CPU vs. GPU: What’s best for machine learning?
Explore how CPUs and GPUs function within machine learning workflows, the impact of GPU shortages, and optimizing with ultra-low-latency databases for enhanced performance.

The world of artificial intelligence has long debated the merits of CPU vs. GPU hardware, balancing the CPU’s general-purpose computing flexibility against the GPU’s specialized parallel processing capability for large-scale tasks.
The global GPU shortage, initially triggered by the COVID-19 pandemic, has created significant challenges for businesses and individuals relying on high-performance computing. With disrupted supply chains, the growing demand for devices, and the surge in cryptocurrency mining, the availability of graphics processing units (GPUs) became scarce. Adding to the strain is the rise of generative AI (GenAI) and large language models (LLMs), which require immense computing power.
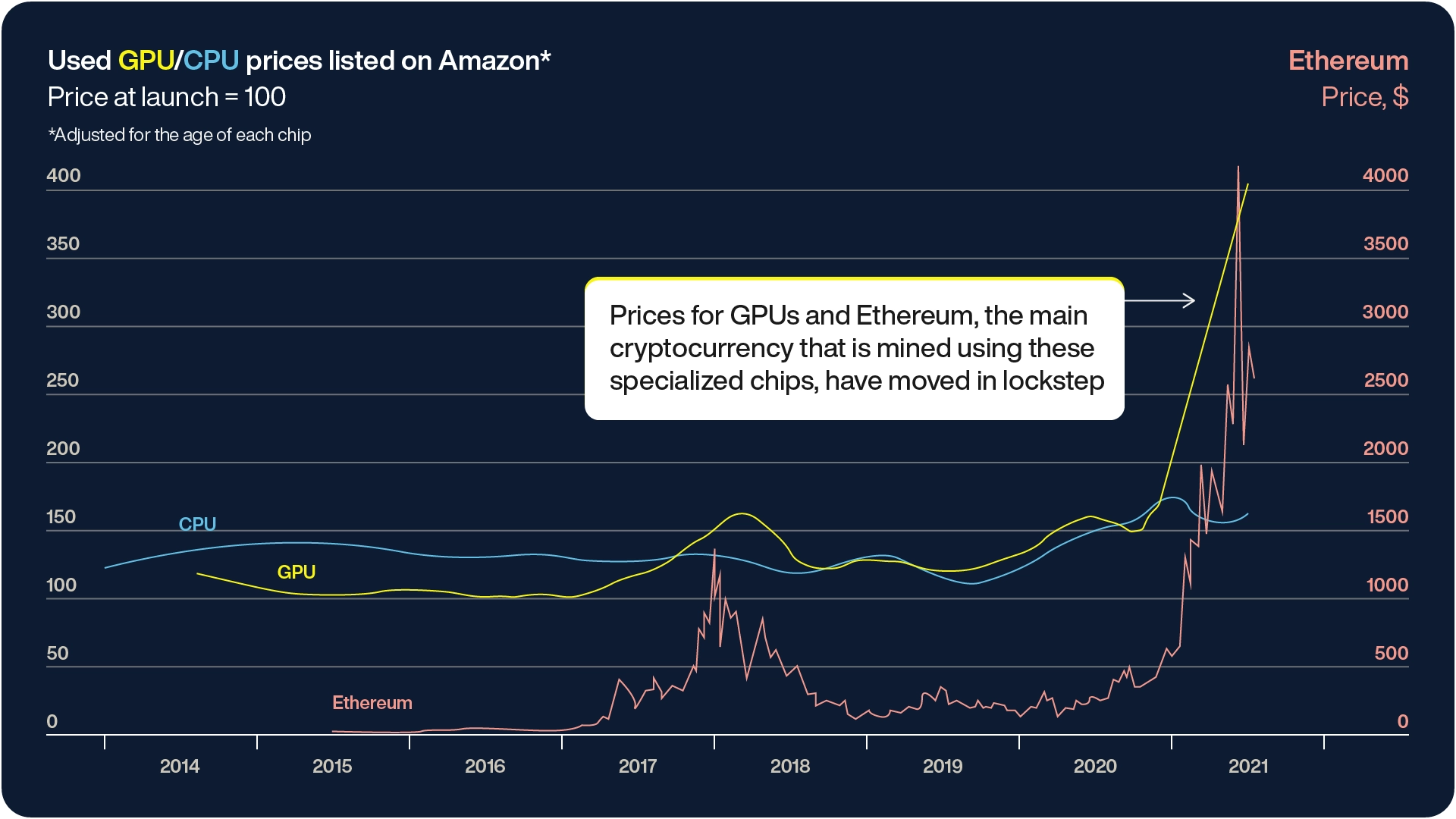
For instance, OpenAI’s GPT-4 was trained using approximately 25,000 NVIDIA A100 GPUs over the course of 100 days, with costs soaring to around $100 million. This demand has only intensified, making it harder for businesses to access the necessary hardware for machine learning (ML) projects.
