At Aerospike Summit 2023, Aerospike Product Manager Ishaan Biswas was joined by two fellow graph experts, George Anadiotis, founder of Linked Data Orchestration, and Marko Rodriguez, Managing Partner at PhaseShift Studio and creator of the Apache TinkerPop graph computing framework, for a conversation on the power of graph databases. The three had an in-depth discussion on Aerospike Graph and graph systems in general. They discussed everything from analyzing the current graph market to the criteria developers, architects, and IT decision-makers must evaluate before introducing a graph database into a tech stack. Here’s a look at the main takeaways from their discussion.
What are graph databases?
Biswas: “What are graph databases, and how should developers and architects think about them?”
Our solution brief defines Aerospike Graph as “an engineered graph database that enables low latency, multihop graph queries at a very large scale based on widely adopted graph technologies and practices.” In simpler and more general terms, graph databases are designed to handle large amounts of “connected data” and enable developers and architects to leverage the graph data model to address complex computing challenges such as identity resolution and advanced fraud detection.
In response to Biswas’ question above, George Anadiotis takes a step back – all the way back to 1736 – when Swiss mathematician Leonhard Euler crafted the Seven Bridges of Königsberg problem. His task was to figure out how to navigate the entire town of Königsberg while crossing each of its seven bridges only once, without overlap. “By trying to formulate that problem, he basically invented graph theory.”
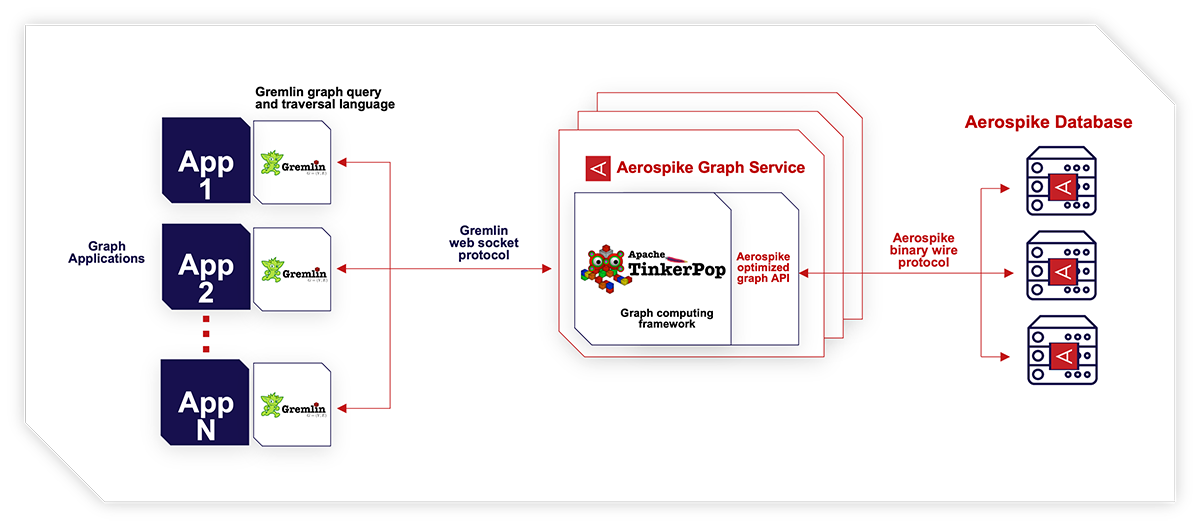
The Aerospike Graph architecture
Watch the video to see how Anadiotis breaks down how graph APIs fit into the mix, the similarities and differences between traditional relational databases and graph databases, and how to get the most out of your basic CRUD (create, read, update, delete) operations using graph.
Download the Aerospike Graph solution brief to see how graph databases are applied in various use cases, such as identity graphs in AdTech, customer 360, and real-time fraud prevention.
Analyzing the current graph market
Biswas: “What are you seeing in the industry right now among database developers, architects, and decision-makers in terms of interest in the graph data model – and graph databases in particular?”
