Vector search: Considerations for database efficiency
Choosing the right vector database requires exploring and weighing out numerous factors. Here are essential concepts to grasp before starting the selection process.

In some cases, gaining access to data in a database is pretty straightforward. "Verify this user’s login." "Detail the most recent transactions for a customer."
But what if your application requires searching for similar profiles or sessions based on user interactions or preferences? In these cases, you need more than just exact matches. This is where vector databases become useful. They are adept at analyzing structured and unstructured data, allowing for nuanced comparisons beyond simple equivalencies to capture similarities, facilitating more personalized user engagements.
What is a vector database?
A vector database provides for efficient storage, swift retrieval, and processing of structured and unstructured data — including text, images, audio, or video — at scale to make search easier and more efficient. Vector databases don’t store the actual data itself but rather numerical representations of the data, known as embeddings. The embedding process takes different types of content and converts them into vectors.
Vectors are the data structures behind information retrieval. A vector translates source information into a compact high-dimensional (HD) numerical value. The more dimensions you include in your embedding, the more detail you can maintain on each piece of information.
Vectors can embed information of all types, from text and numbers to images and music. Once the vectors are created and put into a database, they can be used for artificial intelligence (AI) applications, such as real-time recommendation systems and content summarization.
How do vector databases work?
The primary challenge in searching and comparing vectors in a database is finding the closest match, rather than an exact item, among millions of entries. This could involve potentially trillions of comparisons. Specialized vector databases address this by optimizing the search process, ensuring efficient and effective results."
A vector database offers a solution for storing and searching these vectors efficiently.
These are the steps the vector database takes:
Writes vectors to the storage layer
Calculates the similarity, or “distance,” between new vectors and vectors already in the vector space
Builds an index to optimize search
Once search requests come in, it identifies the most similar vectors, a concept known as “nearest neighbor”
On top of that, vector databases also perform many of the same functions as traditional databases. These include:
Make search more efficient through techniques such as pre-processing the data to make it easier to search, post-processing the data to organize it more efficiently, caching, query rewriting, concurrency control, and transaction management
Prepare for scale with optimization techniques such as data partitioning, replication, and pruning
Monitor, maintain, and protect the database through system analysis, index optimization, data backup, and security via encryption and authentication
Integrate the database with other systems
What is vector similarity search?
Searching within a vector space requires a vector similarity search, which means looking for the vectors within a database that are the most like the query vector, the new vector created by the search. The result is based on a defined similarity metric or distance measure.
How you define the similarity vector or distance measure will determine the success of your vector similarity search.
How does vector similarity search work?
As we described, the process of converting source data to a vector representation is called embedding. The universe of all the vectors makes up an overall “vector space,” in which similar concepts are mapped to one another. The relative distance between vectors represents the conceptual distance between them.
Let’s start with a simplified two-dimensional (2D) example to visualize the concept. In this example, one dimension represents gender, while the other represents age.
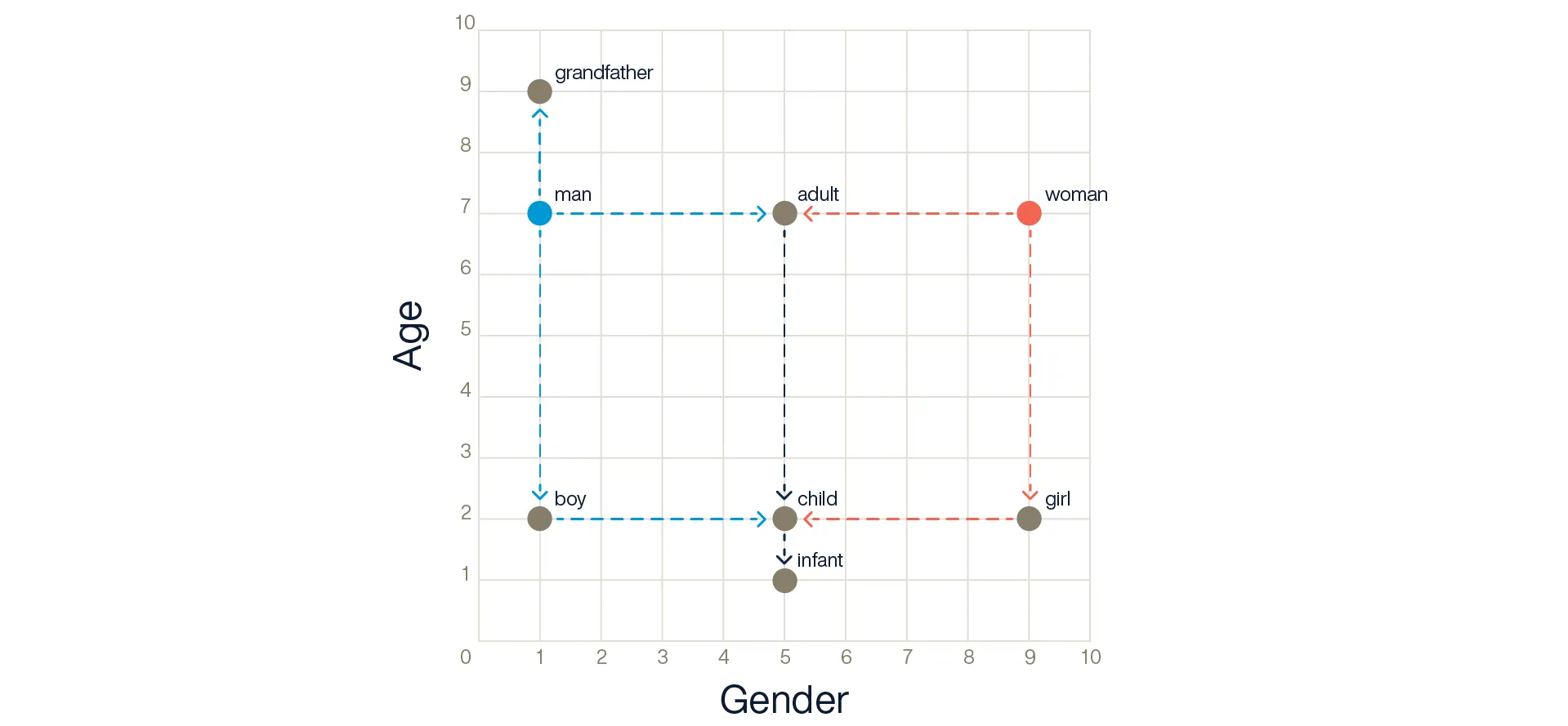
Figure 1: Representation of concepts embedded in a 2D vector space
In this vector space, “grandfather” is closer to “man” than “boy” is – two from “man” and seven from “boy” – and “man” and “woman” have the same distance to “child.” In contrast, “man” is eight from “woman,” but has the same relationship to age. So, a “boy” is the same distance from a “man” as a “girl” is from a “woman.”
