Graph databases and signal loss in AdTech
Third-party cookie support is slowly becoming obsolete, and the shift is changing how the AdTech and MarTech spaces operate on a day-to-day basis. Will identity graphs pick up where cookies left off?

The AdTech landscape is undergoing a tectonic shift. With tech giants like Apple, Google, and Mozilla phasing out support for third-party cookies, traditional methods of tracking digital identities across the open internet are becoming obsolete. For advertisers, this means your go-to data signals for crafting digital identities are evaporating, and the implications of this signal loss are significant. So, how can the industry adapt to stay relevant?
While cookie deprecation isn’t new news, it remains a devastating blow to companies that have built identity resolution, personalization, targeting and retargeting, attribution, and other services based on the availability of cookies. Today, 47% of the open internet is already unaddressable because of cookie and device ID deprecation, rising to over 90% when cookies are deprecated from Google Chrome late in 2024. So, a foundational technology of an entire industry will stop working.
AdTech professionals are now rethinking how they will reach their audience at the type of scale at which they operate. In a recent conversation with Aerospike’s Daniel Landsman, Global Director of AdTech, and Ishaan Biswas, Director of Product Management, we explored the implications of signal loss and the technology solutions being used to address them.
Deterministic vs probabilistic models
“Advertisers focus on ROAS – return on advertising spend – a metric used to understand how the dollars that you’re spending on ads is helping you grow top line,” said Landsman. “The question is, how do you create that metric without cookies?” With cookies, AdTech companies had a deterministic way to track the customer journey. Without them, they are looking to leverage probabilistic models to understand the customer journey through their user flow and see how they’re interacting with the ad creatives.
“The bottom line is that for AdTech companies, predictable signals like cookies that were used for identifying users are going away or decreasing rapidly,” said Biswas. “So, they are going to have to embrace probabilistic models to accomplish the same tasks.” Companies that are the most effective are going to be able to holistically look at that customer journey, pulling signals from everywhere they can.
AdTech companies will need to take a “layer cake approach,” said Landsman, “leaning into first-party data, second-party data, and third-party data; wherever they can get it as signal loss continues.” This is also the case on the buy side with attribution. “People have been using last-click attribution and working with multi-touch attribution. Now, with signal loss, it’s becoming ever more challenging.” To answer this challenge, many firms are turning to identity graphs.
The role of identity graphs is to provide a holistic customer view. They consolidate customer data from various touchpoints, devices, and channels into a single, unified profile. This 360-degree view allows marketers to understand customer behavior comprehensively, helping them tailor more personalized and effective campaigns.
They can use this enriched view of their customers and target audience to provide more personalized content, recommendations, and offers to create a more engaging experience for consumers overall, leading to higher conversion rates.
In technology terms, identity graphs are best represented by a graph data model and stored, queried, and traversed from a graph database using a graph query language.
Considering the graph data model
As this widening array of signals becomes essential to a probabilistic approach, AdTech developers are taking a fresh look at the types of data models that make the most sense going forward. Many are looking at a graph data model to represent both the customer/user and their journey as well.
The graph data model represents data as a collection of data points (known as nodes or vertices) and relationships (also known as edges) that connect these nodes. The graph data model provides a natural, comprehensible representation of relationships – for instance, between people, their devices, their interests, their organizations, etc. It offers great flexibility in terms of data structure and schema.
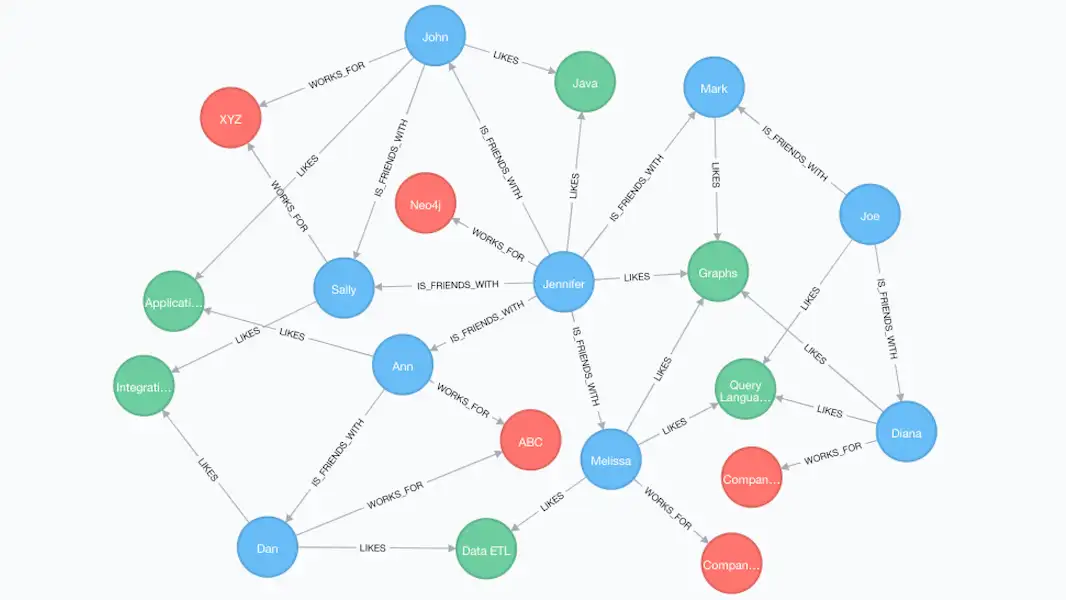
Figure 1: the graph data model easily handles the complexity of probabilistic identity models
Graphs enable you to very simply model customer behavior and journeys, optimize ad spend, and provide personalized ads. They also enable different views of individuals and groups that can be consolidated from different touchpoints and triggers. These might include location, demographics, buying patterns, and other behaviors that are better expressed as edges rather than nodes. One example might be using graph data to do cross-device tracking even in the absence of deterministic signals like cookies.