The graph market reached an inflection point in 2019 when it was first mentioned in the Gartner HypeCycle for Emerging Technologies. Then, it was making its way from the “peak of inflated expectations” to the “trough of disillusionment.” In the interim, the graph market has been inching toward the “slope of enlightenment” as it has grown from $700 million in 2018 to approximately $2.9 billion today, a mark of continued substantial growth.
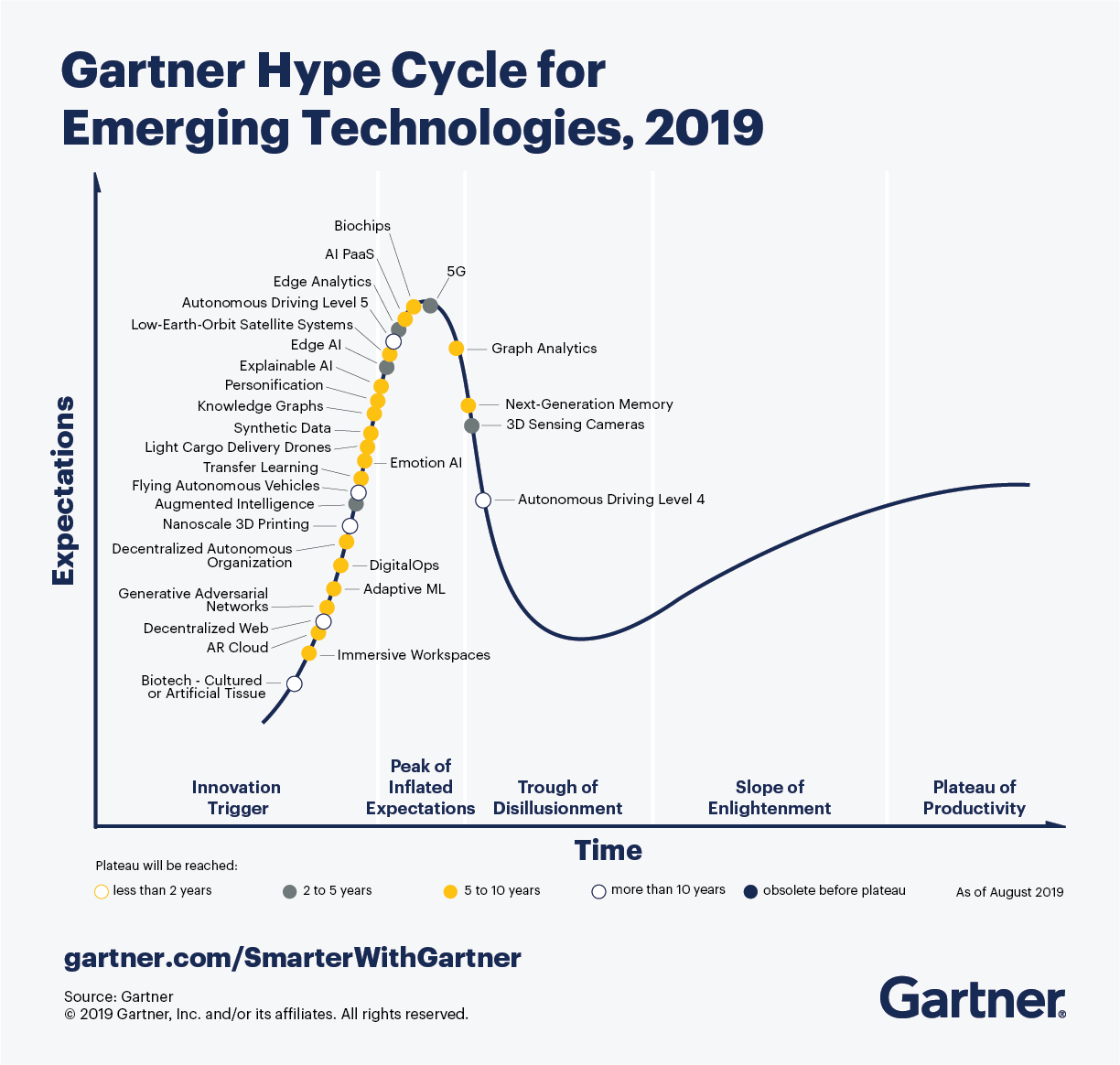
In this video from their session, Anadiotis doesn’t give all the credit to the simple matter of there being more data than ever. He attributes the rise of the graph market more so to its functionality; in other words, “it’s about the connections, and graph is the best way that you can leverage connections,” he says.
