At Aerospike, we constantly utilize customer feedback to drive product improvements and the roadmap. Here are a few concerns that we hear from our customers that we have worked to solve.
Data Scientists are challenged with training and retraining AI and ML models in the shortest period of time to capture the latest patterns in the rapidly changing data. Further, they need to access 100’s of terabytes of data from a system of record without making additional copies of it for governance and costs reasons.
Data Infrastructure engineers are struggling to support high throughput/low latency pipelines both on-prem and in the cloud while driving lower TCO.
Developers are challenged to build applications that go beyond POC due to inability to build applications at scale.
Business leaders are worried about the ROI on their legacy investments.
Aerospike Connect was conceived to create an ecosystem around the Aerospike enterprise database to enable you to pursue several use cases such as a) augment mission-critical legacy enterprise systems (e.g., mainframes) by connecting them to an Aerospike system of record that can combines data from several edge systems with the data from enterprise systems and b) Integrate the real-time data stored in the Aerospike system-of-record with ML/AI processing systems such as Spark to enable faster generation of AI/ML models on the combined data stored in the Aerospike System of Record, and so on. With that in mind, we are excited to announce the general availability of our updated connectors and beta release of a brand new connector to help you tackle the aforementioned challenges. The Aerospike Connect Product Line is listed below:
Aerospike Connect for Spark
Aerospike Connect for Kafka
Aerospike Connect for JMS
Aerospike Connect for Pulsar
(Beta)
Aerospike Connect for JMS
As you know, Mainframes are here to stay due to high performance, reliability, compliance and security, and steep migration costs. Hence, our customers are always looking for a way to seamlessly bridge mainframe based systems to modern services that are based on newer technologies such as Spark, Kafka, AI/ML frameworks, etc. These services empower financial services, telecom and other industries to enable the creation of bleeding edge applications related to mobile payments, IoT, 5G, and others.., to create tremendous business value. As shown in Figure 1, Aerospike Connect for JMS and Kafka in conjunction with IBM MQ have helped our customers bridge these disparate systems by creating a system of augmentation for data from various legacy systems. This is achieved while leveraging sub-millisecond read latency, strong consistency, multi-site clustering, among other capabilities of Aerospike 5.0.
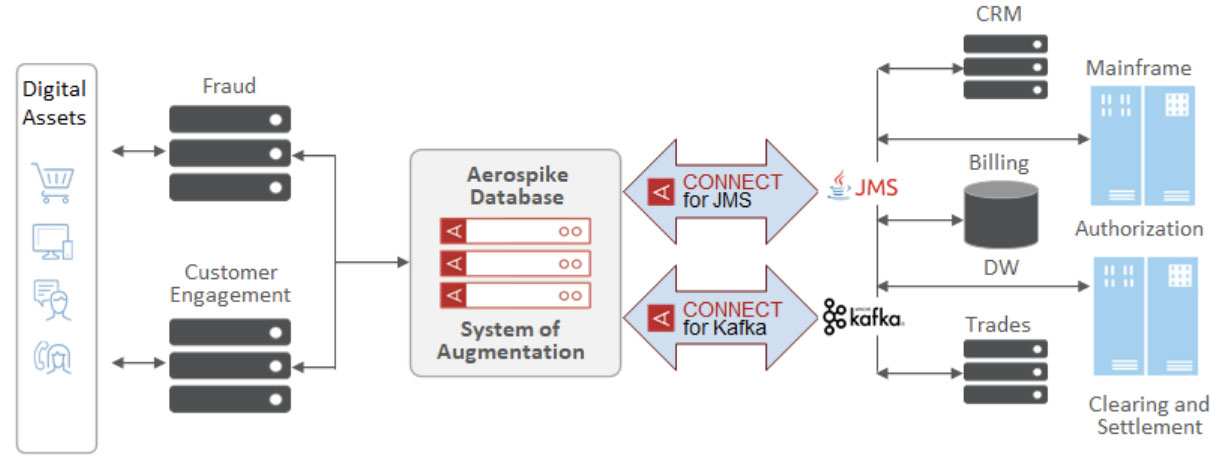
Figure 1
Aerospike Connect for Spark
Aerospike Connect for Spark, allows Spark developers to load data into Spark DataFrames from the Aerospike database for analysis with Spark SQL, Spark ML and other Spark libraries. Furthermore, data sourced from Spark can be persisted in an Aerospike database for subsequent use by non-Spark applications, expanding the scope of its usage. Aerospike’s efficient use of DRAM, SSD, and PMEM affords Spark users a high performance and cost efficient backing store for large volumes of real-time data.
Connect for Spark features several new performance optimizations. For example, the connector allows users to parallelize work on a massive scale by leveraging up to 32,768 Spark partitions to read data from an Aerospike namespace storing up to 32 billion records across 4096 partitions. Aerospike will scan its partitions independently and in parallel; such support, when combined with Spark workers, enables Spark users to rapidly process large volumes of Aerospike data.
In addition, Spark programmers can use query predicates to limit Aerospike processing to specific partitions. This avoids costly full data scans, speeds data access, and avoids unnecessary data movement between Aerospike and Spark. Filtering large data sets on the Aerospike server also minimizes memory needs on the Spark side, avoiding potential runtime errors or high operational costs. Aersopike administrators can control the number of parallel scans via a configuration setting, tailoring the number of scan threads to the needs of Spark applications. In addition, Connect for Spark uses worker thread pooling to minimize overhead when writing Spark data to Aerospike. Further optimizations include batch reads for queries with primary keys and partition filtering for secondary keys.
