Implementing strong consistency in distributed database systems
The CAP theorem states that no distributed system can be designed for both consistency and availability – it’s one or the other. However, we have designed algorithms that significantly improve system availability during many common failure situations while supporting strong consistency.

It’s important to note that there can be several levels of consistency, from more strict to less strict. “Strong consistency” is the holy grail – the strictest level of consistency. Strong consistency guarantees that all writes to a single record will be applied in a specific order (sequentially), and writes will not be re-ordered or skipped. For single-record transactions, there are two strong consistency levels – “linearizable” and “sequential” (take a look at the pink rectangles on the right branch of Jepsen’s consistency models map). There are additional levels of strong consistency for multi-record transactions (the left branch on Jepsen’s model map). For this blog, we will focus only on single-record transactions in a distributed database system that supports storing multiple copies of each record (replication) within the system.
To briefly explain the difference, a single-record transaction is an atomic transaction that executes database operations (read, create, update, delete) on a single data record in a distributed database system. A multi-record transaction, by contrast, executes multiple operations that may affect more than a single data record.
In addition to linearizable and sequential consistency, we’ll also explain commonly used industry terms, such as “eventual consistency” and “strong eventual consistency.” To set the groundwork, let’s briefly explain the CAP theorem, which serves as the base for the consistency discussion.
Cap theorem
Coined in 1998 by Prof. Eric Brewer of the University of California, Berkeley, the CAP theorem states the following: “In any distributed database design, in the face of Partition Tolerance, you can choose to design for either Consistency (CP) or Availability (AP). You cannot have both.”
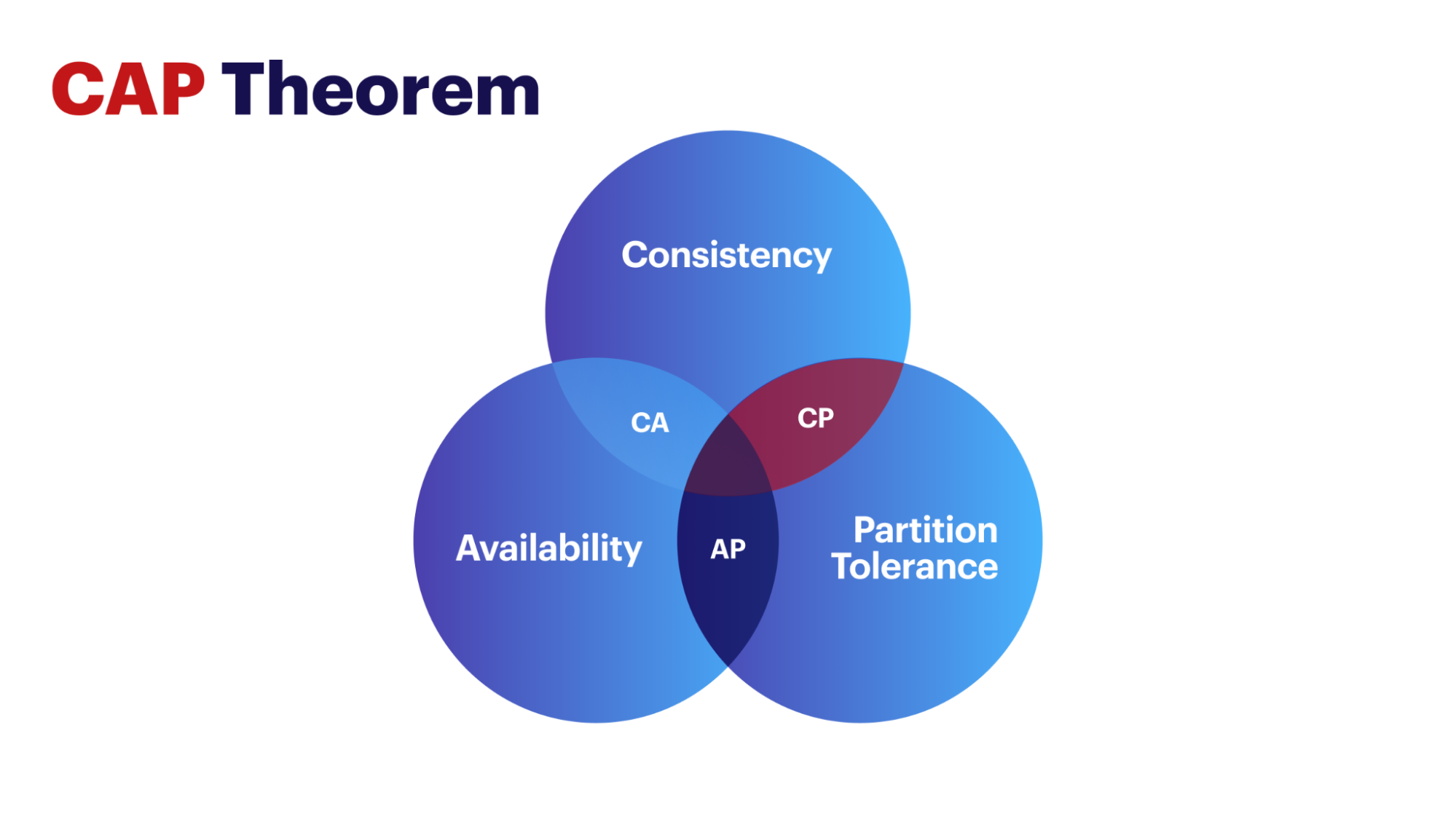
Partition tolerance
The premise: We have a distributed database system comprising multiple nodes, and there’s a failure in the system. The failure can be a network partitioning issue, a node crash issue (one or more nodes can be affected), and so on. Partition tolerance means the database management system (database cluster) must continue working and providing service, even during a network communication failure event.
Availability