Let’s say now you want to search for “infant” and retrieve the most relevant concept associated with it. So you would calculate the distance between “infant” and the other vectors in the space and then retrieve the “N” closest vectors.
The simplest way is to calculate the distance between “infant” and all the existing vectors. This is simple for a small example but would be costly and inefficient for more common, broader implementations.
A more efficient method, particularly when discussing examples with more than two dimensions, is to create and use an index. An index is a data structure, such as a tree or a graph, that encodes spatial information, which helps navigate to the right location much faster during retrieval. High-performance databases of all types depend on the efficiency of indexes.
In response to a query, the system embeds your search into a vector, and the most similar indexed vectors in your databases are retrieved for you, with some optional post-processing available, such as candidate refinement or re-ranking.
Why is there a tradeoff between accuracy and speed?
In the 2D example above, calculating the distance between vectors is simple. You get the most accurate results almost instantly. However, calculating similarity scores becomes complex when moving beyond 2D to HD vector representations. Not only do the examples quickly become difficult or impossible to visualize and imagine, but they require exponentially more computation and memory.
While performing an exact search that precisely returns the most similar vectors to the query is possible, these methods are costly. They also have longer processing times—literally hours. That’s not going to work in the real world.
An exact search is possible for small data sets and useful for a performance comparison with the approximate nearest neighbor implementations. But generally, organizations use an approximate search instead. An approximate search is much faster while being only a little less accurate.
There are several ways to do approximate searches, and each one has advantages and disadvantages in terms of accuracy and speed. Consequently, understanding and choosing the right vector search algorithm implementation is fundamental to choosing the best vector database solution for your project.
So how do you do that?
What are popular vector search algorithms?
Many of the most popular algorithms behind vector search are based on the general category of “nearest neighbor.” In fact, vector search is often referred to as a “nearest neighbor” search.
While “nearest neighbor” algorithms vary on whether they organize the data set into a tree, a hash, or a graph, they all work the same way: They find data points closest to a given query point based on the chosen distance metric. To improve optimization, some also use techniques such as quantization and clustering, which improve search efficiency by compacting vector representations.
KNN and ANN algorithms
As described previously, there are two basic types of searches: exact and approximate. Specifically, there are two basic types of “nearest neighbor” searches: K-nearest neighbors (KNN) for exact searches and approximate nearest neighbor (ANN) for approximate searches.
For an exact search, KNN returns the closest “k” number of vectors to the query vector by comparing all vectors in the database. But recall the problem with exact searches: they’re complex. For example, if you have a vector of dimension 300 and a database of 100 million vectors, you need 30 billion operations to retrieve your most similar “k” vectors.
It’s not surprising, then, that ANN algorithms are most commonly used for real-world applications. Some of the most popular ANN algorithms include:
Approximate Nearest Neighbors Oh Yeah (ANNOY) and Fast Library for Approximate Nearest Neighbor (FLANN) are tree-based and are best when you need to be as fast as possible – for example, an interactive real-time image similarity search for a photo-sharing platform
Hierarchical Navigable Small World (HNSW) and Navigable Small World (NSW) are graph-based and are best for applications that need to be as accurate as possible at scale, such as a recommendation system for a large worldwide e-commerce platform
Locality-Sensitive Hashing (LSH) and Semantic Hashing (SH) are hashing-based ANNs and are best for cost-effectiveness in scenarios where precision is less critical than resource efficiency – for example, content deduplication for an in-house document management system
Why does choosing the right vector search algorithm matter?
As you can see, choosing the most appropriate vector search algorithm is crucial for optimizing search performance and overall system efficiency. This ultimately contributes to improved user experience and better application outcomes.
First, your algorithm selection should align with your data requirements and then be tailored to provide optimal performance requirements. Beyond accuracy and latency, other metrics to consider when defining the performance tradeoff include throughput, cost, and scalability.
Vector databases in a nutshell
Selecting a vector database involves navigating through a number of solutions and considerations. Top among those considerations should be selecting the right vector search algorithm.
The idea behind vector search is relatively simple: High-dimensional data representations are embedded in a vector space where distance reflects conceptual similarity. When structuring your vectors within a tree, graph, or hashes, you more efficiently navigate the vector space at query time to strike a unique balance between accuracy and speed, aligning with data requirements and scalability needs.
That’s why opting for a vector database solution that allows you to customize implementation details, such as a vector search algorithm, can be a game-changer for a successful application.