Blog
Aerospike Graph: A deep dive into its architecture
Aerospike Graph enhances graph processing capabilities through tailored customizations and integrates with Apache TinkerPop for high performance and scalability in graph query processing.
Blog
Aerospike Graph enhances graph processing capabilities through tailored customizations and integrates with Apache TinkerPop for high performance and scalability in graph query processing.
Aerospike Graph implements and adds sophisticated customizations to the Apache TinkerPop graph computing framework tailored for the Aerospike Database to provide high performance and independent scalability for graph query processing. The core architecture diagram provides a structured view of how various components interact within the system. In this article, we will dissect the architecture and design of Aerospike Graph, detailing how it enhances the graph processing capabilities.
Gremlin serves as the graph query and traversal language for Apache TinkerPop. It is a functional, data-flow language designed to allow users to succinctly articulate complex traversals and queries on their application's property graph.
Each Gremlin traversal is a sequence of steps, which may be nested. These steps perform atomic operations on the data stream. Steps can be categorized into three types: map-steps, which transform objects in the stream; filter-steps, which remove objects from the stream; and sideEffect-steps, which compute statistics about the stream.
The Gremlin step library expands on these fundamental operations to offer a comprehensive set of steps, enabling users to pose any imaginable query to their data, given Gremlin's Turing Complete nature.
Gremlin Server serves as the host process and query protocol server. At startup, the Aerospike Graph implementation FireflyGraph.class is loaded and used to construct a graph instance, then made available to queries under the traversal source name “g.” Multiple graphs may be exposed under additional traversal source names by configuring the Gremlin Server: g.V().has(“color”,“blue”) versus m.V().has(“color”,“blue”)
FireflyGraph initializes several background tasks upon startup, including metadata analysis and a garbage collection routine for managing expired graph elements.
When a client establishes a connection to the Gremlin Server, authentication handlers are triggered to verify the client's credentials. Successful authentication associates an authenticated user object with the connection, securing the session. Upon receiving a query, the server constructs a JavaTranslator object that transforms the query into a traversal bound to the specific graph implementation. This process maps each step in the query, along with its arguments, to a default TinkerPop step implementation.
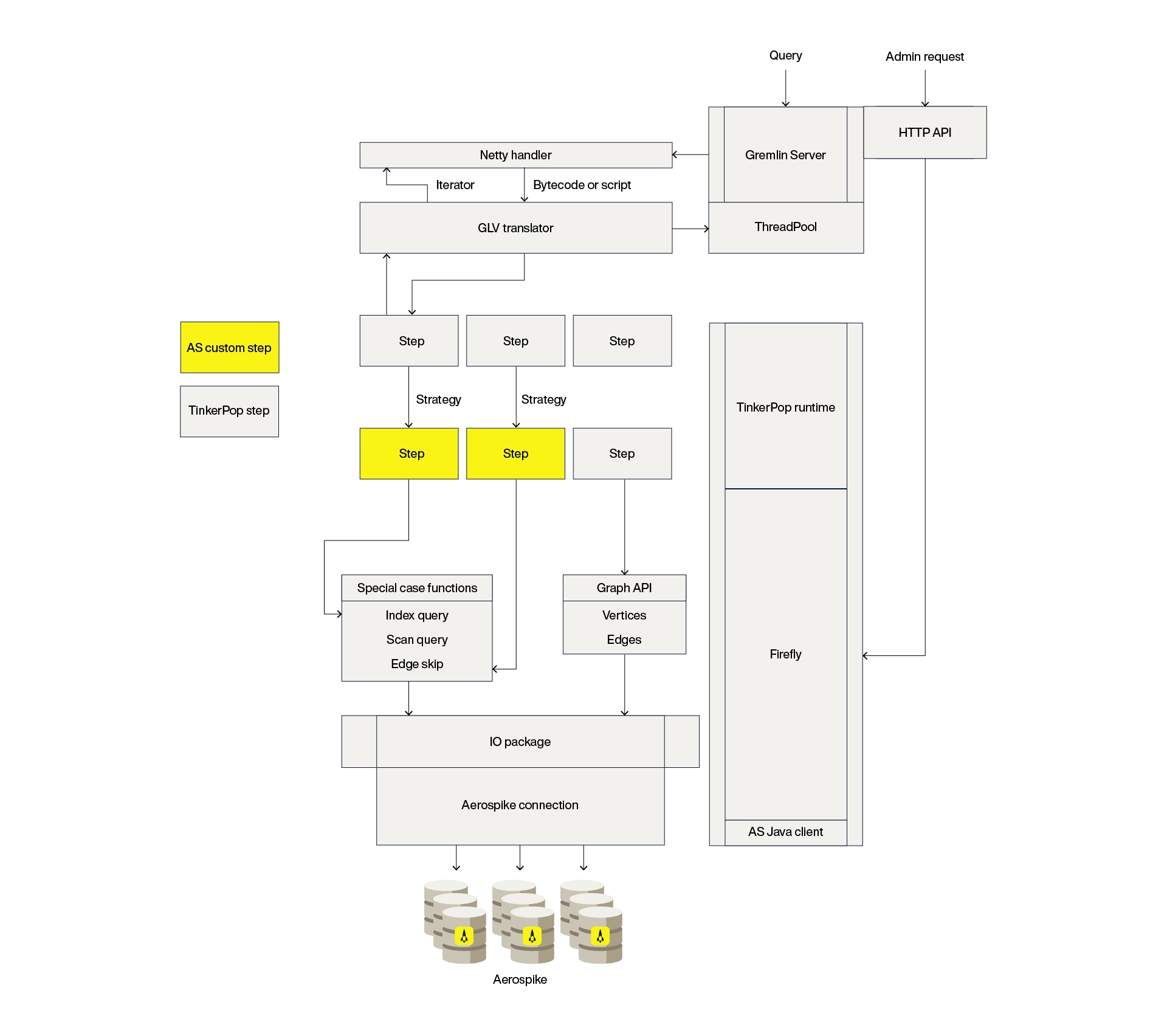
When a query is initially evaluated, it is transformed into a traversal, and then strategies are applied to inject specific optimizations. These strategies replace the default TinkerPop step implementations with customized Aerospike-specific steps. The optimized traversal is then converted into a result iterator, which is returned to the client through the connection handler.
