Introducing Aerospike 8.1.2: Making nested data queries fast and easy to write
Aerospike Database 8.1.2 brings path expressions to GA, enabling server-side filtering and projection across nested document structures. Get 40% more throughput, 30% lower p99 latency, and cleaner application code.
Ronen Botzer Director of Product Published April 16, 2026 Read time 9 min read
Document modeling is ubiquitous in modern software architecture. Many developers gravitate naturally toward JSON-like structures because they mirror the objects used in their code. Whether it is a product catalog, a user profile, or a complex financial ledger, the ability to store data as a document (a rich hierarchy of maps and lists) has become the industry standard for this class of application.
For years, Aerospike has served as a high-performance backbone for these applications. However, developers working with repeating nested structures often hit a friction point. While Aerospike could store a list of map elements efficiently, retrieving specific values from within that structure was a different matter. Without granular, server-side traversal, developers typically faced a choice: pull the entire record across the network and filter it in application code, or compromise on the data model itself. Both options added complexity and cost.
With the release of Aerospike Database 8.1.2, we are removing that friction. Path expressions, previewed in 8.1.1 and now generally available in 8.1.2, represent a paradigm shift in how Aerospike handles nested data, offering a seamless, high-performance developer experience for querying documents with the compute done efficiently on the server side.
The missing link in document modeling
Previously, a meaningful usability gap existed for developers modeling data as a list or map of repeating structures. Imagine a vehicle registry where each record contains a list of vehicle objects, each a composite of attributes like color, make, and license plate number. (The docs include a full example of this pattern, showing how to query across all vehicles to find, say, every Honda or every blue car in the registry.)
Before path expressions, querying this list required a "retrieve and filter" approach; the application had to pull the entire list across the network and manually iterate through the entries. This resulted in higher end-to-end latency and required extensive client-side code.
Path expressions close this gap by providing a native way to navigate these repeating structures. They serve two purposes within the steps of a query:
Finding the right records (querying and indexing): By combining path expressions with expression indexes, you can create a secondary index on data nested deep within a document. This allows the database to identify only the records that match a given nested criterion, such as finding all vehicles with a specific make and model, without a full scan of the registry.
Projecting the right data (extraction): Once the correct records are matched, path expressions act as a precise tool for projection, returning only the specific bin (column) or nested element requested rather than the entire document. Instead of shipping a large record across the network so the application can extract a single field, the server navigates directly to that field and returns only what is needed.
The efficiency shift: Moving compute to the server
Customers who participated in the 8.1.1 preview validated that moving filtering and projection logic to the server was the right direction. Those who tested path expressions saw the performance difference directly, and their feedback shaped the optimizations in 8.1.2 that make efficient server-side traversal the natural path for developers, not just the possible one. By moving filtering and projection logic to the database server rather than the application layer, the amount of data transmitted across the network is reduced substantially. The application code that used to handle that logic disappears with it.
Three effects follow from this shift:
Reduced memory allocation: When the server filters before serializing a response, it produces and transmits only the net result. The application no longer needs to deserialize a large record and instantiate a collection of temporary objects just to extract a small subset of data.
Network efficiency: Only the relevant projected results travel over the wire, freeing up bandwidth and increasing effective throughput.
Cleaner developer experience: The find-and-project logic lives in the database, not in application code. The multi-line filtering loops that used to live in microservices are replaced with a single, expressive server-side operation.
One of our development partners, a major travel and e-commerce platform serving hundreds of millions of users worldwide, shared this after testing:
"The path expression feature has demonstrated excellent results in our current environment. Our metrics confirm lower resource overhead and more predictable latency compared to current operations, making it a pivotal component for our upcoming deployment. The feature test has achieved promising results that should save a meaningful amount of hardware costs and improve performance." - Development partner, major travel and e-commerce platform
Performance results: Proven at scale
The efficiency gains described above are not theoretical. Moving filtering and projection logic to the server reduces the volume of data transmitted across the network, and that reduction shows up directly in throughput and latency.
To quantify the impact, Aerospike's internal performance team benchmarked on 8.1.2 against client-side filtering as the baseline.
Testing was read-only, consistent with the filtering and projection use case this feature is designed for. Performance is affected by factors such as object size and filter complexity, so we recommend testing against your own workload to understand the impact in your environment.
