Data replication between data centers: Log shipping vs. Cross Datacenter Replication
Discover how Aerospike's Cross Datacenter Replication (XDR) delivers ultra-low latency, precise control, and efficient data transfer to enhance global data performance.

Cross Datacenter Replication (XDR) is an essential tool for increasing data availability, global performance, and disaster recovery.
Many businesses rely on data distributed across multiple geographic locations to feed their internal and customer-facing applications. This approach can yield performance improvements, but it makes it much more complex to maintain high availability, manage network latency, and ensure overall uptime. XDR attempts to address these challenges by synchronizing data between database clusters operating in different data centers.
However, there are multiple ways to build XDR, each with advantages and disadvantages. The most basic method is log shipping, in which a primary node or cluster logs every transaction, the log is copied to a secondary node or cluster, and the transactions are restored. MongoDB takes a similar approach with replica sets, where a primary node logs writes to an oplog, and secondary nodes replicate the primary’s data by continuously applying the operations from the oplog. The primary node and secondary nodes can be located in different data centers. Cassandra replicates complete copies of partitions, relying on the same mechanisms to replicate within a cluster and between data centers. Couchbase relies on an agent running on the source cluster to ship all new and changed data to a secondary cluster.
This blog post examines log shipping, the first methodology mentioned, and compares it to Aerospike XDR, the feature in Enterprise Edition that enables data replication between clusters. Then, we’ll dig into XDR to understand why it is inherently more configurable and delivers higher performance.
Log shipping: Basic, reliable, but not real-time
You may already be familiar with log shipping for XDR. It is the mechanism used in Microsoft SQL Server, MySQL, and Oracle.
Log shipping automatically backs up transaction logs from a primary database and restores them to one or more secondary databases. This creates a warm standby copy of the database typically used for disaster recovery, analytics, reporting, or machine learning.
Log shipping is fundamentally three processes:
First, a job backs up the log on the primary server to a local location.
A second job copies the backups across the network to each secondary server.
A third job restores the backups, in the case of SQL Server, using the WITH STANDBY option. The database on the secondary server is accessible but is read-only.
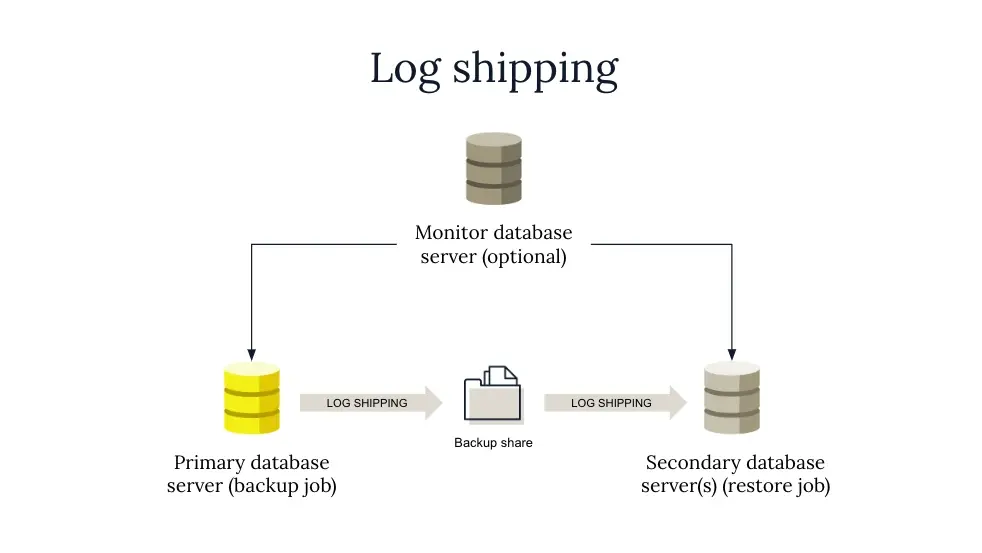
A major drawback to this methodology is that it is not real-time. There will always be some delay between the databases because the transaction log is backed up at regular intervals, 15 minutes, for example. This means that it is possible to lose data if the primary server goes down.
Complications can arise because log shipping must be coordinated with backup schedules and retention policies to best utilize storage and network bandwidth.