Over 15 steps and traversal patterns have been optimized using real-world datasets and query patterns. Following are a select few strategies to give the reader a flavor of what these optimizations look like.
Common queries involve steps that return vertices (like out() or in()). Instead of processing each step separately, this is converted into a single Aerospike Graph step.
This step uses a vertex adjacency cache, which lists all connected edges and vertex IDs. This way, Aerospike Graph can skip reading each edge individually and directly read the connected vertices in batches, making the process faster.
HasSteps that follow a VertexStep are also removed and placed inside the step mentioned above. The HasStep is compiled into a list of predicates that are pushed down to Aerospike on the batch read of vertices.
Any steps that perform limit() or sample() after the VertexStep are also pushed into the step. This allows early exiting of the step after the required number of items are read.
In native TinkerPop, sample() will read every single element and randomly select the input number of items. In the custom step, the adjacency caches are used to calculate the total number of items from which the required elements are sampled and then read.
This leads to a drastic reduction of IO operations for sample() and limit().
Properties are stored on the vertex in a Map<String, Object>. Queries are inspected at runtime for required properties, and MapOperations are pushed onto Aerospike only to grab the required properties of a traversal. This means as properties scale, only the required properties are grabbed. So, the system stays performant even as data volumes grow.
Steps that count the number of edges or adjacent vertices of a vertex are converted to a quick local count inside the cache.
Additionally, steps that run larger counts run queries on Aerospike without bin data, allowing just IDs to be counted, improving performance, and lowering the queries' network and memory usage.
Supernodes run secondary index queries to collect adjacent edges. Predicates can be pushed down on these supernodes, allowing users to step out on supernodes with a predicate and obtain extremely fast performance.
These are just a few examples illustrating the customizations applied to the default TinkerPop runtime.
The core of Aerospike Graph's efficiency lies in its ability to map graph structure—vertices and edges—directly to the Aerospike data layout via calls to the IO layer. Aerospike-specific steps can bypass the standard graph layer, converting some TinkerPop operations directly into IO layer calls. Operations such as index queries, vertex-to-vertex traversal patterns, and other graph manipulations like drop and count can be efficiently executed at this layer. When reading data, Aerospike Graph frequently uses batch operations on the Aerospike Database.