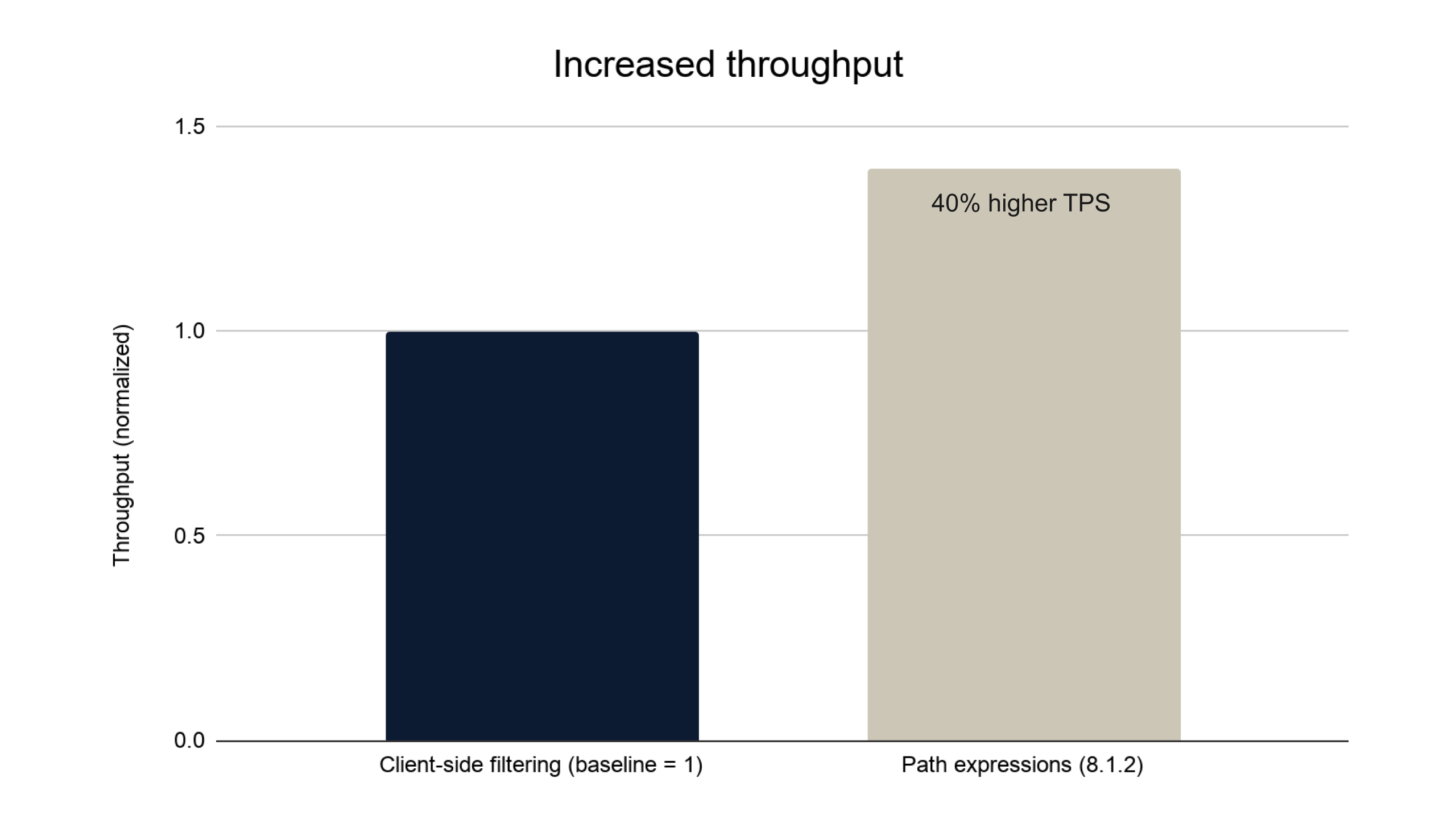
Throughput
With client-side filtering, the full record travels across the network before any filtering occurs. With server-side path expressions, only the matching result is transmitted. That reduction in data on the wire translates directly into more transactions per second.
Chart 1: Improved throughput with path expressions
Path expressions on 8.1.2 deliver approximately 40% more transactions per second than client-side filtering.