While GPUs offer unparalleled performance, especially in training complex models with their powerful parallel processing capabilities, they are not always the most cost-efficient solution, especially with the current scarcity. Many organizations are now looking for alternative ways to continue scaling their ML projects by leveraging central processing units (CPUs), which are often more readily available and cost-effective for specific tasks like real-time inference.
In this blog, we will explore the architectural differences between CPUs and GPUs, their roles in ML workflows, and how integrating an ultra-low-latency database like Aerospike can help mitigate bottlenecks, optimize performance, and accelerate model training and inference—even in the face of GPU scarcity.
What is a CPU?
A central processing unit (CPU) is often referred to as the "brain" of a computer. It is a general-purpose integrated circuit processor designed to handle a wide range of tasks, from executing simple commands to running complex software programs. A CPU typically consists of a few powerful cores optimized for sequential processing. Each core includes an arithmetic logic unit (ALU) and a control unit, which together handle the execution and flow of instructions at the hardware level. This design means it excels at tasks that require high precision and low latency, such as web browsing, word processing, and running operating systems.
Each CPU core is capable of executing a single thread of instructions at a time, making it highly effective for tasks that require fast, individual calculations. In a machine learning context, CPUs are ideal for handling sequential tasks, like data preprocessing, feature engineering, and lightweight model inference, particularly when dealing with smaller datasets. While CPUs may not match the raw parallel computing power of GPUs, they are better suited for tasks that require rapid switching between operations or handling random access memory patterns.
Modern CPUs are built with multiple cores and are supported by multiple cache layers to optimize data access and processing speeds. These cores use cache memory—such as Layer 1 (L1), Layer 2 (L2), and Layer 3 (L3) caches—to store frequently accessed data, reducing the time it takes to retrieve information from the system’s main memory. This architecture is designed to minimize latency and ensure that CPUs can efficiently manage multiple tasks simultaneously. In many consumer and edge computing systems, modern CPUs also include an integrated GPU (integrated graphics) on the same chip for basic graphics processing tasks. This highlights how the CPU serves as an all-purpose workhorse for general computing beyond just numerical calculations.
In many machine learning workflows, CPUs are used during data preprocessing and exploratory data analysis (EDA), where their ability to handle general-purpose computing tasks with low latency shines. Moreover, for smaller models or inference tasks that do not require the heavy parallelism of a GPU, CPUs are often the more cost-effective and efficient choice.
What is a GPU?
A graphics processing unit (GPU) is a specialized processor originally designed to accelerate the rendering of graphics, particularly in gaming and visual applications. Over time, however, the role of GPUs has expanded significantly, and they are now integral to various compute-intensive tasks, especially those requiring parallel processing. In the context of machine learning, GPUs have become a go-to solution for training large-scale models because they are optimized to handle multiple operations simultaneously.
