
Parts one and two of this blog series by Vova Kyrychenko, CTO & Co-founder of Xenoss, reviewed the best ways to optimize your database infrastructure to be more cost-efficient and common database architecture mistakes.
In part 3, Vova discusses the design principles of good architecture, the kind you can scale with an optimal cost/benefit ratio.
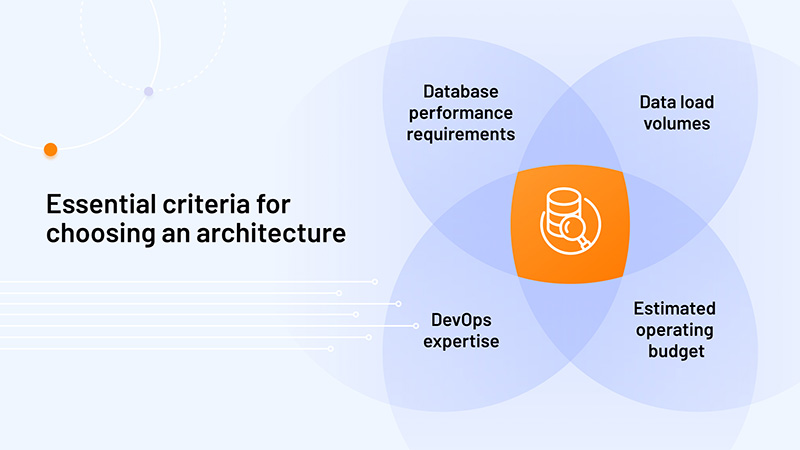
When choosing a tech stack, one should focus on the budget, DevOps expertise, data load, and performance requirements. You must upload big volumes of data, adjust indexes, adjust compression, and see how the system performs. You must extensively test and experiment with database architecture to find an optimal solution.
But more importantly, you need to choose the tech stack with flexible optimization options, allowing you to configure the system to your changing needs. For instance, we have built a lot of projects using Aerospike. Their in-memory database allows us to deliver efficient, low-cost infrastructure to our clients.

