Caching doesn’t work the way you think it does
Unpack the misconceptions, benefits, and intricacies of caching and its impact on system performance.

You certainly don't need a computer science degree to understand caching, and you might even think it's quite a basic concept. So, you might wonder if this article is worth reading, and who am I to tell you otherwise? But here's the thing: What I wrote in this article (and the ones that follow) is the culmination of over a decade's worth of experience I've gathered as a software engineer, building high-performance, complex, and distributed systems.
Looking at our application development practices reveals fundamental misconceptions or oversights regarding caching, leading to a significant waste of time, financial resources, and missed opportunities. Whether you're utilizing a caching technology, relying on an internal caching mechanism within a technology, or building a cache within your own application, grasping these nuances is invaluable.
The basics of caching
Let's start by addressing some basic questions.
What is caching?
Caching is the process of storing selected data from a larger, slower dataset in a faster storage medium for quicker access.
Why not store all data in faster storage?
Faster storage is typically limited in size, more costly, and sometimes volatile, making it impractical for storing all data.
Is there a common pattern for using a cache?
Caching is widely used in computing. For example, the CPU of the device you're currently using likely incorporates two to four caching levels. In software engineering, though, caching often refers to placing a volatile, in-memory datastore in front of a slower, persistent database.
Can a database and cache be combined?
Indeed! Many database technologies come equipped with an internal caching layer. Notable examples include MongoDB, CouchBase, and ScyllaDB. But, it is common to place caching technologies like Memcached, Redis, and ElastiCache in front of databases that tend to exhibit slower performance characteristics—such as RDBMS, Cassandra, or DynamoDB to improve their performance.
Can integrating a caching layer speed up an application that suffers from slow database access?
No!
Easy tiger. Let me explain.
But before we proceed, let's clarify what I mean by speed. In the context of a computer system, when a request is sent to the system, and a response is received promptly, we consider that system fast. Therefore, speed is intrinsically linked to response time.
However, computer systems are complex. Under a heavy load, a system's response time can significantly differ from its performance under a minimal workload. We evaluate speed using latency percentiles to account comprehensively for both good and bad scenarios encountered during request processing.
So, what is a latency percentile?

I know … bear with me. It’s worth it.
Understanding latency percentiles
Consider the process of logging a system’s response times over a prolonged period of time. After collecting this data, we arrange the response times in ascending order from the slowest to the fastest. The value in the middle of this ordered sequence is the 50th percentile, or P50, of the system's latency. If the P50 is T seconds, this indicates that half of the system's responses are slower than T seconds. The value at the 9/10th position of the list, denoted as P90, shows the time by which 90% of the requests were completed. Similarly, we can define other percentiles, such as P95, P99, or P99.9, each representing the time within which a respective percentage of requests have been fulfilled.
When plotting the latencies of distributed systems, such as modern databases, the resulting graph often mirrors the profile of a hockey stick. The details of the latency graphs for various technologies may vary, though they generally conform to the illustrated pattern below.
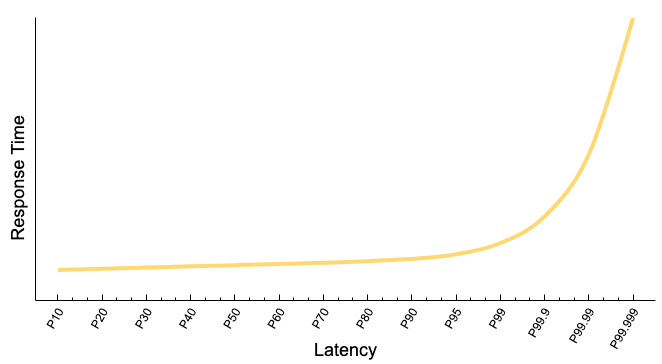
Notice that the difference in response time between the P10 and the P90 is significantly smaller compared to the sharp increase from the P99 to the P99.9. This disparity is rooted in the unpredictable behavior of distributed systems. To illustrate, let's consider a system prone to two adverse events:
Garbage collection:
Chance of occurrence: 1%
Average duration: 2 ms
Random network packet loss:
Chance of occurrence: 0.1%
Retrying period: 2 seconds
Given these conditions, the occurrence of a garbage collection event, with a 1% probability, would delay response times at the P99 percentile and above by 2 ms. Similarly, at the P99.9 percentile, responses could be delayed by two seconds due to the 0.1% chance of experiencing network packet loss. Moreover, the cumulative probabilities of experiencing multiple adverse events—such as a packet loss followed by garbage collection, two consecutive packet losses, and so on—further exacerbate latency disparities at higher percentiles. This scenario underscores the complexity of managing performance in distributed systems, where rare events can significantly impact latency.
If you’ve never thought about latency like that, you are welcome.