The distributed system continues to provide service to the client/application, including writing new data and reading or updating existing data. If the client/application cannot access the database system, it’s deemed as being unavailable.
Consistency
Data must remain consistent across all nodes in the cluster at any given point in time. Once a write activity is done, all copies of a data item need to have the same value. An immediate subsequent read accessing any of these record copies (on potentially different nodes) should return the same result. This is a specific definition of strong consistency per the principles of the CAP theorem; we’ll describe it again later when we list various types of consistency.
Note that consistency and availability are impossible in a distributed system in the presence of network partitioning. It can only happen in a theoretical scenario where nodes never go down, and there’s never any communication issue – i.e., no partition tolerance is required. However, that’s a scenario that is virtually impossible since, in real life, communication issues will definitely occur, and nodes are guaranteed to go down (or get disconnected from the network) at some point in time or the other.
Additional relevant terminology
The following terminology will be used throughout this blog to define the various types of consistency:
Stale reads: Reading data that is not the most recently committed value (i.e., old/obsolete data).
Dirty reads: Reading data that is not yet committed and may be undone.
Lost writes: Losing data that was committed.
Consistency requires a synchronous system
A distributed database system that prioritizes strong consistency over availability (CP mode in CAP theorem) must support synchronous replication of data within the single cluster of nodes that form the distributed database system. Such a system will never violate the strong consistency rules described earlier, even in the presence of network partitions.
Synchronous replication means that when data is written to the primary, it is immediately copied to any replicas with a confirmation back to the primary before the write is committed.
With asynchronous replication, data is written and committed to the primary node and subsequently copied to replicas.
Write operations: All strong consistency models have to preserve writes, i.e., no writes can be lost to subsequent reads.
Read operations: follow a certain logic, which depends on the consistency model, which we shall discuss below.
Strong consistency models
There are two read models, or two different consistency levels, in single-record transactions for strong consistency (writes have only one strong consistency level). Aerospike supports both the linearizable model and the sequential read model, which is also called “session” consistency.
