The challenge of real-time AI: How to drive down latency and cost
Learn about reducing latency, managing costs, and achieving real-time access, as discussed by Dr. Sharon Zhou, co-founder of Lamini, at the Real-Time Data Summit.

The value of artificial intelligence (AI) is significantly enhanced when it can operate in real time, enabling faster, more impactful decisions and actions. But it’s tough for large language models (LLMs) to be real time because of the computational load they demand and the cost involved. The good news is that latency, cost, and real-time access are interrelated, and finding ways to reduce latency also reduces costs and makes real-time access easier to achieve.
That’s according to Dr. Sharon Zhou, co-founder and CEO of Lamini, a Menlo Park, California company that builds an integrated LLM fine-tuning and inference engine for enterprises. Previously, she was on the computer science faculty at Stanford, leading a research group in generative AI (GenAI). It’s also where she received her PhD in GenAI with Dr. Andrew Ng. She spoke at the Real-Time Data Summit, a virtual event intended to advance the market and equip developers for the rapid growth of real-time data, leveraging its power for AI to address this latency, cost, and real-time access conundrum.
The key challenges of real time
Zhou cites three main areas that make it difficult to deliver AI-driven applications in real time:

Computation
It’s no secret to anyone that AI applications, particularly LLMs, require enormous computations. And we’re talking on the order of billions – just for a single question. That’s a big change from the machine learning (ML) of the past. "Even a million parameters was enormous and almost unthinkable, and that was just a few years ago," Zhou says.
Take a seemingly simple example. "Even when you ask [an LLM], 'Hi, what's up?' it's doing all the computation on the word 'Hi,' then ‘what's, and then 'up,'" Zhou says. "It's just very expensive to get through all of that."
But that’s just the start. Not only does the LLM need to interpret the input, it needs to create output, and that’s just as complex. "For example, 'Hi, what's up? I am good,’" Zhou explains. "It takes time for it to read, and it takes time for it to write. The bigger the model, the more computations there are. For a 100-billion parameter model, which the original GPT-3 and ChatGPT-like models were, that is very expensive."
Now imagine a real-world application where you're not just saying, "Hi, what's up," but giving the LLM additional data. "Let's say you want to detect whether their sign-in was fraudulent or not," Zhou says. "That's a lot of different user data you can pass through into the model. It needs to read all of that and then produce an answer for you."
Actual applications also require more complex output. "You want it to give an explanation for why it said what it said, whether it's yes or no," Zhou explains.
Cost
There are three main drivers that make real-time LLMs so expensive. "One is that just running the model once is expensive, certainly more expensive than pinging a website." It might cost just a fraction of a cent, but that adds up as you feed more data to the model.
Plus, computational loads are so heavy that completely new, reliable infrastructures need to be built to handle them, Zhou says. "It’s a really hard and very complex software engineering problem."
In addition, the system needs to be maintained. "The space moves so quickly," she says. "New models come out all the time, new types of architectures come out all the time. How do you keep up with that?"
Scaling
Scaling from a small proof of concept to a production app is the third challenge for real-time AI. "In a real application, you're probably not calling the model once; you're probably calling it many times. So, you're calling multiple models" – sometimes as many as 30, she says – "and that latency adds up. Each of those model calls takes on the order of seconds, whether that be 30 seconds or even one second. That adds up to, say, 30 seconds or 900 seconds. So it is very hard to scale these applications."
Three tips for developing lower latency apps
Zhou identifies areas in an AI application pipeline to target latency improvements: the AI model, steps before and after data reaches the model, and the app itself.
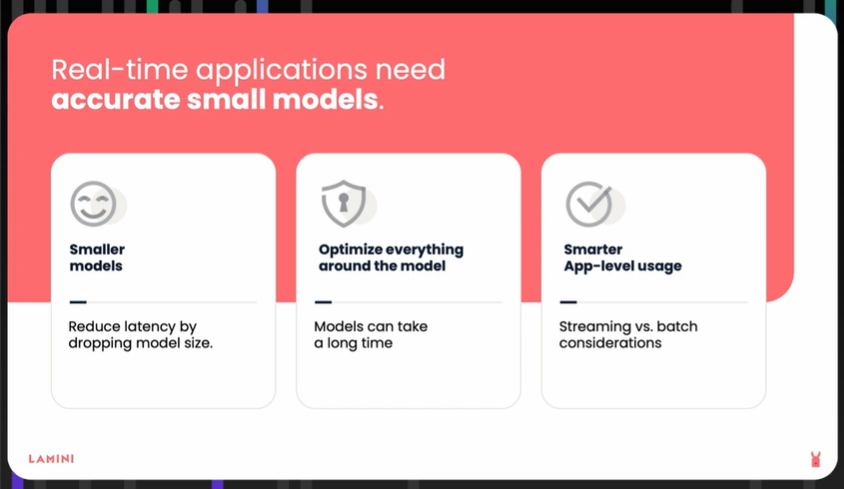
Start with a smaller model: “A smaller model means fewer computations,” she says. “Think about the smallest brain you can get away with, and you can start with that.” That reduces the response to the millisecond range instead of on the order of seconds, she explains.
Optimize your overall pipeline to reduce operations that could add to the latency: "Think through all the different pieces that cause the model to read a lot, maybe output a lot, write a lot," Zhou says.
