What is behind the surging interest in graph databases?
Graph databases are creating pathways for developers to explore new use cases for their organizations. Here’s a foundational understanding of what graph databases can do and how they will power both operational and analytical workloads.

Interest in graph databases is growing at an astonishing rate, according to Rita Sallam of Gartner. The analyst firm forecasts that “80% of data and analytics innovations will be made using graph technology by 2025.” Further, they estimate that by 2023, graph technology will play a role in the decision-making process for 30% of organizations worldwide. Others predict that the graph database market itself will grow at a CAGR of over 20% for the next five years. So, what is behind this interest and growth? In a hyper-personalized, highly automated world, the difference is in understanding relationships, not just metrics.
The graph data model is unique in that it not only manages data points (known as nodes or vertices) but also the relationships between data points (known as edges). In graph databases, edges are first-class citizens and are as important as the data points themselves.
Here is a very basic example of the graph data model. In this diagram, there are three nodes – two designated as Person (John and Sally) and one Book (Graph Databases). The edges represent the relationship between the nodes: John “IS_FRIENDS_WITH” Sally. And each “HAS_READ” the book on graph databases. Easy, right? One of the advantages of the graph model is that it is intuitively apparent what the model represents and that by traversing the graph, you can gain interesting insights.
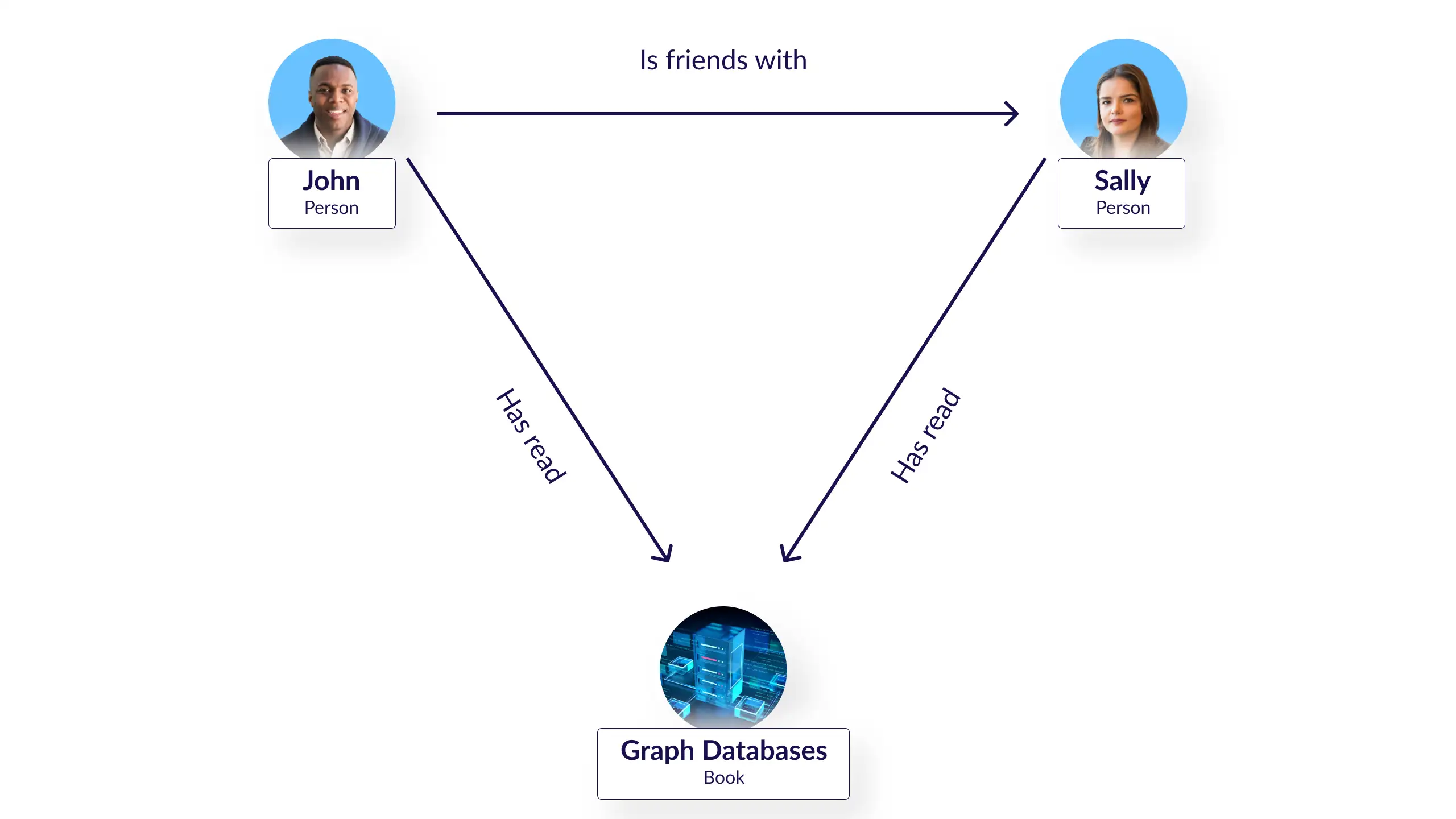
With the above example, an enterprising programmer could figure out a way to store and query the data and the relationships in another database. However, this approach becomes less desirable when you look at a larger graph dataset. What if you are looking at millions of vertices and billions of edges? For the increasingly sophisticated and larger scale graph datasets, only a graph data model and a graph database are going to suffice.