Linearizable consistency
Reads go to the node that contains the master copy of the partition that contains the record being read (i.e., the master for that partition). Then, the master checks with all the nodes that have replicas of the same partition to see that they have a consistent value for the specific record. If all of the replicas, including the master, agree, then the read is successful. Otherwise, it fails, and the client application gets an appropriate failure code and can then retry the read.
Thus, every read to a record is strictly ordered, i.e., “linearized,” with respect to every other read and write to the same record. Therefore, every read will see the most recently committed write to the record no matter which application wrote it.
Linearizable typically has the highest level of strong consistency. It is also the hardest to design and implement.
Sequential consistency
Sequential consistency involves reads arriving at the master, except the master doesn’t need to check with the replicas. It’s just a local read at the master. This involves fewer hops and, therefore, a faster read.
It’s important to note that whatever data a specific application writes to the database, the same application is guaranteed to read subsequently and forever. Note the guarantee to read the latest writes only applies to the specific application’s writes. It does not apply to writes and reads performed by other applications operating concurrently on the record (unlike linearizable reads). Note that stale reads can only happen when there are failure events like network partitioning, node up/down, etc.
Let’s explain sequential consistency with a visual example:
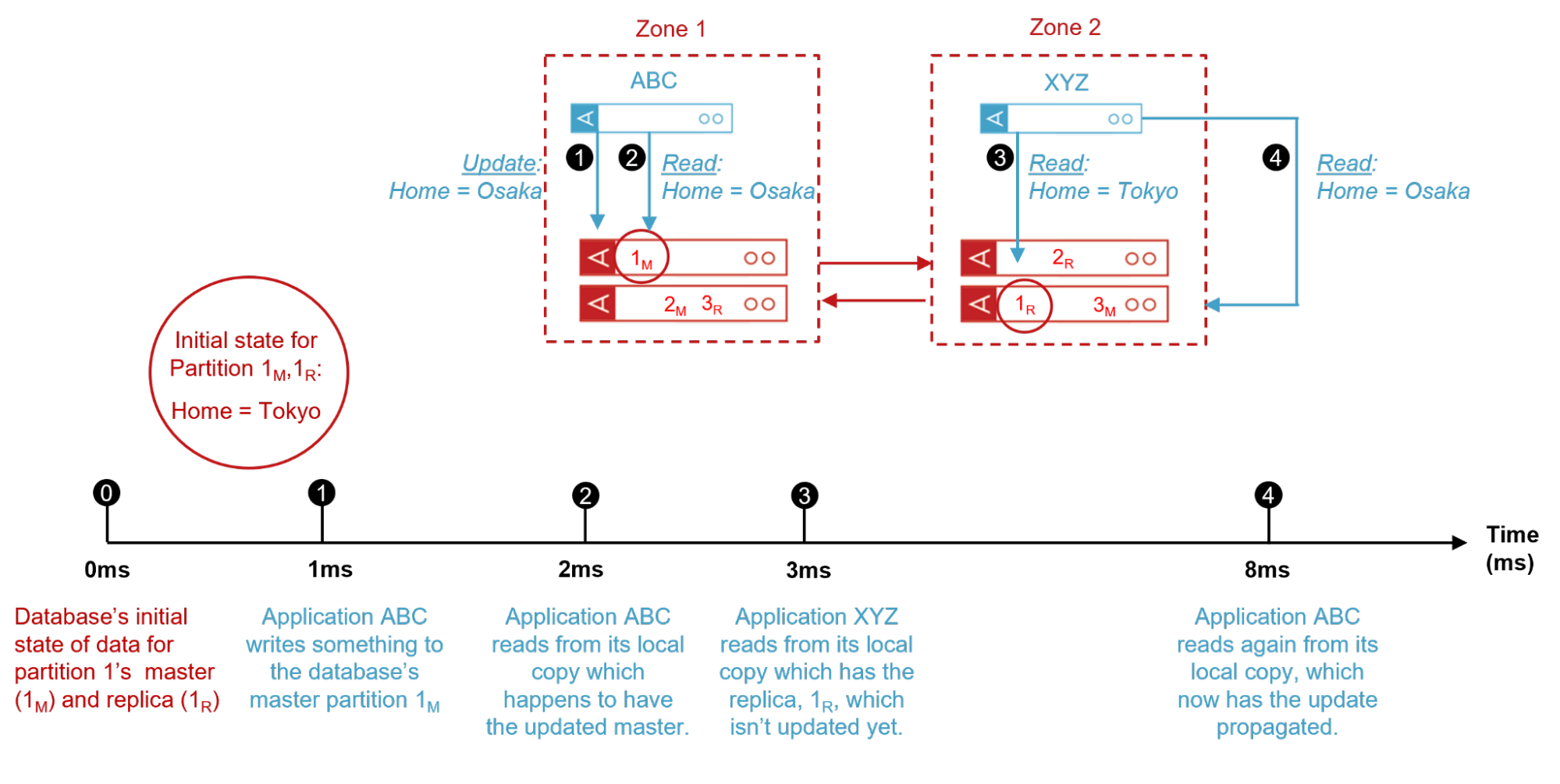
Figure 1: Sequential consistency example where sequential reads by different applications are not readily available.
Linearizable Consistency | Sequential Consistency | |
Pros | Linearizable reads guarantee that a read will always fetch the most updated version of the specific piece of data, and client applications will not see any stale reads. | Sequential reads across multiple applications that modify the same record simultaneously may return stale (committed) data for a brief period in some failure cases or when read from a local replica is enabled. |