Converting arguments into Aerospike Expressions may enhance steps. These expressions facilitate index filtering or selection of specific record data, boosting query performance.
If RBAC, a feature now available with version 2.1, is enabled, the bytecode of a query is analyzed in the context of the authenticated user's roles. If the user lacks the necessary permissions, the query is rejected. Otherwise, the user's credentials are embedded within the bytecode, and a traversal strategy ensures these credentials are considered during query execution.
Administrative commands are accessible via HTTP endpoints (as of 2.1) and Gremlin call(...) steps. These commands enable tasks like dataset loading and metadata querying. Administrative commands are secured by the same authentication mechanism for both HTTP and Gremlin protocols.
Now, let's transition from understanding how Aerospike Graph processes queries and manages operations to look at the specific ways in which the graph's structural components—vertices and edges—are stored and managed.
This shift from a broad architectural perspective to a detailed exploration of data storage practices allows us to appreciate not only how Aerospike Graph is engineered to handle high-performance graph operations but also the underlying data organization that enables such capabilities. By examining the storage structures of the VERTICES and EDGES sets, we can better understand Aerospike Graph's efficiency and scalability, which are crucial for applications requiring rapid access and manipulation of complex graph relationships.
Aerospike Graph employs a unique data model to manage its graph structure, primarily composed of two sets: VERTICES and EDGES. This model is designed to leverage Aerospike's strengths in handling large volumes of data while ensuring efficient access and manipulation of graph relationships. This mapping is illustrated in Figure 2 below.
Below, we delve into how vertices and edges are stored and interact within the Aerospike Graph.
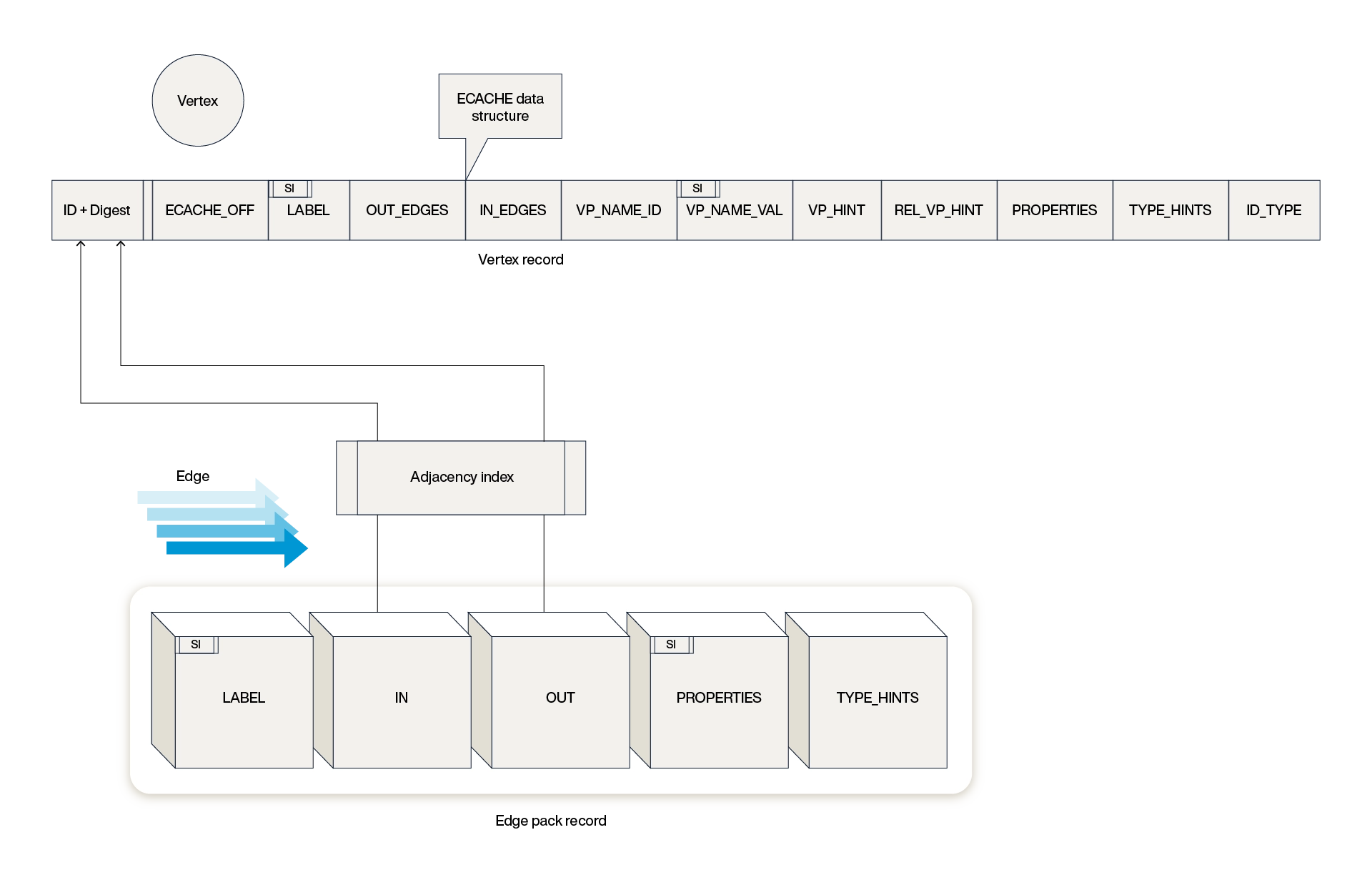
Each vertex is stored as an individual record within the VERTICES set. The key design principle is the 1:1 mapping between a TinkerPop Vertex and an Aerospike record, ensuring a straightforward translation from graph to database elements.
ID and digest: Each vertex record contains a unique identifier, which can be user-provided or system-generated, coupled with a digest for rapid lookup.
Label and properties: Vertex records store data, including the vertex label, property key-value pairs, and edge cache.
Edge cache: To optimize edge traversal operations, a limited size list of edge identifiers, labels, and opposing vertex identifiers is maintained within each vertex record. This cache provides quick access to adjacency information without needing to run index queries.