Unlike CPUs, which are designed for sequential processing, GPUs consist of thousands of smaller, more efficient cores capable of executing many calculations in parallel. This architecture is ideal for matrix computations and operations involving large datasets, which are common in deep learning and other ML algorithms. These GPU cores work together to process data in parallel, making GPUs highly efficient for tasks such as training deep neural networks, where numerous calculations must be performed simultaneously.
For instance, when training a large ML model, a GPU can perform billions of operations per second by distributing the workload across its many cores. This ability to handle high throughput and process data in parallel is what gives GPUs a significant performance advantage over CPUs for certain tasks, particularly those involving large datasets or complex algorithms like 3D graphics rendering, graphics processing, and AI model training.
One key component of GPU architecture is its ability to tolerate memory latency more effectively than a CPU. While a CPU relies heavily on its cache layers to maintain low latency, a GPU dedicates most of its transistors to computation rather than caching, allowing it to handle parallel computations even when there is a delay in retrieving data from memory. This makes GPUs the preferred choice for tasks requiring massive amounts of data to be processed quickly, such as deep learning and AI training.
In addition to its role in training, GPU technology is also used in real-time applications such as inference. It can process vast amounts of data and deliver results at high speeds, especially when combined with high-performance computing infrastructure. Whether in training or real-time deployment, GPUs' power lies in their ability to accelerate tasks that require simultaneous processing of multiple operations. Typically, GPUs are deployed as discrete add-in cards (graphics cards) with their own dedicated memory (VRAM). In modern data centers and cloud AI platforms (like Google Cloud or AWS), multiple GPUs can operate in parallel across clusters, forming a powerful GPU cluster that tackles massive workloads in tandem. This kind of setup showcases unmatched GPU performance in parallel computation for tasks like deep learning, scientific simulation, or GPU rendering—far beyond what a single CPU could achieve.
CPU vs. GPU architecture and use
GPU-accelerated computing is a technique that leverages both CPU and GPU for processing tasks such as deep learning, analytics, and 3D modeling. In this approach, the GPU handles compute-intensive processing while most of the code runs on the CPU, optimizing overall performance.
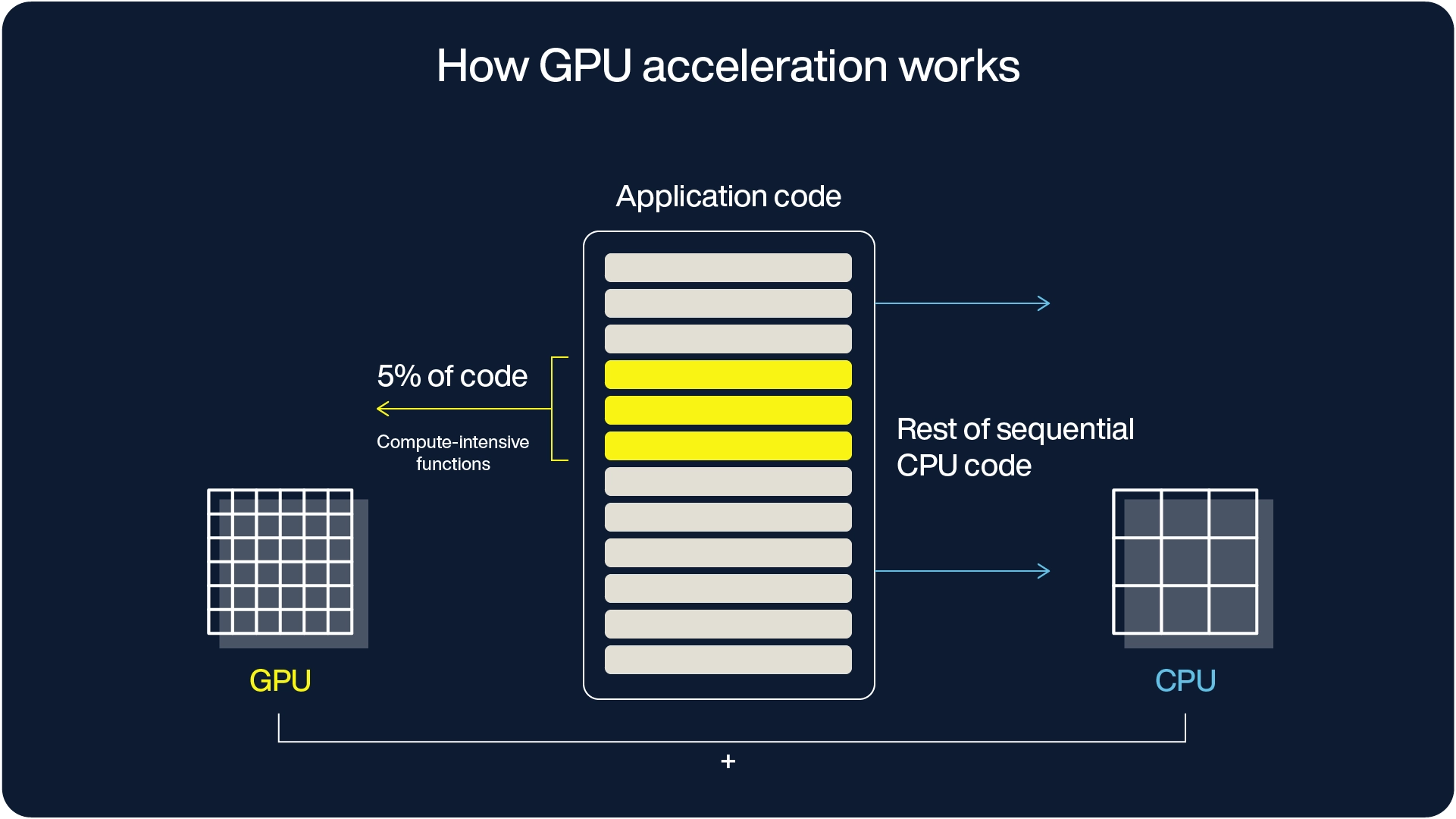
CPU architecture
Core structure: A CPU consists of a few cores optimized for general-purpose sequential serial processing.
Optimization: CPUs are designed to complete tasks with the lowest possible latency and can quickly switch between operations.
Cache system:
Layer 1 (L1) cache: Each CPU core has its own dedicated L1 cache for data and instructions.
Layer 2 (L2) cache: Larger and slightly slower than L1, the L2 cache supports individual cores.
Layer 3 (L3) cache (last level cache - LLC): A shared cache layer that serves multiple cores simultaneously.
Memory retrieval: If data isn't found in the cache layers, the CPU retrieves it from the main memory, prioritizing low-latency access for efficiency.
