Demystifying native vs. multi-model graph database myths
Learn about the strengths of each approach and how they cater to different data needs.

In the dynamic world of database management, graph databases have emerged as a powerful tool for handling complex, interconnected data for a variety of use cases. They are especially well-suited for use cases involving identity resolution, recommendation engines, fraud detection, and more.
When choosing a graph database, the conversation is frequently clouded by the native vs. non-native (or multi-model) dichotomy, a distinction heavily influenced by marketing narratives. These narratives often suggest a superiority of native graph databases, potentially diverting attention from the fundamental criteria crucial to database selection: performance, total cost of ownership (TCO), reliability, and cost predictability. It’s essential to move beyond this marketing-driven perception and concentrate on the substantive metrics that determine the true value of a graph database solution.
Native graph database structure and advantages
The allure of native graph databases lies in the claim of inherent superiority in handling graph-structured data, primarily due to features like index-free adjacency. This characteristic supposedly allows for faster traversals and more efficient data processing, painting a picture of native graph databases as the optimal choice for any graph-related task. However, this narrative simplifies a complex decision-making process that should instead focus on measurable outcomes and real-world application needs.
The “native” term often refers to two aspects:
Storage layout
Query processing efficiency
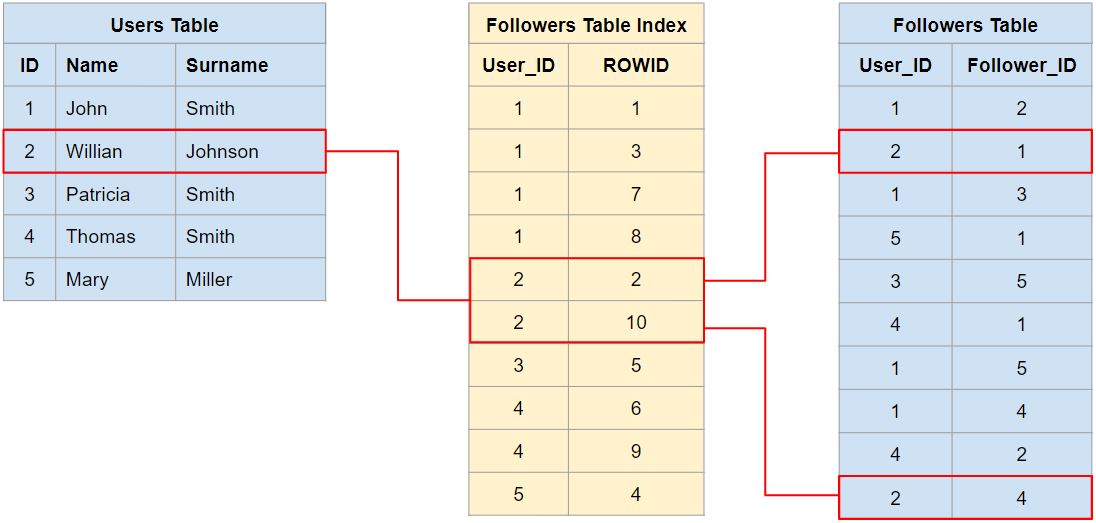
The marketed superiority of native graph databases is attributed to their specialized storage, which is optimized to store and manage graph data. Yet, this argument often misses a crucial point – the underlying storage or memory hardware is inherently linear and structured in rows and columns. The essence, therefore, is how graph data is modeled within the storage engine to achieve efficient query processing. This strategic modeling and optimization bridges the gap between graph relationships and linear storage, highlighting the importance of data handling techniques over the native vs. non-native debate for real-world performance gains.
The other key function of native graph databases is the ability to traverse the graph very efficiently using index-free adjacency – a fancy term for linking data points directly through memory pointers. While this enables near-instantaneous access to connected nodes and fast traversals, this approach hinges on the machine’s memory capacity, presenting scalability challenges for handling really large datasets.
Source: thomasvilhena.com
So, while native graph databases are great for some use cases, they come with some significant drawbacks.
Limited scalability: Storing direct pointers to adjacent nodes increases memory consumption, especially in densely connected large graphs. Each edge requires a pointer, and in a highly interconnected graph, this can lead to substantial memory overhead, thereby limiting the solution’s scalability.
Update overhead: In dynamic graphs where edges are frequently added or removed, maintaining index-free adjacency can introduce overhead. Each modification requires updating direct pointers, which can be more complex and time-consuming than updating indexes in non-native graph databases. The fact that the graph is in memory, architecturally, reduces native graph databases to a single write master architecture, severely limiting write scalability.
Data locality: While index-free adjacency improves traversal speed by avoiding index lookups, it does not guarantee that the data for adjacent nodes is located close together in memory. Native graph database vendors typically require domain-based partitioning schemes for the user data to take advantage of the data locality. This is usually very cumbersome to manage operationally and restricts the size of graphs that can be supported with these databases.
Multi-model graph database structure and advantages
On the flip side, multi-model databases are known for their versatility and the operational benefits of dealing with a single product, vendor, and management interface. These databases support multiple data models within a single platform, accommodating a wide range of data models, including graph, document, key-value, vector, and more.
The integration of graph capabilities within a versatile, multi-model data platform addresses the evolving demands of modern applications, including those requiring real-time insights, massive scalability, and efficient data management across diverse data types.
Multi-model databases are typically optimized for scalability and performance. The key is to have a graph-native interface for the database for ease of programming while reaping the benefits of the scalable architecture.
The common assumption is that native graph databases inherently provide superior performance. While this can be true for certain query patterns, multi-model databases have made significant strides in improving their graph capabilities. Modern multi-model databases often incorporate efficient graph processing engines, making them competitive in terms of performance and affordability while providing the similar programming interfaces as native graph databases.
The crux of an effective graph database solution lies in delivering a user-friendly experience through a graph-native query language while harnessing the power of an efficient compute engine paired with a high-performance, distributed storage engine. This synergistic approach ensures data access at any scale, moving beyond the limitations of memory-based processing to provide a unified, scalable graph database solution. Ultimately, the value of a database hinges on its simplicity for developers, its performance, and its affordability. If a multi-model database can meet these criteria, offering ease of use, high performance, and cost-effectiveness, it stands out as a superior choice for your needs.
Use case matters
Of course, each vendor is biased towards their own approach. Native graph database vendors such as Neo4j and TigerGraph extol the benefits of a native approach. Multi-model vendors such as Aerospike, ArangoDB, and OrientDB tout the benefits of their approach.
But the answer to the question of which approach is best for you is, as usual, “It depends.” Both work, but with the diversity of graph use cases constantly expanding, the real myth is that it is one-size-fits-all. The choice depends on your specific use case and requirements.
When to choose a native graph database
Some clear reasons why you would choose a native graph database include:
Small and stable datasets: If your primary focus is on relationship-intensive queries on a fixed-sized dataset that does not materially grow over time, a native graph database may be the right choice. It excels in traversing complex relationships with minimal latency.
New to graph databases: If you’re new to the world of graph databases, native graph database vendors typically have support for many auxiliary tools to help with data modeling, data loading, etc. This is incredibly helpful for developers new to graph databases.
Graph-exclusive data: If your organization’s dataset consists entirely of graph data and you need maximum performance, a native graph database may provide the edge.
Incumbent graph database: If you already have native graph databases like Neo4j or TigerGraph successfully installed and operating in other areas of the business, you may wish to leverage existing skill sets and organizational knowledge.
When to choose a multi-model graph database
When considering a multi-model database that supports graph functionality, there are clear advantages to guide your choice:
Versatile data management: Opt for a multi-model database when your project involves handling diverse data types like documents, key-value pairs, and graph data. Its capability to streamline and adapt to changing data requirements offers unmatched flexibility.
Enhanced scalability: A multi-model approach is key for projects requiring the efficient horizontal scaling of varied data, ensuring robust performance even as your data landscape grows.
Superior support for operational workloads: Multi-model databases are designed to handle the high demands of operational workloads, providing the necessary real-time transactional capabilities for applications with thousands or even millions of concurrent users, far surpassing traditional graph databases focused on static data sets.
Cost-effectiveness: The consolidation of data management functions within a multi-model database can significantly reduce the total cost of ownership. This approach minimizes the need for multiple specialized systems, streamlining your IT operations and lowering both upfront and maintenance costs.
The balancing act
In practice, it’s essential to strike a balance between performance and versatility.
In deciding between using native vs. multi-model graph databases, consider your project’s unique demands and your operational priorities. Assess your scalability needs, data diversity, and the nature of your queries. In many cases, you may find that a well-chosen multi-model database can not only match but also exceed the performance of native solutions while providing the adaptability your organization needs in today’s fast-paced data landscape. So, while native graph databases can deliver outstanding results for specific use cases, multi-model databases offer the flexibility to handle a broader spectrum of data requirements.
Selecting between native and multi-model graph databases goes beyond chasing trends; it’s about thoughtfully picking the solution that serves your current project and anticipates its evolution, ensuring you’re not merely prepared but confidently ahead of the game.