Adopting a graph data model
Biswas: “When you start looking at a graph database, how do you think about the world differently compared to SQL? What should architects and developers think about – what should their approach be – when we start looking at the graph data model?”
Moving from SQL to a graph data model is a paradigm shift. Whereas SQL’s schema is expressed in tables, graph data is all about “moving between connections,” as Marko Rodriguez states. Those connections are made up of vertices and edges, but it’s the visualization capabilities that allow developers to feel immersed in their data sets. Still, the requirements and the knowledge base for one and the other are quite different. Watch the full video to see Marko parse their differences and get a good idea of what’s available in Aerospike Graph with the help of G.V(), a Gremlin integrated developer environment (IDE) that enables these helpful graph visualizations.
Learn more about adopting a graph data model from this webinar clip. For a more granular, deep dive into what developers can do with a graph data integration, watch our DevChat, “Aerospike Graph for developers.”
Evaluating graph databases
Biswas: “For people who are starting to evaluate graph databases or those who have a home-grown solution to do some sort of graph functionality, if they’re looking to buy a commercial database, what are the criteria they should be looking at to make this decision?”
Hard criteria assessment
Anadiotis has a two-pronged approach when evaluating what graph databases offer – a hard and a soft criteria assessment. The core principal factors in the hard criteria are performance, scalability, and cost, though he does stress “that they’re also very, very hard to actually evaluate in an objective way.” The only way to truly determine if a graph database is a right fit is to conduct your own hands-on testing.
Analytics is another notable factor. Anadiotis recommends considering a database’s support for analytics, particularly when creating knowledge graphs. And finally, evaluate how easily data can be imported and exported.
Soft criteria assessment
Anadiotis’ soft criteria assessment starts with how developer-friendly the database in question is. Is there IDE support for enhanced productivity? He also brings up operational agility; before adopting a database solution, it’s mission-critical to consider the best available option for deployment – on-premises, in the cloud, or even with Kubernetes. Finally, is there any community support or vendor support that can serve as a first line of assistance in trying to find the resolution to a problem?
Watch this video for more details on what to know and assess before biting the bullet on a graph database solution. The clip also provides details on the Aerospike Graph approach and how it integrates with Apache Tinkerpop. For a more holistic exploration, read our blog, “A developer’s introduction to graph databases.”
Scaling graph databases
Biswas: “There are commercial solutions available out there that have more and more data that are increasingly getting more highly connected datasets, but they don’t have a ready-made solution that can scale to large amounts of data volume and still provide known levels of latency and high levels of throughput. Why is it that a hard problem to solve?”
The supernode problem
Marko Rodriguez points out a common issue: “the supernode problem.” A supernode is a vertex with a relatively abundant amount of edges. “When you work with a graph model, or you put that in the graph database, you have a particular vertex, and then you have to store all those edges colocated with that vertex, and so you get these hot spots where your traversals are ultimately always going through that same vertex.” In other words, that vertex is getting bombarded, creating a substantial performance bottleneck. Aerospike handles the supernode problem by partitioning heavy vertices among multiple sibling vertices, enhancing efficiency.
Managing bidirectional pointers between vertices on different machines poses a challenge, requiring careful data consistency handling. In other words, if you delete an edge on one machine, and it references an edge on another machine, there must be a seamless sync between the two. If not, this can lead to data consistency issues, creating “ghost edges.” These half-edges emphasize the importance of establishing in-sync cleanup mechanisms for smoother system performance.
Check out this video to see what Marko says about Aerospike’s compound index lookups and how they provide a seamless entry point into the data, contrasting with issues in other graph databases’ initial jumps. For more information, download our white paper, “A graph database designed for scalability.”
Explore data connections with Aerospike Graph
Aerospike Graph is developer-ready, highly scalable, and designed to meet and exceed the requirements of the most demanding large-scale property graph database workloads. Try it out for free.