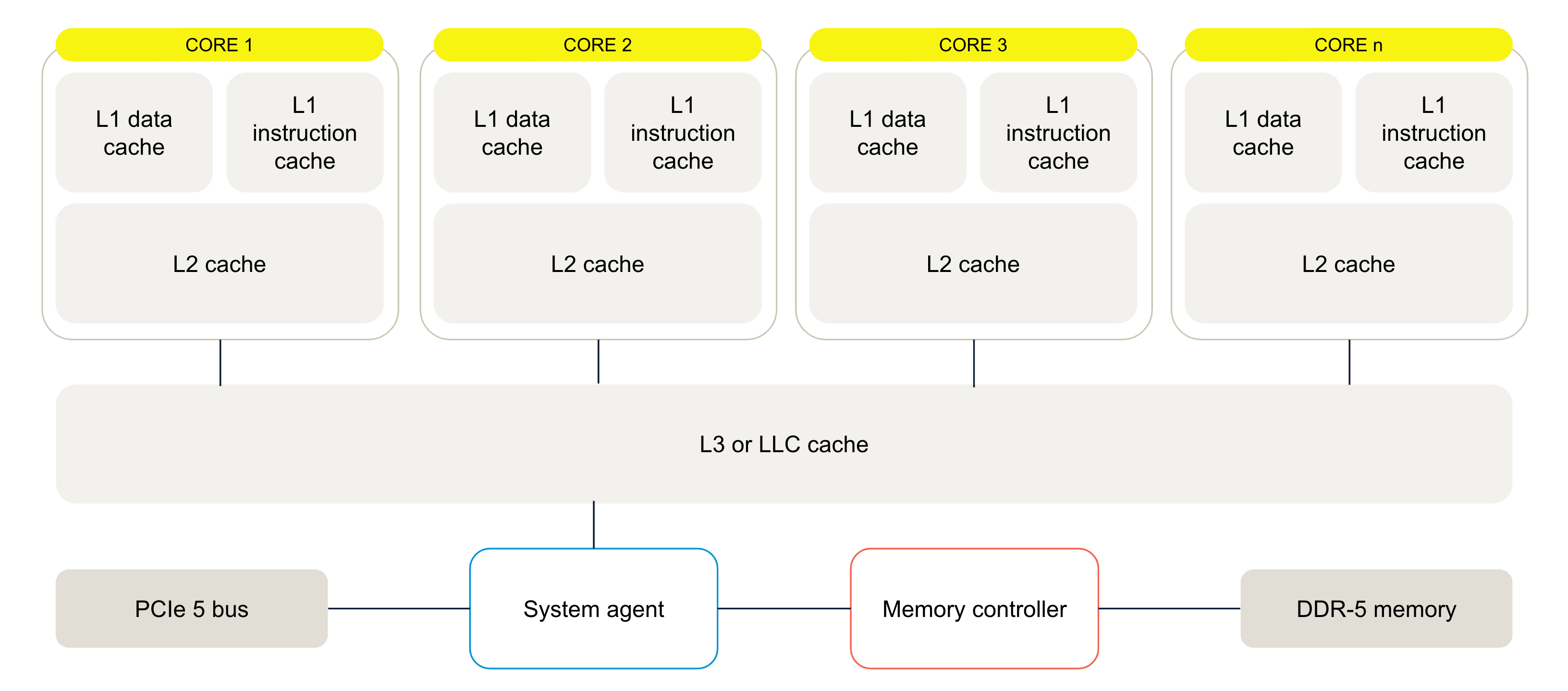
GPU architecture
Parallel architecture: A GPU is optimized for throughput, with a massively parallel architecture consisting of thousands of efficient cores designed to handle multiple operations simultaneously.
Core structure:
Streaming multiprocessors (SMs): GPUs contain processor clusters made up of SMs, each with multiple cores.
CUDA cores: For NVIDIA GPUs, these cores are known as CUDA cores, each with its own arithmetic logic unit (ALU) for handling complex AI algorithms.
Cache System:
Dedicated L1 cache: Each SM typically has an L1 cache for quick access to instructions.
Shared L2 cache: The SMs utilize a shared L2 cache before accessing high-speed memory.
Memory latency tolerance: Unlike CPUs, GPUs are designed to tolerate higher memory latency. They dedicate more transistors to computation rather than caching. The architecture focuses on keeping the GPU busy with parallel computations despite slower memory access.
Key differences between CPU and GPU
Processing optimization:
CPU: Optimized for low-latency, sequential processing.
GPU: Optimized for high-throughput, parallel processing.
Core functionality:
CPU Cores: General-purpose cores that excel at handling a wide range of tasks with rapid switching.
GPU Cores: Specialized cores (like CUDA cores) tailored for specific tasks, such as AI and graphics processing.
Memory system:
CPU: Relies heavily on cache layers for fast data retrieval.
GPU: Focuses on parallel computations and tolerates latency with fewer cache layers.