Cons | Linearizable reads will be slower than sequential reads because the read must look at the state of all the copies of data in the cluster to enforce the strict ordering of reads to the record before returning a value to the client application. They must go to every replica and check that the versions are correct before returning a value to the client. The process requires extra hops to and from the various cluster nodes that contain replicas of the record. | Sequential reads are faster than linearizable reads because the master can read from its local copy of the record without checking the state of the replicas (hence fewer hops). In fact, these reads are as fast and efficient as AP reads during normal system operation (i.e., non-failure situations). |
Linearizable consistency and sequential consistency: A comparison
Linearizable and sequential consistency share a few variables in common. Here are instances where these two models overlap. Both models
Are immediately strongly consistent for writes as soon as the write is completed.
Cannot lose data, as no write is ever lost.
Cannot generate dirty reads (these are impossible in strong consistency).
Reads differ in each consistency model. For single-record transactions
Linearizable is the stricter model. Reads are slower and cannot return stale data.
Sequential is the more relaxed model. Reads are faster but may return stale data. For example, sequential reads can be as fast as AP reads during normal system operation (i.e., non-failure situations).
It’s important to note that choosing between linearizable and sequential reads can be done on a request-by-request basis. The client can request that the read be linearizable at API execution time. Subsequently, that same client can use a sequential read for reading a subsequent data item.
Eventual consistency and strong eventual consistency
Both models described in the previous section – linearizable and sequential – are examples of true strong consistency models. These are based on synchronous replication and are strongly consistent. However, two additional models, eventual consistency and strong eventual consistency, apply to systems that use asynchronous replication.
Eventual consistency
Eventual consistency dictates that operations are asynchronously applied to the various copies in a cluster. It is possible that multiple concurrent operations on the same data record can arrive out of order at various copies. Therefore, writes can be lost, and the only promise is that eventually, the data will converge, so long as no additional writes occur (which is why eventual consistency is also referred to as “convergence ”)
Because replication is asynchronous, not all copies of the data are updated after completing a write operation. There’s a period where some nodes may have old data, and a read operation will return stale data until the state of the update record converges to the same value everywhere. It’s worth noting that there is no bounded time guarantee as to when this convergence will occur.