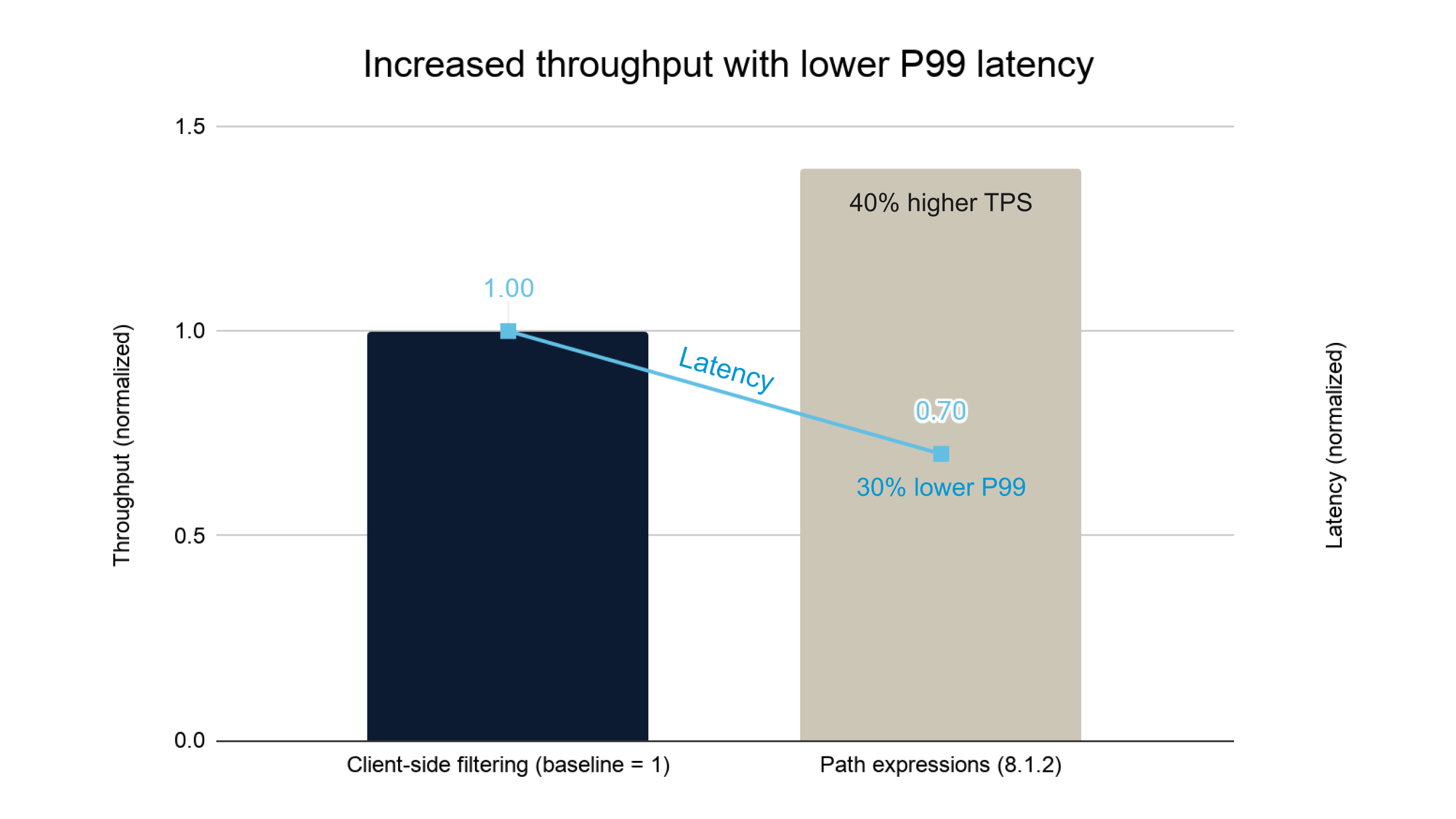
Throughput and latency
The same shift that increases throughput also reduces end-to-end p99 latency by approximately 30%. More work gets done, and each operation completes faster.
Chart 2: Lower latency with path expressions
Technical deep dive: How we got here
Performance and developer experience are both table stakes, and they are often linked: code that is hard to write correctly is also code that underperforms. Path expressions eliminate client-side filtering entirely, and the preview process helped us make sure they deliver on both fronts.
To make it concrete, consider the hotel booking scenario introduced earlier. Each Aerospike record represents a single hotel, with its room details nested within it, as shown in the JSON below.