The key differences come down to flexibility versus throughput: a CPU is ideal for general computing and quick context-switching between tasks, whereas a GPU is a specialized processor built for massive parallel operations and high data throughput. It’s worth noting that beyond CPUs and GPUs, there are also specialized accelerators like Google’s Tensor Processing Unit (TPU) for AI workloads – but for most applications, the CPU/GPU duo remains the primary consideration when designing an AI system.
When to use a CPU vs. a GPU in your ML workflow
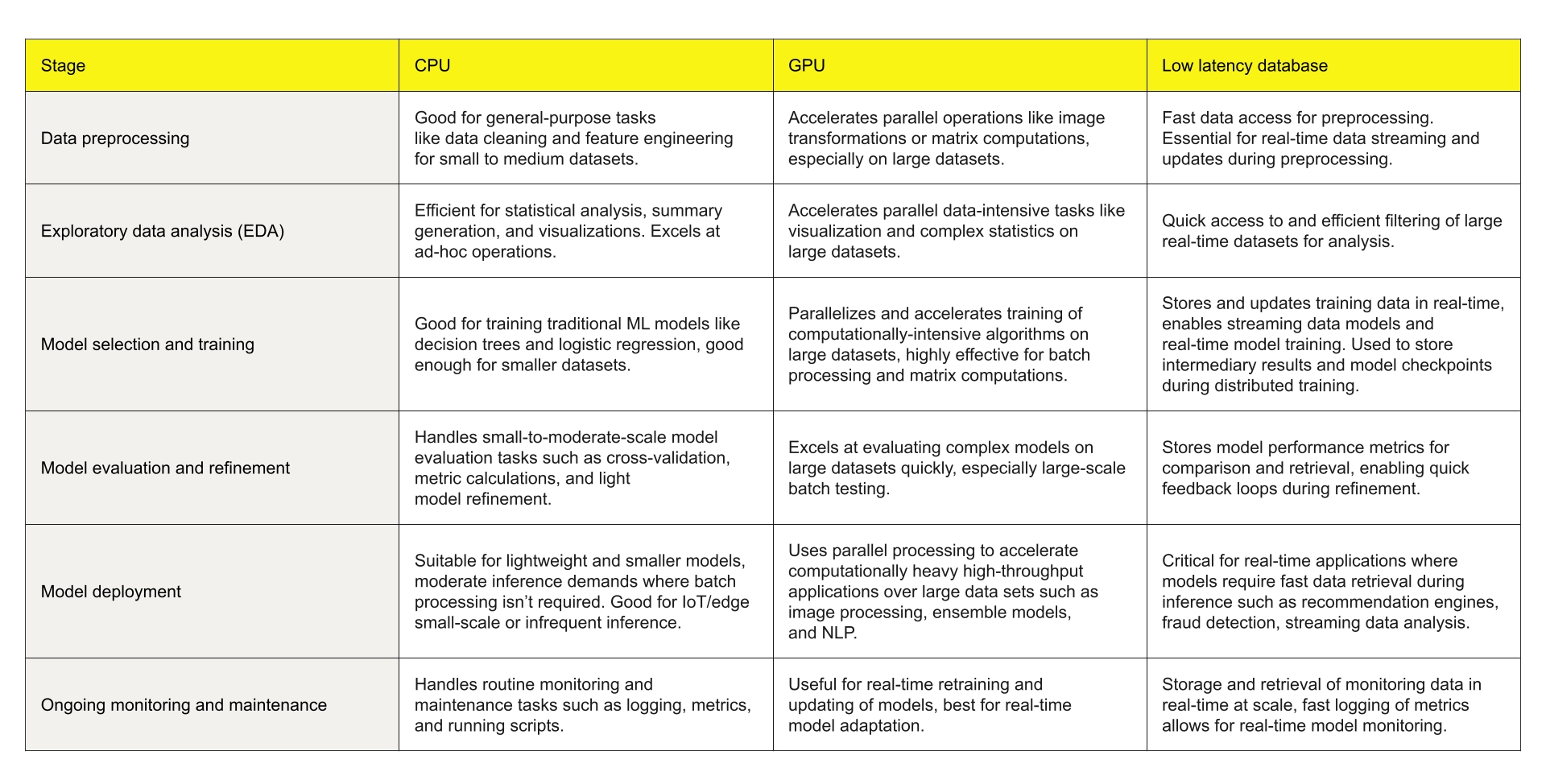
Choosing between a CPU and a GPU for your machine learning (ML) workflow depends on the specific requirements of your project. Both processors excel in different tasks, and understanding when to use each can help optimize performance, cost, and speed. Let’s break down which hardware to leverage at various stages of an ML pipeline.
