Blog
Five observations from enterprises using vectors to build AI applications
Vectors are transforming the dynamic AI/ML landscape, ushering in a wave of new use cases while shattering long-standing barriers. But some challenges remain.
Blog
Vectors are transforming the dynamic AI/ML landscape, ushering in a wave of new use cases while shattering long-standing barriers. But some challenges remain.
A vector is how machine learning models represent language, images, video, and audio as raw data. Effectively, these large arrays leverage linear algebra to piece together language models, image recognition systems, and generative AI application patterns. Thus, they’ve captured the imagination of technologists interested in developing AI applications.
New generative system concepts, such as “memory” and “context windows,” often refer to specific applications using a vector database to augment language model capabilities. Undoubtedly, the next generation of database technologies must handle large volumes of vector data, but what can make this scalable, cost-effective, and ready for production?
These are the questions we set out to answer when we put together a new vector R&D project – Proximus. We have spoken with dozens of AI builders, enterprise machine learning (ML) teams, and site reliability engineers (SREs) focused on database operations to understand the needs for a vector database. We wanted to share some insights from these conversations.
An exciting reality of the generative AI space is that it is easy to build compelling demoware. In just a few days, using openly available models and data sets, we built an image search application that has some of the magic of Google image search. On top of that, there are an ever-growing number of example retrieval augmented generation (RAG) applications, semantic search, recommendation systems, and lots of other common application patterns freely available. These all depend on ML models and vectors.
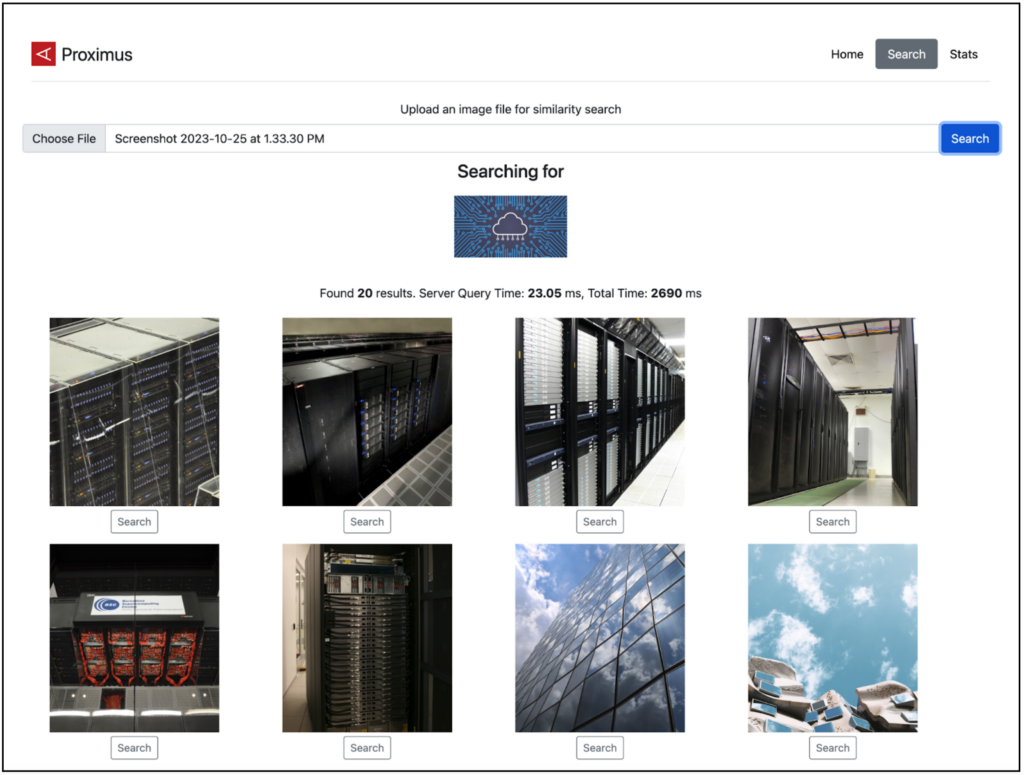
A look at the Proximus interface.
These are great demonstrations of uses for vectors, but the challenges and risks in bringing them to market at scale are prohibitive for most enterprises. Like the advent of self-driving cars, the first enterprise implementations are more likely to look like adaptive cruise control systems than autopilot. This is also not to say we are not seeing any teams deploy their models to production; it’s just that this is still an early minority.
A core reason teams are still largely limited to demo deployments is that the cost can be significant. Small data sets can often generate huge expenses from cloud and AI-related service providers. We have spoken with teams that have gone through millions of dollars of cloud credits for relatively small data sets. Additionally, we have spoken to many teams using vector search offerings for convenience but can’t afford to scale them up for larger deployments. Extensions to existing, well-known databases like Postgres, Redis, or Elastic often help with costs but have huge performance and quality tradeoffs.
All-in costs are usually in the hundreds or even thousands of dollars per million vector embeddings (i.e., 10k vectors per dollar), depending on how the system is built. This is suitable for some scenarios, but if you have a use case on the order of billions of vectors, you’re talking hundreds of thousands to millions of dollars to operate.
Not surprisingly, these high costs come alongside extremely throughput-limited systems. The popular offerings can only handle hundreds of queries per second (QPS). Additionally, on offerings like Pinecone, you’ll need to scale out specifically for ingestion and top out at just 10k QPS across your entire dataset. In essence, even with a production-ready model, you may be unable to deploy it at scale.
To put that into a real-world perspective, we spoke with one well-known e-commerce brand that had developed a highly effective fraud detection system. The problem is they could only execute this on less than 1% of user sessions. Other teams we spoke to were launching projects internally to deal with these throughput constraints.
These limitations on cost, throughput, and production mean that deployment of ML models requires more than just vector search and model execution. ML teams successfully getting their models into production tend to think about the application holistically rather than focusing solely on the model aspects of the offering.
Using high-performance feature stores, filtering techniques, and UX considerations are some of the variables separating teams making it into production from those that don’t.
The key drivers of AI adoption are the ML models alongside a vector database and new application design patterns. There’s been impressive innovation in each of these, but what has changed the world in the past 18 months is the availability of open models and sample applications. While ChatGPT deserves all the attention it gets, the proliferation and development speed of open source models is equally jaw-dropping. As of writing this, Hugging Face now has over 400,000 models with mostly open licenses, which means you can plug in off-the-shelf capabilities for text generation, image recognition, or even robotics into your applications.
Strong coding skills and fancy GPUs are not prerequisites for trying out these new technologies. You can download and install models through a GUI with LLM Studio or even index your own photos for text searches using the CLIP model with the LLM CLI. When playing with these tools, it becomes pretty clear that being able to build with these available models is going to be an obvious route for many enterprise use cases.
The AI development of the past year has been breathtaking, opening up countless new opportunities and unlocking many existing barriers. Vectors at scale can unlock these use cases and create new value for businesses, users, and society. Compute is changing fast, too, with greater availability and demand for high-powered GPUs. The database may seem to have a more mundane role to play here and may even be trivial for a small demo or proof of concept project. But for enterprises bringing AI applications to production at scale, some of the familiar challenges arise, namely, – scale, throughput, and cost efficiency, to name a few.
These are familiar problems; ultimately, innovation will bring the cost of infrastructure down, and new application patterns will become commonplace.
For a deeper understanding and more insights, explore these additional resources.
See more
Blog

Blog

Blog

Blog