The application needs to check whether a specific subset of rooms is available for a given date. Expressed as a SQL-like filter for clarity:
WHERE roomIds IN [101, 102, 400, 401] AND time > 1780000000AND isBooked IS false
All three approaches below are server-side path expressions, a meaningful step forward from the client-side filtering that came before. Moving to any of them eliminates the network overhead of transmitting full records. The preview gave us the opportunity to observe how developers used path expressions against real workloads, and that directly informed the optimizations that shipped in 8.1.2.
The first implementation most developers reached for during the preview was a natural one: visit every room in the document and apply all three filter conditions to each one.
Operation op = CdtOperation.selectByPath("rooms", SelectFlags.MATCHING_TREE | SelectFlags.NO_FAIL, CTX.allChildrenWithFilter(Exp.and(roomIdExp, timeCheckExp, availableExp)), CTX.allChildren(), CTX.allChildren());Record record = client.operate(null, key, op);
Approach A: Naive, server-side traversal, visits all the rooms, and applies three expressions.
This works, and it is already a win over client-side filtering. But it does more traversal work than necessary, evaluating every room regardless of whether it is in the target subset. A more deliberate restructuring, narrowing the room subset first and then applying the remaining conditions only to that smaller set, produces significantly better performance. Preview feedback confirmed this pattern and made clear that the API itself should guide developers there automatically, rather than requiring them to know to restructure the query manually.
In 8.1.2, the new CTX.mapKeysIn and CTX.andFilter APIs encode that optimized pattern directly. The developer no longer needs to understand the internal map index or know how to separate the key lookup from the filter conditions. The efficient path is now the natural path.
Operation op = CdtOperation.selectByPath("rooms", SelectFlags.MATCHING_TREE | SelectFlags.NO_FAIL, CTX.mapKeysIn(roomIdArray), CTX.andFilter(Exp.and(timeCheckExp, availableExp)), CTX.allChildren(), CTX.allChildren());Record record = client.operate(null, key, op);
Approach C: optimized traversal, more efficient code guided automatically by CTX.mapKeysIn
Approach A runs in O(N x M) time, meaning the server visits every room and evaluates every condition against it, doing work proportional to the number of rooms multiplied by the number of conditions. Approach B runs in O(N log M), using the internal map index to skip directly to the target keys rather than scanning every entry. Approach C completely avoids the cost of computing the submap (step 1 of Approach B) and does the walk and compare in place. In a hotel record with hundreds of rooms, that difference is substantial. The main change from B to C is the experience of getting there: in 8.1.2, the efficient path is also the obvious one.
Other 8.1.2 features
Path expressions are the centerpiece of this release, but 8.1.2 also ships several targeted improvements worth noting.
Tighter access control for set indexes: Previously, managing set indexes required dynamic configuration access, which required broader privileges than the task actually warranted. Set indexes are now managed through the same mechanism as secondary indexes, using the sindex-admin privilege. This brings access control for set indexes in line with the rest of the indexing system and reduces unnecessary exposure of privileges.
More control over tomb-raider parallelism: Tomb-raider is Aerospike's internal process for reclaiming storage occupied by expired or deleted records. On index-on-flash deployments, this release gives operators improved controls over how aggressively tomb-raider runs, making it easier to balance background cleanup against foreground traffic.
Granular memory stats for containerized deployments: Operators running Aerospike in containers now have enhanced visibility into memory allocation patterns, making it easier to right-size deployments and diagnose memory pressure.
AlmaLinux 9 and 10 support. AlmaLinux 9 and 10 support. After an extended validation period, Aerospike now formally supports AlmaLinux 9 and 10 through our el9 and el10 RPMs. AlmaLinux and Rocky Linux are both community-driven, enterprise-grade alternatives to RHEL, and supporting both gives operators running production Aerospike deployments a fully supported path that does not require a commercial Linux subscription. If you have been waiting for AlmaLinux support before standardizing your deployment, the wait is over.
Explore unrestricted document modeling with Aerospike 8.1.2
Aerospike Database delivers the predictable control that engineers need when operating at the edge of scale. Path expressions, now generally available in 8.1.2, give developers the full expressive power of nested data modeling without the performance compromises that came with it before. Server-side filtering and projection reduce network overhead substantially; the performance results confirm it, and the efficiency of the 8.1.2 implementation extends those gains further still: developers get cleaner code, operations teams get lower resource overhead, and the data model no longer has to bend to accommodate the database.
Try Aerospike Cloud
Break through barriers with the lightning-fast, scalable, yet affordable Aerospike distributed NoSQL database. With this fully managed DBaaS, you can go from start to scale in minutes.