Data preprocessing & feature engineering
This initial stage involves gathering data, cleaning it, and transforming it into a suitable format for modeling. These tasks often involve a lot of file I/O, string parsing, and sequential operations over many small pieces of data. CPUs are typically better suited here because they handle diverse, general-purpose tasks well and can leverage multiple cores for parallel processing of many small jobs. A CPU can quickly switch contexts and manage complex data manipulation (e.g., reading from disk or a database, aggregating logs, merging datasets), which often saturates memory or I/O bandwidth before compute. Using a GPU at this stage usually isn’t efficient, as the bottleneck is not raw computation but data movement and preprocessing logic. In practice, a strong CPU (or cluster of CPUs) paired with fast storage or an in-memory database will streamline the data prep phase more effectively than a GPU.
Model training (especially deep learning)
The training phase is where GPUs truly shine. Training complex models—such as deep neural networks—involves performing vast numbers of mathematical operations (like matrix multiplications and other linear algebra) that benefit enormously from the GPU’s parallel architecture. In scenarios with large datasets and heavy computation, a single GPU or a cluster of GPUs can reduce training time from weeks to days (or days to hours). Modern ML frameworks take advantage of GPU acceleration (via libraries like NVIDIA’s CUDA and platforms like TensorFlow/PyTorch) to distribute computations across thousands of GPU cores. However, one should consider availability and cost: high-end NVIDIA or AMD GPUs are expensive and sometimes scarce, so if the models are smaller or budgets are limited, training on CPUs (or renting specialized hardware on AWS, Azure, or Google Cloud) might be a viable alternative. Generally, for most deep learning tasks, GPUs are preferred for their parallel computing power, but CPUs can suffice for simpler models or preliminary experiments when GPU resources are constrained.
Model inference and real-time services
Deploying a trained model for inference (making predictions) can effectively use either CPUs or GPUs, depending on the use case and throughput requirements. If you need to handle a high volume of concurrent requests — for example, applying a vision model to a video stream or running a large language model service — a discrete GPU can process many inferences in parallel and offer high throughput. On the other hand, for live services that require consistently low latency per request (such as an API that must respond in a few milliseconds), CPUs are often more efficient. A CPU can handle individual inference requests quickly without the overhead of transferring data to a GPU and waiting in a GPU queue. Additionally, scaling out with many inexpensive CPU servers (horizontal scaling) can be more cost-effective and easier to manage than concentrating load on a few costly GPU nodes. Using an ultra-low-latency data platform like Aerospike as a feature store or caching layer further enables CPUs to serve predictions with minimal delay. That said, for extremely large models (like some cutting-edge Transformers) or computationally intensive tasks (like real-time 3D graphics in gaming/AR), the raw power of a GPU or specialized AI accelerator may be necessary to meet requirements. In practice, many production ML systems use a hybrid approach: CPUs handle data preprocessing, business logic, and other general computing, while GPUs accelerate the heavy ML computations where massive parallelism is beneficial. The key is to match the hardware to the workload for optimal efficiency.
Optimizing real-time ML pipelines is more than leasing GPU time
Despite the hype around using GPUs for ML, efficient workflows often outperform expensive (and scarce) GPUs. Most AI pipelines spend more time managing data than training or running models. Google, Microsoft, and others estimate that 70% of model training time is data acquisition, cleaning, and staging. Multiple data transfers between stages create latency, wasting precious GPU resources. In practice, optimizing how data flows through each processing unit (CPU, GPU, or otherwise) often yields greater performance benefits than simply adding more hardware. By eliminating bottlenecks in the pipeline, you reduce idle time and unnecessary GPU work, ensuring that expensive GPUs are only tasked with the intensive parallel computations they do best.
Many small files (versus fewer large files) slow the AI pipeline – and GenAI/RAG/LLM training requires many, many small files. Ingesting lots of small files – millions of small images, per-device IoT logs, per-transaction customer database logs, etc. – creates massive amounts of metadata.
To maximize ML benefits, remove data pipeline bottlenecks. Aerospike minimizes data transfer times for training and inference, increasing data analysis capacity.
Deploying Aerospike in your real-time ML pipeline has several advantages:
Reduced latency: With model parameters stored in Aerospike, inference requests can be processed with minimal data movement, resulting in faster response times.
Scalability: Horizontal scaling enables organizations to handle increasing inference loads by simply adding more nodes to the cluster.
Cost-efficiency: By leveraging CPUs for inference instead of expensive GPUs, organizations can significantly reduce their hardware costs while maintaining high performance.
Real-time updates: Aerospike's support for real-time data updates means that model parameters or features can be updated on the fly, allowing for continuous model improvement without downtime.
High throughput: Aerospike can handle millions of transactions per second, making it well-suited for high-volume inference.
Don't let GPU scarcity hinder ML progress. Aerospike enables faster model building, training, and deployment. Embrace the power of real-time data and leave those GPU wait times in the dust.
Real-time machine learning needs a real-time data platform
Real-time machine learning relies on ultra-low-latency databases to handle fast data ingestion and support ML models in making quick decisions. AI leaders focus on databases that can process new data at high speeds, ensuring that ML models receive timely and relevant information for tasks like recommendation engines or fraud detection.
Optimizing ML for real-time performance
Running ML models in production demands low-latency data access to ensure a seamless user experience. Models should be optimized for quick inference using techniques like model pruning, and the data infrastructure should include efficient caching, load balancing, and auto-scaling to handle changing traffic loads.
Aerospike's role in real-time ML
Aerospike, a leader in low-latency databases, has served as the data foundation for ML applications for almost a decade. Aerospike is used by PayPal and Barclays for real-time fraud detection, Wayfair for recommendations, and Flipkart, Myntra, and AppsFlyer for a diverse set of ML use cases.
Aerospike’s Hybrid Memory Architecture (HMA) delivers sub-millisecond data access. It combines the speed of DRAM with the cost-efficiency of SSDs, making it ideal for large-scale data processing and real-time decision-making.
Scalable architecture for growing data needs
Aerospike's architecture allows it to scale to billions of records and petabytes of data without losing performance, thanks to its distributed, multi-threaded design. This scalability reduces hardware needs and keeps response times low, even with large datasets.
Seamless integration with ML frameworks
Aerospike integrates with popular ML tools, like Aerospike Connect for Spark, to support data loading, transformation, and model training. This compatibility enables easy adoption into existing workflows, speeding up data exploration and ML development.
Fast data access for real-time applications
Aerospike's in-database processing and low-latency feature store capabilities reduce data movement and speed up model iteration. In use cases like real-time fraud detection or chatbots, Aerospike provides immediate access to relevant data, enabling quick, personalized responses with minimal delay.
For more details on the technology behind this approach, you can check out GPU computing basics.
Keep reading

Oct 9, 2024
Data replication between data centers: Log shipping vs. Cross Datacenter Replication

Sep 18, 2024
Balancing data durability and data availability for high-performance applications
Sep 11, 2024
Developing applications for speed, scale, and efficiency in Aerospike 7+

Jan 30, 2024
What is an in-memory database?