What graph databases do
First and foremost, graph databases store, manage, query, and traverse graph data. To be effective and performant, they must be able to store graph data (vertices and edges) in a format that is optimized for graph traversals. A graph database must then support querying that data via a query language – such as Gremlin or Cypher – that can efficiently retrieve and process graph data. Then the question becomes: what then?
Although graph theory has been around for hundreds of years, and graph databases since the 1960s, modern graph databases – that can support ACID transactions and cloud deployment – didn’t appear until the mid-2000s. Since then, their use has accelerated, and the number and variety of use cases have grown substantially.
Roughly speaking, graph databases are used in two main categories of use cases: analytical and operational.
Analytical graph use cases
Analytical graph use cases serve a Business Intelligence (BI) function and rely on the intuitive nature of the graph data model to enable business analysts to explore the relationship between people, things, events, etc. This is typically done interactively on relatively static graph datasets. This is also referred to as OLAP (online analytical processing) graph workloads. This is when visualization tools are applied to graph data by BI teams to traverse or query graph datasets to gain insights about those relationships.
Some of the most common examples of analytical graph use cases include knowledge graphs that might anticipate drug interactions in healthcare, data exploration and visualization for data scientists to discover complex patterns in their data, and network analysis in telecoms to optimize data routing.
Operational graph use cases
Operational graph use cases are associated with highly dynamic transactional environments to solve mission-critical operational problems such as identity resolution in AdTech and MarTech, real-time fraud detection in banking, and real-time personalization and recommendations in e-commerce, telecom, or even online banking. These are often referred to as OLTP (online transaction processing) graph use cases because of their real-time nature and the larger volume of the underlying datasets amid frequent database reads, writes, and updates.
Explore graph databases
Once you can grasp the essence of the graph data model, you begin to see potential graph applications everywhere. The key benefit of employing a graph database is the exciting new use cases that become possible with the graph data model and a high-performance, scalable graph database like Aerospike Graph.
Operational graph databases are typically used for real-time, transactional, and interactive use cases that require quick access to and manipulation of connected data (OLTP). Analytical graph databases are more suitable for complex data analysis, knowledge graphs, and data exploration tasks that involve graph processing of static data (OLAP). However, the distinction between these categories can blur, and some graph databases can be used effectively for both operational and analytical use cases.
Aerospike Graph has finally cracked the code for delivering a highly scalable, low-latency graph database that can serve both operational and analytical use cases. It can deliver millisecond multi-hop graph queries at extreme throughput across billions of vertices and trillions of edges. We’ve benchmarked the product, showing a throughput of more than 100,000 queries per second with sub-5ms latency — on a fraction of the infrastructure of other solutions.
Aerospike Graph was specifically designed to address the challenges of operational graph use cases. Some common examples of operational graph use cases include identity graphs such as those used by Signal (now TransUnion), advanced fraud detection as deployed by PayPal, and mass personalization in the Adobe Experience Platform.
Explore Aerospike Graph with a free trial
So, take a further step into the graph world by learning more about Aerospike Graph, checking out the tutorial, or trying the product today.