Think at the application level: Do you really need all 30 of those models? "Think through how to use these models more intelligently," Zhou says. "Think about this upfront as you plan for this real-time application." Knowing just what latency your real-time application requires lets you "know where to start, what size model to start with, and how to think through where it needs to be in real time," she says.
Keep in mind, too, that what matters is not just the latency of a single token but the latency of the entire response to the user, Zhou says. "Often what we care about is not just latency, but also the scalability of that latency – batch latency, the throughput of the different requests coming in." What helps is looking for ways for the app to handle more than one request at a time. "That's really important for throughput so that you're not doing things serially," she says. "That lowers batch latency as you're able to take in multiple requests and batch them, even if they don't come in at the exact same time."
Efficient apps: When fast and cheap go hand-in-hand
While it is typically more expensive to deliver low latency, each of the prior three tips delivers a more efficient approach. It actually aligns latency and cost, making them even "directly proportional to each other," Zhou says. "The smaller the model, the cheaper it is to run, the fewer computations you need to have, and therefore, the faster it's able to respond back to you."
She uses foundation models, such as GPT-4 from OpenAI and Gemini 1.5 from Google, as examples. "Whenever they're improving the model, they are usually letting the latency go down while the cost goes down as well," Zhou says. "These companies are thinking very deeply about how to get away with a smaller model that people can still use so they can lower the cost for their user and respond much faster to each user, and therefore doubly be good to handle many more user requests."
Practical considerations for real-time AI success
Zhou offers several specific techniques that can significantly enhance the performance and efficiency of real-time AI applications. These include strategies for managing memory, optimizing model quality, and leveraging innovative model architectures.
Memory efficiency
One of the key challenges with large language models is their computational and memory demands. As Zhou explains, "Models are very computationally expensive and heavy. They also take up a lot of memory because they're just big to store inside your computer." To address this, Zhou introduces the concept of adapters, which allow developers to tune only a fraction of the model, making it much smaller and enabling quick and efficient model swaps. This approach can reduce the time required to switch between different models from months to milliseconds.
Mixture of experts
Zhou also discusses how developers can optimize larger models by activating only a subset of their parameters, a technique used in GPT-4 called the "mixture of experts." This method routes specific tasks to the most relevant part of the model, allowing for faster processing. "One of those experts is only a fraction, like an eighth, of the entire model," Zhou explains. "It’s much faster than going through all the different parameters, even ones that are basically irrelevant to the idea of responding in a casual chat."
Model quality and tuning
Improving model quality is another crucial factor. While smaller models may be faster, they can also be fine-tuned to enhance their accuracy for specific use cases. Zhou notes, "You can fine-tune it to improve its quality, lift its accuracy specifically on your use case...and actually be able to detect fraud if that's what you want it to do."
Lamini Memory Tuning:
Zhou concludes by sharing some of the work her company, Lamini, has done on what they call "Lamini Memory Tuning," a technique that transforms LLMs into highly factual systems by adjusting their objectives. This approach has led to remarkable improvements in accuracy, with real-world results lifting performance from 50% to 95% in just a few days. "It makes these LLMs very factual by changing their objective," Zhou explains, demonstrating how Lamini’s innovations pave the way for more efficient and reliable AI applications.
Aerospike: The database powering real-time AI applications
Aerospike has been at the forefront of powering AI applications with its database for years, and like Dr. Zhou, we recognize the immense potential and rapid adoption of LLMs and other similarity-driven AI use cases. As the demand for efficient, scalable AI solutions grows, Aerospike continues to enable businesses to achieve these goals with confidence.
Keep reading

Jul 24, 2024
AI in the blink of an eye: Real-time decisions redefined

May 8, 2024
Maximizing database management: How to achieve cost efficiency, high performance, and a low carbon footprint all at once

Apr 22, 2026
Aerospike vs. Cassandra: Databases don’t need to go down to break your application

Apr 16, 2026
Introducing Aerospike 8.1.2: Making nested data queries fast and easy to write