The graph data model is a natural fit for identity resolution in AdTech as it enables a richer, more sophisticated representation of identity that advertisers can use to improve targeting, attribution, and other imperatives such as Customer 360. A graph-powered 360-degree view enables marketers to understand customer behavior more comprehensively and to create more personalized and effective campaigns. “We believe that the graph data model is going to really help everybody transition to address audiences at scale for the open internet,” said Biswas.
Evaluation criteria for graph databases
Once you’ve decided on a graph data model, you will inevitably need to choose either a dedicated graph database or a multi-model database. Both are suitable, and each has its advantages, but we will leave that debate to a separate blog. Whichever you choose, there are some basic criteria that must be met for you to achieve your identity graph goals.
Model your data
One of the most compelling reasons to decide on a graph data model is how expressive and intuitive the model is. Therefore, it is important that a graph database that can help you model and store your data in a native graph format. The question is, how do you model users, devices, and cookies as vertices and edges? “The property graph model is really good at that,” said Biswas. “So the good thing is most graph databases out there in the market can do this. So this is well-established technology. So that’s the easy part.”
Native query language
Your graph database should support graph-native queries and traversal. While there are several, Gremlin and Cypher are the most common and can help you query and traverse graph data. Graph query languages make it easier to express relationships and traversals of the graph and retrieve your data efficiently.
Performance and scale
AdTech and MarTech systems that perform identity resolution – such as user profile stores, multi-touch attribution, ad auctions, etc. – are often dealing with millions or trillions of data points, translating into billions of vertices with thousands of edges each. That is going to take a special type of graph database. In AdTech, it inevitably becomes a problem of scale. People have started to look at graph database technologies that can process enormous amounts of data and get access to that in milliseconds and do that with predictable latency.
Horizontal scalability (ie adding nodes to a clustered database) to accommodate increasing data volumes both for data volumes and query throughput while maintaining low latency. That means single-digit or low double-digit milliseconds.
Note: for a more specific discussion of selection criteria for graph databases, see the blog What is behind the surging interest in graph databases?
Getting started – a 5-step process
In the spirit of starting you on your journey with an identity graph, we have laid out a five-step process that should ensure a smooth transition to the post-deterministic identity resolution using the graph data model and a graph database.
1. Define the business process/problem statement
First, you should define the business process for whatever you want to achieve. Whether you are fine-tuning your Customer 360 processes or creating an identity graph to power your ad auctions, you need to get prescriptive about those business processes. That should be done in collaboration between the technical and the business stakeholders in your organization. Define success metrics for functional and performance criteria.
2. Know the data, draft the schema
In order to query the data, you’ve got to define the data organization of your identity graph, in other words, the schema. To get there, you have to ask and answer these questions first:
What is the final goal you’re trying to achieve?
What are the business processes you want to implement?
What data do you have or need access to?
Who are the data brokers that you’re working with?
Once these questions are answered, you can define that schema. It’s going to be different for different organizations, depending on the data they have access to. And it will evolve over time.
3. Write out the queries
The intuitive nature of the graph data model enables you to construct your graph queries in plain language. So, begin imagining your queries by writing out what you want to do in plain language. Don’t worry about the underlying graph query language. Do your queries make sense?
4. Create sample data and Gremlin queries
Create a sample data set and load the data into the database. Then, you start querying the database. Write these queries based on the description you’ve written out in step one, and then you query the database. You have to iterate on this a few times because you’re not going to get it right the first time.
5. Scale, test, and optimize
Once you’re happy with what you’ve established, you scale and iterate untilyou achieve your success metrics. Once you have selected your graph database, you then bring in all of the data that you have, embed these queries in your applications, scale, and put it out there.
There are obviously a lot of nuances to each of these steps, but it’s a good general process you can follow to get started. You are going to have to iterate on data modeling, queries, schema, and scaling your database a few times until you achieve your desired performance goals.
Your next step with identity graphs
Aerospike has unique expertise with identity graphs by way of deployed solutions at Paypal, Adobe, Signal (now TransUnion), and Aqfer. You should also check out the webinar Beyond Identity – The pitfalls of not becoming identity agnostic in 2023, featuring Daniel Landsman. It describes how mission-critical identity resolution in AdTech is evolving due to changing market conditions. Their challenges may be a harbinger of similar issues being felt across industries such as ecommerce, retail, banking, gaming, and more.