With the system architecture shown in Figure 2, an Aerospike customer was harnessing data from millions of users across their digital assets to create a 360 degree customer profile to improve their targeting capability. The customer was able to maximize the ROI on their previously sub-optimally utilized Spark cluster. Consequently, it also enabled them to significantly reduce the training time for their ML models, which allowed them to increase the frequency of retraining to improve model accuracy. Using the various optimizations described earlier, the customer was able to reduce the execution time of a spark job by 80% from 12 to 2.5 hours. Furthermore, by using Aerospike database as the system of record and selectively loading data into Spark, they were able to eliminate the need to copy 100’s of terabytes to other analytics systems as done previously. This helped them significantly with compliance and cost reduction.
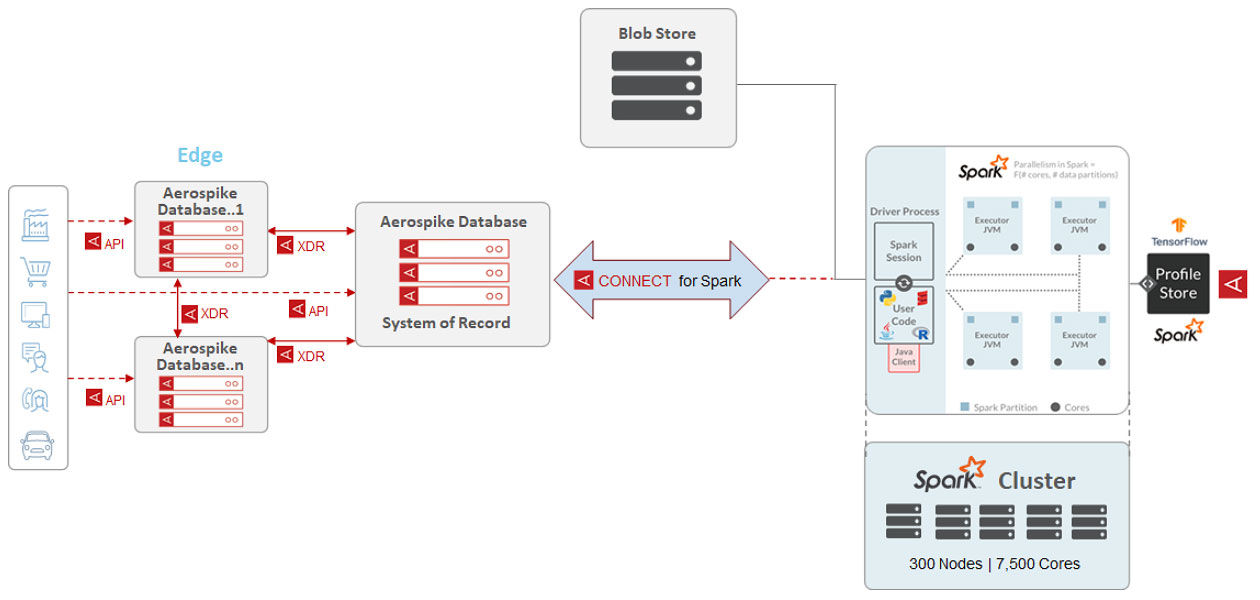
Figure 2
The configuration used to achieve the above (Figure 2):
33 node Aerospike (version 4.9) cluster
300 node Apache Spark 2.4 cluster with 7,500 cores
160 TB of unique (unreplicated) data
4,096 Aerospike partitions mapped to 8K ( 2
15
= 32,768 max supported ) Spark partitions per namespace (Max 32 namespaces are supported per cluster with max 32 billion records per namespace is allowed)
We offer several tutorials for developers via Jupyter notebook, as shown in Figure 3, so that they can rapidly build spark applications using their language of choice and quickly progress from POC to production.
Figure 3
With our newly added Spark Structured Streaming support, you can use the Aerospike DB as an edge database for high volume and high velocity ingest. One can seamlessly stream change notifications to the downstream spark cluster via Kafka. This serves as a streaming source for Spark, and loads data into a streaming DataFrame for analysis with Spark SQL, Spark ML, and other Spark supported open source libraries.
Aerospike Connect for Kafka
The Aerospike team presented the new Aerospike Connect for Kafka at the Kafka Summit 2020 that had registered 30,000 attendees. The focus of our talk and the demo was to show how Aerospike Database 5 with the new XDR protocol could enable users to build a low latency and high throughput streaming pipeline by leveraging Aerospike Connect for Kafka and Spark. Our hope is that our attendees will use our demo as a baseline to build interesting streaming applications that will create value for their businesses.
Aerospike Connect for Pulsar (Beta)
We are seeing significant traction for Apache Pulsar, which offers several features that are valuable to our customers in industry areas such as IoT, AdTech, etc. Their use cases range from complex log analysis to business analysis, and a slew of other latency sensitive applications. Aerospike Connect for Pulsar helps developers build a low latency pipeline by making the real-time data stored in Aerospike a component of for analytics at the edge or the core depending on their architecture.
Aerospike and the Aerospike Connect product line brings great value to your data pipeline and we hope you will consider using them to build your low latency and high throughput data pipeline.
Learn More
Keep reading

Jul 21, 2026
KV cache tiering: Why GPU memory alone won't scale your LLM app

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX