Building a user profile store for real-time bidding
Discover how Aerospike transforms real-time bidding with its high-performance user profile store. Dive into the challenges of AdTech and see how Aerospike offers speed and low latency solutions.

The digital advertising world moves at lightning speed. Real-time bidding (RTB), the engine behind many online ad platforms, requires ultra-fast data access to personalize ads in milliseconds. This is where Aerospike shines. Its architecture, built for speed and scalability, makes it a perfect choice for building a user profile store that fuels RTB decisions.
Imagine this: an ad platform needs to determine the best ad to show a user browsing a website. To make an informed decision, the user's interests, browsing history, and other relevant data need to be accessed. This process must be quick. All data retrieval should happen in no more than ten or so milliseconds, and dozens of individual data retrievals may be required within this window. With billions of users and millions of potential ads, this process demands a database that can handle massive volumes of data and respond in a fraction of a second.
Enter Aerospike. Its unique design, with flash-optimized data storage and a distributed architecture, provides the speed and scalability needed for this critical task.
In this blog post, we'll explore Aerospike's power in the AdTech landscape. We'll also explore the challenges of building a user profile store for real-time bidding and showcase how Aerospike tackles these challenges by offering high performance and low latency. There’s also a practical code example walkthrough for building a user profile store using Aerospike.
User profile store for real-time bidding
User profile stores contain current, historical, and derived information about users. In the AdTech vertical, a user profile store typically keeps audience segmentation data pertaining to the users’ interests. Normally, a user is identified by a cookie or device ID containing a unique ID rather than identifying a particular individual. This ID can identify the user’s device (phone, tablet, computer, etc.). AdTech companies will typically store information against this ID regarding websites the device has visited, purchases made on the device, etc. This enables them to build up a picture of the interests of the user of that device.
Note that this is a simplistic view. Advanced AdTech companies typically try to match users across devices, so if the same user uses a phone, a tablet, or a computer, they see an aggregated view of their interests. Also, amalgamated views of interests across households are not uncommon. For example, consider a family in a household who owns a dog. One person in the household might typically shop for dog food, but it’s not unlikely that other people in the household might also respond positively to seeing an ad for dog food.
Recent changes in privacy regulations, such as Europe’s General Data Protection Regulation (GDPR), have reduced the dependency on cookies and device IDs. However, various other methods, such as probabilistic and synthetic IDs, are now used by AdTech companies to show more targeted ads to people. These typically rely on more data, not less, exacerbating the need for user profile stores.
Audience segmentation retrieval for real-time bidding (RTB) is a form of personalization that occurs tens of millions of times per second, as ads are served in real time around the world to people using apps, visiting web pages, and watching streaming content. It’s simple to describe and generally applicable to other forms of online personalization. The AdTech companies enter a bidding process in an auction to display an ad on users’ screens based on what ad campaigns they have been contracted to display and how likely they believe the user is to click on the ad. The more likely they feel the user will click on an ad that they have available, the more they can bid.
This is where the information about the users’ interests comes into play. If an AdTech knows a user is interested in football, for example, and has a merchant who is having a sale on football jerseys, they will probably bid more for the right to show their ad to that user. However, this whole end-to-end auction happens in the literal blink of an eye—about a hundred milliseconds.
During this time period, a whole auction ecosystem occurs. Multiple AdTech companies may be involved in bidding for the right to display an ad on the user’s screen in a process that is too complex to explain here. However, that effectively means that reading the user’s interests can take no more than about ten milliseconds, and the more information that can be loaded in that time, the better determination that can be made about what ad to show to the user.
It is also important that a user's segments can expire. If someone has not viewed information on car batteries for more than a month, for example, it’s probably no longer relevant to them. Hence, many AdTech companies will expire audience segments after a period of time, typically thirty or sixty days.
Data model
In this case, there is an obvious primary key, the user ID or cookie ID, typically a string. All the user segments could be stored inside a list or map in a record associated with that key. However, the segments need to have an expiry time to live (TTL), which Aerospike supports only at the record level. This is not granular enough to be able to expire records inside a map in a record.
For the sake of this example, assume that the AdTech is using user IDs instead of cookie IDs. One possible data model would be to store the primary key as a compound key, with the user ID as the first part and a sequence number as the second part. So if the user ID is “1234” and there are three audience segments, the primary keys would be “1234:1”, “1234:2”, “1234:3,” and so on. A representation of this might look like:
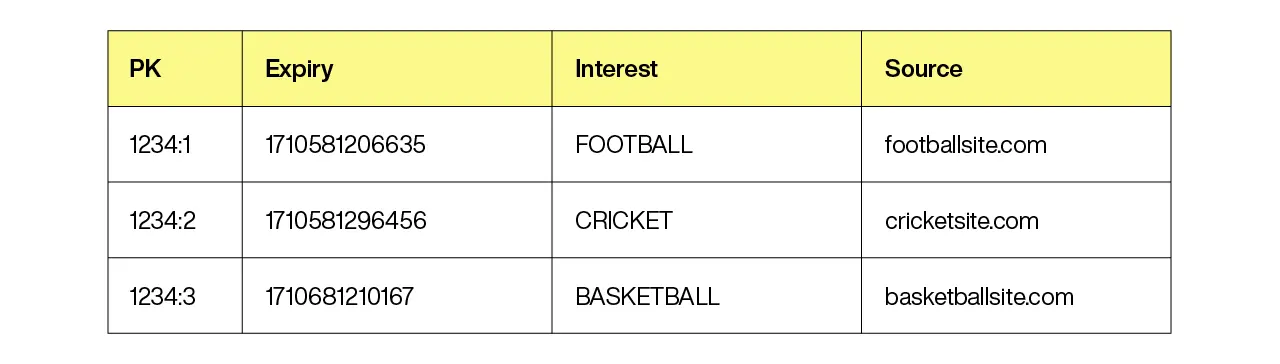
Note that the expiry is in milliseconds since the Unix epoch of 1/1/1970. Typically, other information is associated with each segment, like where this segment was seen (the “Source” in this example).
Also, this table shows the interests (segments) as strings for comprehension purposes, but they are almost certainly long integers. The sample code associated with this blog has the segments modeled as longs.
This model has the advantage of being simple and able to automatically expire the segments through Aerospike’s TTL mechanism. It’s also flexible, as it’s easy to add new bins to the model and extend it as business requirements change.
However, there are a number of drawbacks, too. These include:
It’s not obvious how to work out how many segments there are. One user might have five segments, and another user might have one hundred. If you know how many segments there are for a user, a batch read can be used to pull in all the segments for that user. However, working out the number of segments would typically require an extra read, costing time.
For example, consider the segments in Table 1. There are initially three, but what if the “cricket” segment hasn’t been seen for a while and has expired, and two new segments have been added? So the “active” segment IDs would be “1234:1,” “1234:3,” “1234:4,” and “1234:5.” Over time, it becomes increasingly hard to know which keys relate to active segments, and trying to read segments that have expired takes time which is undesirable.
A secondary index could be used for this purpose, too, requiring the user ID to be in a separate bin. Then, a secondary index query could be issued withFilter.equal("userId", value). However, secondary index queries are not as fast as primary index queries, and performance is critical in this use case.The records are typically small. Remember that each record in Aerospike requires 64 bytes of primary index storage. One large AdTech that uses Aerospike for this use case has around fifty billion records. (Obviously, they’re using cookie IDs rather than user IDs!) If there are, on average, a thousand segments per cookie, that’s fifty trillion records. Multiply this by 64 bytes, and they would require almost three petabytes of storage for their primary index, which is typically stored in DRAM for performance reasons. That’s a lot of DRAM and a lot of records Aerospike needs to scan to determine if they have expired or not!
Hence, a better data model would be to use a single record per user with a primary key of the user ID. The interests could be stored in a map with the segment ID as the map key, a list continuing the record expiry, and other information as the map value. This is shown in Table 10.2.

Expiry of elements
This design has a number of advantages over the first proposed design. These include:
It uses only a single key-value read to get all the segments for a single user, resulting in optimal performance.
The number of records equals the number of users, so in the example above, there would be fifty billion records, requiring about three terabytes of primary index storage across the cluster. While this sounds like a lot, it is important to note that this is a very large use case. Assume each segment and associated data is fifty bytes, and each user has, on average, a thousand segments. (This is a little higher than might be seen in production, but this is for the sake of illustration). That means the amount of data to be stored in the database is:
50 bytes x 1000 segments x 50 billion records ~= 2.3PBThat’s a lot of data! It would definitely need a large cluster size, and three terabytes spread across a cluster that large is not a large amount of DRAM per node. Note that multiple petabytes of data like this is not an issue for Aerospike, and “large” clusters like this one might be between one hundred and two hundred nodes, with high data density per node.