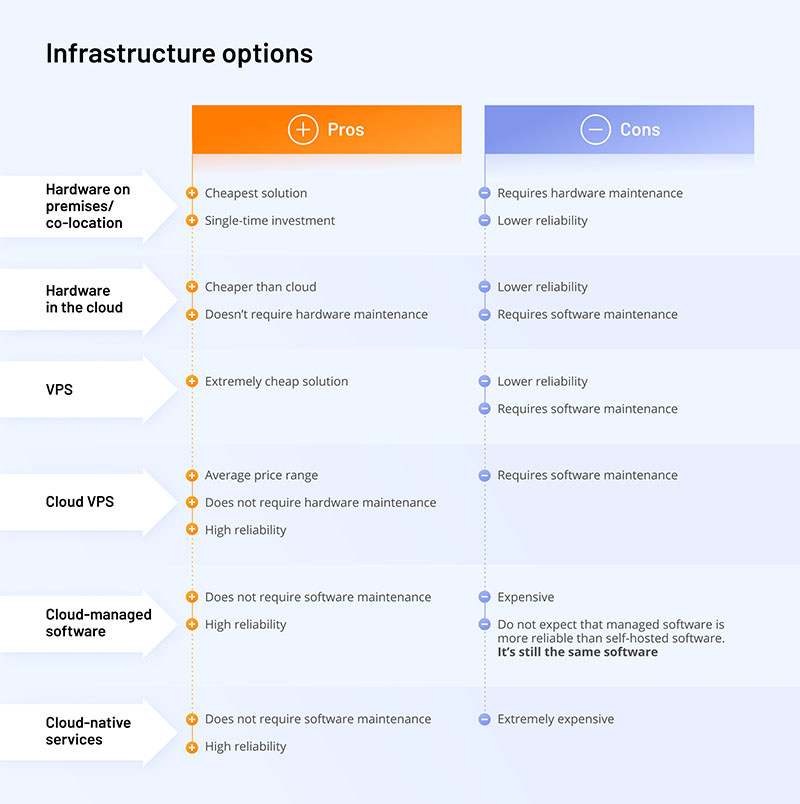
Infrastructure options
To design a high-performance solution, a tech-based business must strike a balance between the shared cloud infrastructure and in-house data capabilities. There are various options on the market with varying degrees of optimization flexibility. Let’s review the most common types of infrastructure services.
Aerospike Cloud
Build real-time apps in minutes
Hardware on-premise/co-location
This is the cheapest solution on the market. You buy your own hardware and only pay once. On-premise hardware is a single-time investment until you need to replace it. It can take years with the current quality of hardware, before you have to replace the server. It is a very cheap solution, but it demands holistic maintenance, and you will have to have someone to do it for you.
You will require engineers in your technology team in charge of hardware, data management, and operations. The reliability of on-premise services is heavily predicated on the experience of the in-house team, as opposed to clouds that provide a perfectly tailored solution with built-in maintenance mechanisms that ensure reliability.
Hardware on the cloud
This interesting niche emerged from the recognition that cloud services are costly. Typical vendors provide the ability to buy hardware from them and take care of maintaining it. If it gets broken, they will replace it. It is much cheaper than cloud-native or cloud managed services.
Hardware on the cloud doesn’t require maintenance but is hardly reliable because you lack the audit on the hardware level. Database management and operations are also entirely on your shoulders.
Virtual private server (VPS)
A virtual private server or VPS is a hosting service that provides dedicated resources on a shared server with multiple users. Virtual private services offer an additional layer of reliability with additional hardware and software checks.
Virtualized service is one of the most affordable solutions. There are a lot of providers of extremely cheap virtualized private servers on the market. With this option, you are left to your own devices with database management and software maintenance.
Cloud VPS
Google Cloud, Azure Cloud, or AWS. It’s in the average price range and doesn’t require hardware maintenance. Nevertheless, there are cases when hardware gets so degraded that you need to migrate to different cloud servers. Everyone working with clouds long enough has had a chance to get an email from the cloud provider explaining that their hardware has degraded and that they need to migrate to other options.
The reliability of such systems is much higher because the cloud uses many technologies and safeguards to provide more dependable services. With cloud VPS, you don’t have to deal with reliability issues, but you still need software maintenance because you are still in charge of starting your software in these instances.
Cloud-managed software
Cloud-managed software is in the hands of cloud juggernauts — Amazon, Google, Azure, and IBM (to a lesser extent). Most of them meshed database management software with cloud computing, cloud storage, and native integrations with various other analytics tools in their respective ecosystems.
Cloud-managed services are expensive, but on the upside, they don’t require software maintenance. Managed software provides high reliability yet is similar to the one you can get from the third-party vendor for a flat fee and customize on your own. Cloud-managed solutions provide you with the VPS and the software installation and setup.
This is the same software, but the cloud vendor applies additional security provisions, maintains the latest versions of tools, and makes sure they run smoothly. However, it’s still the same software. Basically, the cloud cannot bring you more reliability than the software itself.
Cloud-native service
Cloud-native services have one major advantage: They offer fully-managed services, and you can do everything in just a few clicks. Most database administration jobs are streamlined. You can also up/downscale your deployments on demand or automatically.
Cloud-native services, such as Google BigQuery, automatically provide replicated storage in multiple locations, which helps ensure low data processing latency.
The main downside is that these services are costly and lack flexibility for optimization and resource self-provisioning. Aside from implementing best practices, you can do little to accelerate BigQuery performance since it determines the number of resources (slots) it needs. Consequently, you must carefully monitor which data you ingest to avoid overspending.
How to engineer your system for scale
Cloud services are perfect for a “hands-off approach” — you set the operations on auto-pilot and hope for the best outcomes. However, these solutions can be a significant strain on your budget if you fail to provision cloud resources during scaling.
In contrast, to operate various self-serve options, you need to have DevOps and database experts. However, with the right design, self-serve solutions can yield faster data processing speeds, better database performance, and substantial cost savings compared to managed providers. To design scalable database architecture for the long haul, take into account the caveats from our practice.
Prioritize investing in engineering over hardware
Facing the dilemma of where to invest – buy more tech or get more developers? Pick the latter. The holy grail of the tech business is bringing scale without a substantial infrastructure cost. Infrastructure costs of emerging products comprise at most 5%, 10%, and significantly less than the team cost.
The product team can make a dangerous assumption that engineers are expensive and infrastructure is not and go for managed cloud services instead of leveraging in-house data architecture expertise. Yet cloud bills tend to grow exponentially with scaling.
Resources spent on buying the infrastructure from cloud providers could have been spent on growing the developer team, which brings intellectual property rights, increases business capitalization, and amplifies your business’s gross potential. When you spend this money on infrastructure, it’s just plain cost, nothing added to the value of your business.
Understand shared economy
The more data you process, the more computing power you’ll need to rent from the cloud provider. You’d have to pay for each addition without an option to proactively configure or optimize data workloads across the supplied infrastructure. That is why you must understand various types of cloud services on the market and the costs they entail.
For instance, in database management services like Amazon RDS, DynamoDB, or Google BigQuery, you can estimate how much it will cost you to execute a query.
Another way to go is a solution with flat billing, like Aerospike or ClickHouse. Their platforms are not natively integrated with the clouds, but your costs will stay the same regardless of the number of requests you’re making to the database.
To understand which solution works better for you, you should understand the nature of your business’s technology and its scale strategy.
Assess service billing for your business growth
If you’re designing data architecture for a relatively low-load project (for example, a data clean room), managed services can be helpful since they speed up data discovery, processing, and loading data at a low cost.
However, once your platform faces bigger data loads, managed services can grow into a huge expense. For example, Redshift AWS bills $0.44 per DPU-Hour for each Apache Spark or Spark Streaming job. Those cents can add up fast.
Besides that, you need to pay for cloud data storage, which is affordable and easy to provision. However, cloud elasticity is a double-edged sword: Your data warehousing costs can quickly spiral out of control without proper optimization.
Takeaways
Don’t blindly rely on clouds — you can manage databases more efficiently yourself. That might require additional developers onboard, but that also gives you growth potential. Having expensive infrastructure brings you only costs.
Hire consultants and engineers that have experience developing high-load solutions — this can become the ultimate investment that will help your profits grow much faster than your infrastructure bills.
This article was written by guest author Vova Kyrychenko, CTO & Co-founder of Xenoss, and is part 3 of a 3-part series. Read part 1 on Optimizing your database infrastructure costs, part 2 on Common mistakes designing a high-load database architecture and watch the full Architecting for Scale and Success webinar with Aerospike and Xenoss to hear more about their use case.
Keep reading

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX

May 12, 2026
Monitoring Aerospike Enterprise in Datadog: What you get and how it works