnecessary. Server sprawl is drastically reduced, while data durability and server efficiency are increased.
When used for the original purpose, as an ephemeral cache or pub/sub broker, Redis's approach to persistence is a non-issue:
Data moves through quickly without needing to be kept long-term
Persistence isn't a core operational requirement
Data loss is a low concern
That all changes when Redis is expanded beyond its original fit. When applications use it as a more permanent storage system or DBMS, it begins to run into some serious scaling issues. The core problem is that Redis wasn't designed with persistence in mind, and the implemented Redis persistence approaches were added on later. This makes them slower, less comprehensive, and more brittle than competitive DBMSes (like Aerospike) that were built bottom-up with persistence in mind.
Redis offers two core persistence strategies: RDB Snapshot and Append-Only File (AOF). The former is a periodic point-in-time dump of in-memory data, while the latter is a running log of every write command. Both come with massive compromises (see the Redis Persistence article linked above for a more detailed look):
RDB: As a point-in-time snapshot, every change between snapshots can be lost in the event of an outage, making this less-than-useful for anything requiring high durability and low data loss.
AOF: User-selectable sync levels provide more granular control over data loss, but even with fsync=always enabled, some loss can occur. Constant logging also brings stiff throughput and latency penalties. Enabling fsync=always can reduce throughput by 10% to 50%.
AOF can also lead to significant memory bloat for high throughput applications, ballooning the amount of storage necessary (a huge problem for 100% in-memory systems). Rewriting the file to shrink it requires blocking background I/O processes.
Typical modern DBMSes rely on replication strategies to balance durability against the performance costs of systems like AOF and RDB. The problem with Redis is that replication and failover approaches don't solve either problem well. In the event of a failover, the RDB and AOF approaches are bypassed entirely for quorum-based failure detection and replica promotion. There is a lack of a strong consensus mechanism, no guarantee that the most up-to-date replica is promoted, and no log replication or commit index.
Altogether, that adds up to a process that may be faster and have less latency impact than relying on RDB or AOF, but it can potentially result in significant amounts of data being lost. Part of the problem is slowly being addressed through the development of the RedisRaft module to ensure strong consistency. However, the module has been under development since 2020 and is still not in a deployment-ready state.
That leaves one option to create strong consistency guarantees: the WAIT command. This command ensures writes are replicated to a minimum number of servers before acknowledging success. However, it's not a good option.
The replication problem runs much deeper than touched on. Redis is a fractured ecosystem that behaves differently depending on which flavor is being used, and every flavor has its own unique replication approaches and challenges.
Distributing data around the globe for high performance, availability, and durability means learning the exact quirks of the specific flavor in use. For example, AWS Elasticache only offers active-passive options. Meanwhile, Redis Software/Cloud and Azure Redis support active-active replication but require massive amounts of space to enable it. Redis Open Source requires manually building a replication system using modules, plug-ins, and third-party solutions. None are ideal, all come with performance trade-offs, and all are far from easy.
Users who look at Redis data guarantees can come away shocked at the tradeoffs involved.
| Guarantee needed | Redis mechanism | Performance cost | Reliability gaps |
|---|---|---|---|
| Durability | AOF with fsync=always | High I/O overhead | Can still lose last op |
| Crash recovery | RDB and replication | Snapshot staleness | Data loss on failover |
| Write consistency | WAIT command | High latency, blocking | No causal ordering |
| Multi-region safety | Available in some managed Redis services | N/A | N/A |
This isn't a flaw in Redis; it's the result of design decisions that prioritized building a low latency, in-memory cache rather than a persistent DBMS. Just like users wouldn't use a hammer to secure rack screws, developers shouldn't expect to be able to use Redis for all their data management needs if persistence is a mission-critical requirement.
This is especially true for systems that need cross-region or cross-data center replication for availability and safety. Redis itself doesn't natively offer an easy way to ensure replication across locations and requires picking the right flavor or messing with modules and plug-ins to work.
Contrast this with Aerospike, which doesn't lose anything on latency or throughput (especially after accounting for network latency) but does feature a best-in-class data replication solution through the XDR feature for getting data distributed, responding to failure events, and handling failover. Latency can actually improve with XDR over Redis by automatically positioning data closer to end-users and reducing transfer times.
Redis is good at the use case it was designed for: simple, low-latency key-value caching with relatively low volumes and no persistence requirements. But as apps grow, Redis runs out of steam quickly, especially when it's forced into roles it doesn't really support. And replacing it once that point is reached can be a challenge to say the least — refactors and migrations are rarely smooth or cheap.
Ideally, developers should build applications from the beginning as if they're going to be the next Facebook — plan for millions of concurrent users around the world who expect consistent data in fractions of a second. That doesn't mean immediately signing up for the latest and greatest enterprise DBMS (though many offer free community editions). It does mean examining options and alternatives, and gaming out where they hit the limit and if that limit will be too low. It also means not prioritizing ease of deployment as the be-all and end-all. Lastly, it means designing applications with the knowledge that a database migration might be necessary, and developing data components as easily swappable modules.
See how Redis stacks up against Aerospike and determine whether Aerospike should be your first and last option instead.
For a deeper understanding and more insights, explore these additional resources.
See more