The only drawback to this approach is that Aerospike’s inbuilt record expiration mechanism cannot be used to expire segments as they’re map elements instead of records. However, Aerospike supports powerful list and map operations, which can be used to implement expiry at the map segment level. This technique relies on having the expiration timestamp as the first element in the list of values, similar to what is shown in Table 2. Retrieval of all non-expired elements relies on calling MapOperation.getByValueRange. For example :
long now = new Date().getTime();
Record record = client.operate(
writePolicy,
deviceId,
MapOperation.getByValueRange(SEGMENT_NAME,
Value.get(Arrays.asList(now)),
Value.INFINITY,
MapReturnType.KEY_VALUE));
// This is returned as an ordered list of SimpleEntry
List<SimpleEntry<Long, Object>> segments = (List<SimpleEntry<Long, Object>>) record.getList(SEGMENT_NAME);The parameters to the getByValueRange call are the bin name (segments), the start time (now), the end time (INFINITY), and the information to be returned, in this case, just the key and the value. If a segment is valid, the expiry time will be in the future, and these parameters will select these entries.
So why is the start time (now) wrapped in a list? The segments map in Aerospike stores a key (the segment name or number) and a value, which, in this case, is a list of items with the timestamp as the first item. For a meaningful comparison, Aerospike must compare items of the same type, so a list must be compared to a list. If the start time were not wrapped in a list, the getByValueRange call would compare a list and an integer so that no items would be returned.
There are a couple of options for removing expired segments. The first is to remove obsolete segments when a new segment is added. As this incurs a write anyway, the cost is fairly low. The code to that looks like this:
List<Object> data = new ArrayList<>();
data.add(segment.getExpiry() == null ? 0 : segment.getExpiry().getTime());
data.add(segment.getFlags());
data.add(segment.getPartnerId());
long now = new Date().getTime();
client.operate(writePolicy, deviceId,
MapOperation.removeByValueRange(
SEGMENT_NAME,
Value.get(Arrays.asList(0)),
Value.get(Arrays.asList(now)),
MapReturnType.NONE),
MapOperation.put(
MapPolicy.Default,
SEGMENT_NAME,
Value.get(segment.getSegmentId()),
Value.get(data)));Note the call to removeByValueRange as one of the operations in the list to remove the expired segments.
Prior to Aerospike 7, there was a CPU cost to the removeByValueRange operation if the records were stored on SSD. The reason was that maps stored on SSDs, even those created with a map order of KEY_VALUE_ORDERED, only persisted the data sorted by the key. The index used to access the values in value order was not persisted, meaning that the map had to be sorted each time Aerospike needed to access it in value order.
Version 7 introduced the ability to persist these indexes. This requires extra space on the SSDs to store the indexes but removes the need for CPU cycles to perform this sort. The way to persist a map index is to use MapOperation.create(String binName, MapOrder order, boolean persistIndex). Note that persisting the map index in this case will also lower the CPU cost of the getByValueRange call in the retrieval path.
Another approach to removing these expired elements is to use a background query with an operation. This is very efficient as the operation runs in the background on each server without the need for the client to wait until it finishes. A maximum throughput rate can also be specified to ensure server side resources are not heavily taxed by the operation. The code for this could look like:
Statement stmt = new Statement();
stmt.setNamespace(NAMESPACE_NAME);
stmt.setSetName(SET_NAME);
stmt.setRecordsPerSecond(1000);
ExecuteTask task = client.execute(null, stmt,
MapOperation.removeByValueRange(
SEGMENTS, Value.NULL,
Value.get(Arrays.asList(now)), MapReturnType.NONE));
task.waitTillComplete();Note that the waitTillComplete call will force this thread to suspend until the background scan returns, and it may not be needed depending on the use case. In this example, the rate of execution has been throttled using the setRecordsPerSecond method, which limits execution to a thousand records per second per server, not across the cluster.
Build a user profile store with Aerospike
Real-time bidding in the AdTech vertical relies on the ability to fetch data very quickly over large volumes of data. Aerospike excels at this and typically provides almost constant low latency, resulting in predictable ad-serving times. Data modeling the RTB use case properly to take advantage of the powerful operations inside Aerospike offers a single record lookup for all the segments associated with a single user and optimizes the use of hardware, hence the total cost of ownership.
Explore the sample code, which presents a fully working implementation of the RTB process. Two different implementations are provided. One uses native API calls, as shown in this blog, whereas the other uses the Java Object Mapper, a concise way of mapping Java POJOs to Aerospike and back using annotation-based configuration.