Pros: Speed and availability.
Cons: Lost data, stale data.
Strong eventual consistency
In this model, a set of operations done to a record is applied in such a manner that every copy of that data item in the database will end up with the same result without any data loss.
In other words, strong eventual consistency guarantees that once all replicas of a data item have received an update or a sequence of updates, they will deterministically converge to the same value without any further intervention. Two replicas that have received the same set of updates will eventually end up at the same value, even if those updates arrived in different orders.
Pros: No lost data. No dirty reads.
Cons: Stale reads can occur and may be in this state until, e.g., the network partition is healed. There will be differences between the various nodes/clusters connected until convergence.
Consistency models: A recap
To summarize, the stronger the level of consistency, the harder the database system must work to maintain that level of consistency. The payoff is you get no stale data – or less. Still, it’s OK to have stale data in certain strong consistency models.Dirty reads or lost data (i.e., lost writes) are never permissible with strong consistency.
Here’s a high-level breakdown of the consistency models we have covered:
Linearizable consistency: Reads are slower, but you always get the latest data. No data can ever be stale. This is the highest level of strong consistency.
Sequential consistency: Reads are faster, but you may occasionally get stale data (this is still strong consistency). This means you may get some older data compared to where you are in the transaction process. Still, the data is
correct, as it was committed to the database.
Strong eventual consistency: Reads will be even faster, but even more stale reads are possible. This model is not strongly consistent because data updates are not synchronous between the system’s various nodes.
Eventual consistency: Not only do you get stale data, but you’re also likely to lose writes.
Strong consistency with Aerospike
NoSQL databases were created to provide unmatched speed of access and the ability to handle huge amounts of data. For that reason, NoSQL databases have been ideal for real-time web applications, e-commerce, online gaming, online advertising, and many additional categories of applications. At Aerospike, we have developed a strong consistency scheme that provides these unique differentiators.
1. Strong consistency with high performance
When releasing Aerospike 4.0 in early 2018, in a blog post that included release notes and technical info, Aerospike’s then-CTO wrote, “Our internal testing has shown high performance to be achievable, even with strong consistency. Our preliminary results prove high performance with session consistency (aka sequential consistency) – no real performance loss compared to Aerospike in AP mode, and very high performance with full linearizability.” The blog also shows the following performance data:

2: Aerospike is more available in CP mode than other strong consistency systems
From the get-go, Aerospike engineers focused on providing both strong consistency and availability during commonly occurring failure situations. One of them, for example, is a rolling upgrade of the database system, where you take nodes down one at a time, upgrade them, and bring them back into the cluster. Another is a split-brain scenario with exactly two sub-clusters forming during a network failure. A third case is during the failure of an entire rack in a multi-rack deployment of a single database cluster stretched across multiple data centers. In all of these failure scenarios, the system can continue with 100% data availability, preserving consistency and availability without requiring operator intervention. Additionally, the system restores itself to its steady state once the failure situation is cured, again without operator intervention.
Thus, Aerospike preserves strong consistency and 100% data availability with minimal impact on performance during many common failure scenarios that typically can make other systems unavailable. However, if there are many concurrent failures affecting nodes in a cluster, the CAP theorem kicks in, and the system will restrict data availability to preserve consistency. For over five years now, unique strong consistency algorithms have helped Aerospike provide unparalleled availability for many mission-critical systems deployed with strong consistency while providing industry-leading performance and uptime.
Strong consistency with fewer compromises
Want to learn more? We invite you to read additional content about our strong consistency capabilities. We’d also love to hear about your needs and see how we can help address them. Reach out!
Keep reading

Jul 21, 2026
KV cache tiering: Why GPU memory alone won't scale your LLM app

Jun 17, 2026
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS

May 28, 2026
Determining the best machine learning and AI databases

May 18, 2026
The three price tags: How Redis unpredictability costs you infrastructure, engineering time, and UX