Now, let's return our attention to the main topic of the discussion: caching.
The importance of the cache hit rate
Regardless of the cache's type or the algorithm it uses to evict data, the required data is not always available in the cache. The possibility of accessing the cache and finding the required data is called the “cache hit rate.”
Introducing a cache into a storage system modifies the overall latency profile, as illustrated by the red line in the following chart:
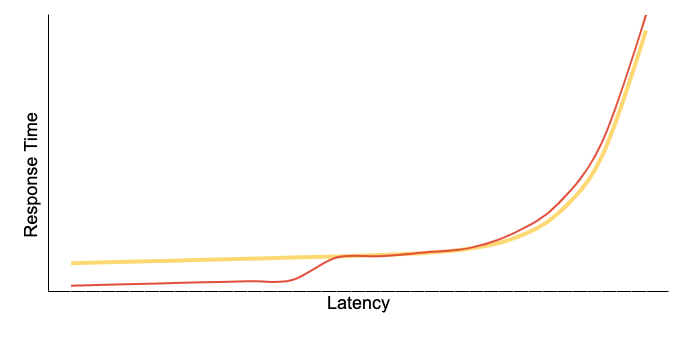
The red line can be segmented into three distinct regions:
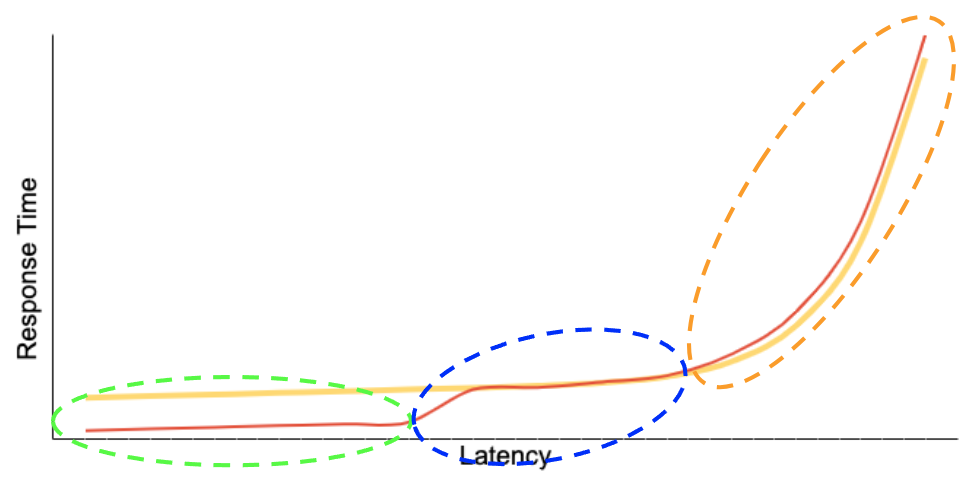
Green: This region represents requests that are successfully fulfilled by the cache, with the cache hit rate determining the size of this area.
Blue: For requests not found in the cache, the system reverts to its standard operation, yielding response times similar to those experienced prior to cache implementation.
Orange: Introducing a caching layer could potentially increase the likelihood of rare adverse events due to having more components, potentially elevating latencies at higher percentiles.
Ok, we’re in the home stretch.
What to expect from a cache
Consider a scenario where an application underperforms due to its database's inability to meet the required speed. Let's see what might happen if we introduce a caching layer or enhance the database's built-in cache by increasing its memory allocation.
In a complex application, handling a high-level request often involves multiple services and components, some of which need to query the database. If the cache hit rate is P, and there are n simultaneous database access requests, then the likelihood that all n requests are served directly from the cache is P^n.
For instance, if the cache hit probability is 50% and there are five parallel requests (n=5), the chance of all these requests being cache hits is 0.5^5, which equals 0.031 or 3.1%. Since a request is fully processed only once all its component queries have been answered, this means that in 96.9% of cases, the request does not benefit from the cache's existence. This is because it still has to wait for the completion of at least one query that has to access the slow database.
In practice, the target is to improve service response time at percentiles like the P99. To enhance the P99 latency of a task with five operations by introducing a cache, the hit rate must be a whopping 99.8% (0.998^5 = 0.99)!

Unless portions of your data are NEVER accessed, reaching that dreamy 99.8% cache hit rate means you're basically moving the entire database into the cache. So, when your database vendor serenades you with the advice to have enough memory so "the working set fits in memory," they're subtly hinting you might as well clone your disk space in memory. Have that in mind the next time they casually drop that piece of wisdom.

What's next in this series
We've covered a lot, yet there's more to explore. In this article, we addressed a prevalent misconception regarding caching: The notion that placing a cache (be it internal, external, or integrated) in front of a database can enhance the application's performance. This belief is often misguided, as simply adding a cache does not improve response times at a level that benefits the business in a meaningful way.
But, don’t go and remove all your caches yet. Caches are “one” of the valuable tools that, when strategically used, can boost your application's performance. In forthcoming articles, I will:
Explore various scenarios where caching enhances system performance.
Evaluate more effective strategies for enhancing application performance.
Explain how a cacheless database, like Aerospike, not only outperforms databases that feature integrated caching layers but also rivals
Until then:




