Blog

While working with databases or data replication solutions, you must have come across the term Change Data Capture, popularly abbreviated as CDC. It is a data pattern that informs external systems when records are inserted, modified, or deleted in a database. It is extensively used for building event stream processing systems (ESP).
What is Change Notification?
Change Notification (CN) in the Aerospike system is CDC-like, but differs in the way changes are reported. Unlike CDC, change notification may include several changes compacted into a single notification. It uses Aerospike’s Cross-Datacenter Replication (XDR) to publish changes as they occur. Each message that the system sends contains either an updated/inserted record or a record deletion notification, as well as useful metadata. See Aerospike metadata for more information. Figure 1 shows how the data written to Aerospike is streamed as change notification to downstream consumers. Each update/insert/touch message contains the full database record including all, or a subset, of the record’s bins.
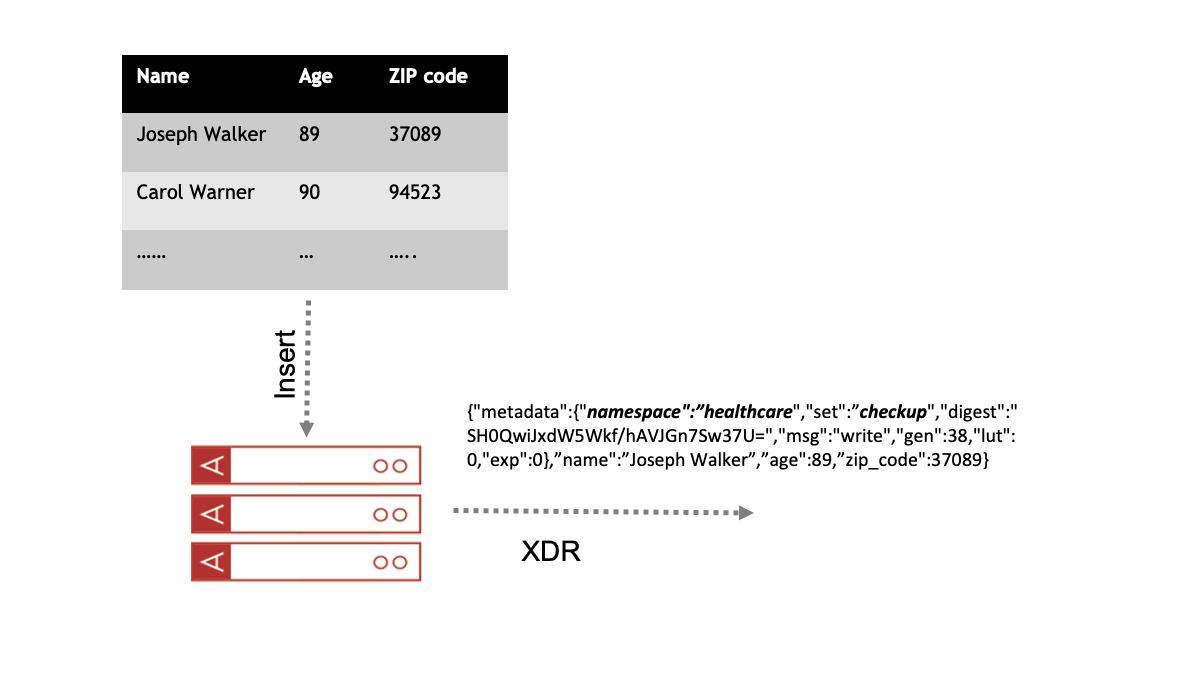
Figure 1 — Aerospike INSERT triggers Change Notification.
Aerospike Connect for Event Stream Processing (ESP)
Aerospike customers have been using change notification to power their event driven architectures. It has enabled use cases such as:
Aerospike as the edge database for high velocity ingestion, used to develop innovative AI systems such as a COVID-19 knowledge discovery system
Asynchronous data replication between Aerospike clusters for fault tolerance
for real-time ad campaigns
These systems are largely based on event streaming data platforms such as Kafka, Pulsar, or JMS, either in the Cloud or on-prem, and have been successful in meeting their business objectives. However, based on our conversations with customers, we realized that they cannot be treated as a one size fits all architecture pattern. There are many use cases that do not warrant the challenges associated with operationalizing Kafka or Pulsar production clusters.
One of the use cases that was brought to our attention used the serverless event processing architecture pattern. In this pattern, CN events are streamed to a Lambda function in AWS or Google Cloud Functions for further processing. As you are aware, AWS Lambda is integrated with the majority of the services of the AWS big data ecosystem, such as S3, SQS, KMS, Sagemaker, Kinesis Data Analytics, etc. Likewise for the integration of Google Cloud Functions with Google Cloud Platform. This presents an opportunity to our customers to integrate Aerospike Database with the broader cloud ecosystem, in order to build efficient cloud native data pipelines. That was an “Aha!” moment for our team and summarizes the story of the genesis of Aerospike Connect for ESP.
Connect for ESP converts change notifications over XDR into HTTP/1 or HTTP/2 requests, and streams them to downstream consumers. This enables several use cases, quite notably serverless event processing, as depicted in Figure 2. In this example, Connect for ESP converts the change notification events from the XDR protocol to HTTP POST requests. The change notification payload can configurably be serialized into a text format, such as JSON, or a binary format, such as Avro or MessagePack, for efficient data exchange. The HTTP request is forwarded to an API Gateway (or an Application load balancer), which triggers the Lambda function. The Lambda function subsequently writes the change notification payload to AWS SQS. The data in this pipeline flows in a highly scalable manner. Note that the destination does not necessarily have to be SQS, but could be any other AWS service that is integrated with Lambda. Optionally, you can persist state or the raw CN payload for future use in the Aerospike database via the Aerospike REST Gateway.
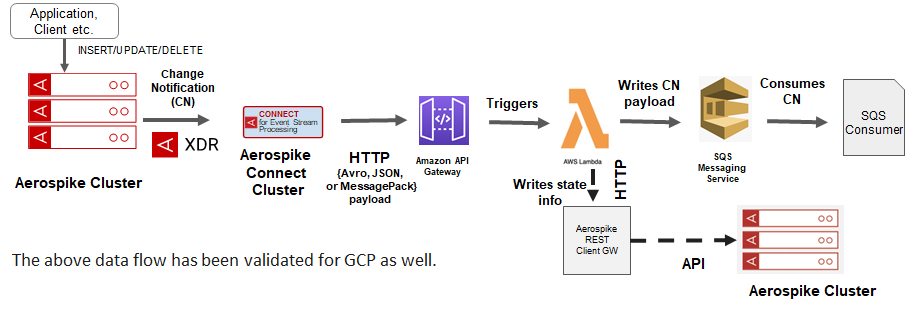
Figure 2 — Serverless Processing data pipeline
What it isn’t
Connect for ESP is neither Kafka nor Pulsar replacement, but for certain use cases such as serverless event processing, etc., it can obviate the need for Kafka or Puslar in your streaming pipeline. However, you must realize that there are a few tradeoffs that need to be made based on your use case. Unlike Kafka or Pulsar, there is no message retention, hence if a consumer is offline then it is not possible to resume consumption after the consumer comes back up online. Connect for ESP has no notion of topics or partitions, hence the convenience and flexibility associated with them is not available. Further, there is no support for schema registry, hence schema and its subsequent changes need to be communicated out of band.
Why you should care
Connect for ESP converts Change Notification over XDR into HTTP/1 or HTTP/2 requests, which potentially opens up connections to several HTTP-based systems such as ElasticSearch, AWS Lambda, Splunk, etc.
Serializes the change notification payload into a text format such as JSON, or a binary format, such as Avro or MessagePack, for efficient data exchange.
Can be used to trigger AWS Lambda via API Gateway or Application Load Balancer, or Google Functions, to process change notifications and make it available to the broader big data ecosystem in AWS or GCP.
Ships the LUT (last-update-time) of the record to enable downstream applications to build their own custom logic for ordering messages
Extends XDR’s at-least-once delivery guarantee to ensure zero message loss.
Can be used in conjunction with XDR filter expressions to filter out records before transmission. For example, ensure that only records with a compliance bin set to true end as searchable data in Elasticsearch.
Offers flexible deployment options either in the cloud or on-prem.
What you can do with it: top use cases
The basic idea is to connect the Aerospike database with X, potentially any system that can accept Aerospike Change Notification as an HTTP POST request. Here are a few potential use cases:
Export stripped down Aerospike Change Notification messages to Elasticsearch using its
Document REST API. In this architectural pattern, Aerospike database is used as a source of truth and Elasticsearch provides fast search capability, while maintaining a one-to-one relationship with the full objects stored in the Aerospike Database. This pattern could potentially be extended to make Aerospike data available for analysis in Splunk using the HTTP Event Collector in Splunk.
Back up Aerospike data to S3 (via AWS Lambda) or Google Cloud Storage (via Google Cloud Functions) for archival purposes.
Stream Aerospike data to AWS SageMaker (via AWS Lambda) or Google AI (via Google Cloud Functions) help you build cloud native AI/ML pipelines with the best of breed AI/ML services.
Encrypt Aerospike data for compliance using AWS KMS via Lambda, before ingesting it into your data lake.
Develop a web application in the language of your choice to ingest and process Aerospike Change Notification. Additionally, your applications could also persist state, results, or raw data into the Aerospike database using the Aerospike REST Gateway.
Autoscale Aerospike streaming connectors for Kafka, JMS, or Pulsar to enable you to build a cloud native streaming pipeline.
What’s next
We are very pleased to announce the general availability of Aerospike Connect for ESP for Change Notification. If you have an interesting use case in mind that Connect for ESP can enable, then wait no more! Please download Connect for Event Stream Processing, full-featured single-node Aerospike Database Enterprise Edition, and refer to our documentation for a seamless trial experience.
Additional resources
For a deeper understanding and more insights, explore these additional resources.
See more
Blog
KV cache tiering: Why GPU memory alone won't scale your LLM app
Read more
Blog
Fail fast, stay resilient: How to stop hidden gray failures in Aerospike on AWS EBS
Read more
Blog
Determining the best machine learning and AI databases
Read more
Blog