Supernode handling: If a vertex has more connections than the edge cache can accommodate, it is designated as a "supernode." For such vertices, additional edges are referenced exclusively in the EDGES set, bypassing the vertex's local cache. This allows some vertices to have unlimited connectivity by trading off direct fetch performance for index query performance.
Edges are grouped into "packs" within the EDGES set, where each pack contains a configurable number of edges, typically ten. This packing strategy makes efficient use of primary index memory.
Connection information: Each edge within a pack includes the Aerospike Record digests for the two vertices it connects, ensuring that edge queries can accurately reflect the graph's topology.
Label and properties: Similar to vertices, edges also carry labels and a map of key-value pairs for their properties, enriching the graph's semantic structure.
Adjacency index: For edges connected to supernodes, an adjacency index is populated to maintain the link when space is unavailable on the vertex records. This index is crucial for managing supernode adjacency information, which has no upper-size bound.
Supernodes represent a significant challenge in graph databases due to their high connectivity. In Aerospike Graph, supernodes are efficiently managed by storing overflow edges in the EDGES set and utilizing adjacency indices to maintain connectivity without compromising performance. This approach minimizes the memory footprint on vertex records and leverages Aerospike’s high-performance read/write capabilities for edge traversal.
In version 2.1, index filter expressions are utilized to reduce the number of edges processed when interacting with a supernode by selecting only edges with particular property values.
Aerospike Graph is designed to provide high performance, scalability, and security for graph database operations. By integrating closely with Apache TinkerPop and leveraging Aerospike's powerful data handling capabilities, Aerospike Graph offers a robust platform for complex graph processing tasks. This system ensures efficient data management, supports dynamic query optimization, and provides secure access control, making it an excellent choice for enterprise graph database applications.
The Aerospike Graph data model is tailored to harness the power of Aerospike's distributed database architecture, enabling it to manage extensive graph data sets with high performance and reliability. Aerospike Graph effectively supports dynamic graph-based applications by separating vertex and edge storage into distinct sets and using intelligent caching and indexing strategies. This ensures scalability and swift access patterns, which are crucial for real-time graph use cases.
For a deeper understanding and more insights, explore these additional resources.
See more