Aerospike XDR: Fine-grained filtering and low-latency transfer
Aerospike XDR replicates data asynchronously between two or more clusters. These clusters can be in a different physical rack, availability zone, cloud region, or continent. XDR works for heterogeneous clusters of different sizes, storage sizes, operating systems, etc. XDR applies fine-grained controls to data replication and can be used to build globally distributed applications with low latency reads and writes at local data centers, create a digital twin for analytics and machine learning (ML), or disaster recovery/failover. XDR is included with Aerospike Enterprise Edition. (For more information, see Cross-Datacenter Replication (XDR) architecture | Aerospike Documentation.)
Replication policies are defined per data center and can be configured on a namespace, set, or bin level. In Aerospike, a namespace is a high-level container for data (similar to a database), a set is a subset within the namespace (like a table), and a bin is the equivalent of a column in a record, storing individual data values. Configuration can be static (set in the Aerospike configuration file) or dynamic. We recommend configuring XDR dynamically so that all nodes start shipping at the same time.
XDR can be deployed using different topologies, as detailed here.
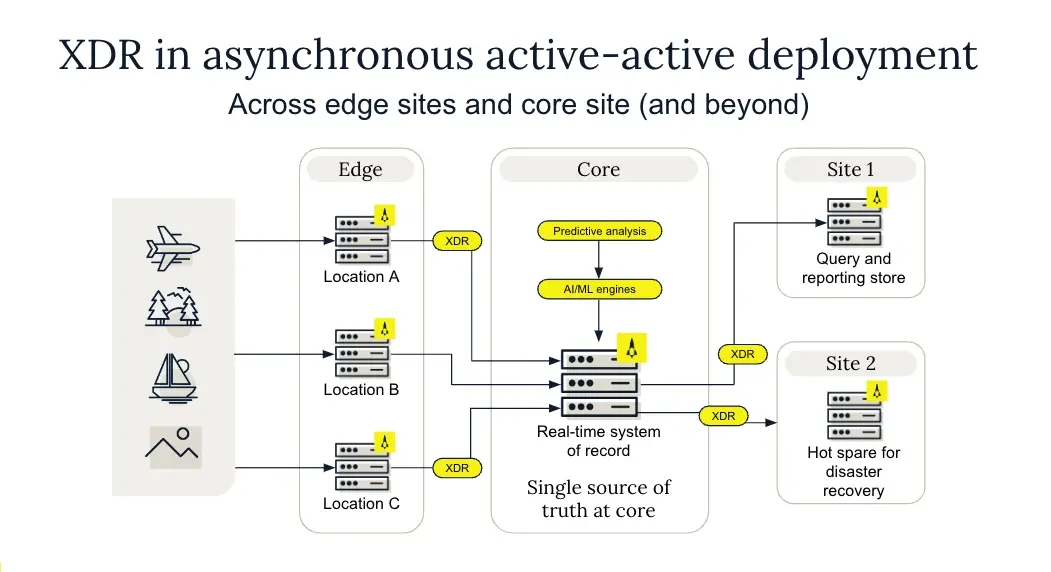
How XDR works
XDR replicates data asynchronously, meaning that the primary node commits the write transaction immediately and then updates the replica nodes using XDR. A transaction in Aerospike is an atomic operation that modifies multiple bins within a single record. It ensures that all operations within the transaction complete successfully or fail together, guaranteeing data consistency. Aerospike’s low-latency writes and reads are independent of and unaffected by XDR.
XDR does not rely on a log to know what to replicate; instead, it relies on a transaction queue. The transaction queue is written after every transaction and read by XDR every 100ms (also configurable), meaning there is only a 100ms delay compared to the typical 15 minutes or more for log shipping. This method is more timely and uses less local resources and bandwidth than log shipping.
The transaction queue is organized per data center, per namespace, and per partition in memory. In this transaction queue, XDR tracks and maintains a very small amount of metadata, around 25 bytes per write, regardless of the actual record size. The XDR processes run as service threads that are deeply integrated with other running ADB server threads. One thread reads from the transaction queue every 100ms and, when replication is necessary, hands off to a service thread to perform a local read, apply compression, and ship the record. Aerospike carefully deals with data contention at the granularity of a partition (to achieve the right balance between performance and granularity of contention) and localizes all XDR operations on a partition into a single service thread to minimize contention.
Continuing the theme of efficient thread use, when XDR encounters errors, they do not affect XDR or the server’s overall performance. Aerospike uses another thread for retries that hands off to a service thread to repeat the local read and shipping attempt.
For a complete description of the procedure XDR uses, please see XDR record shipment lifecycle | Aerospike Documentation.
What makes Aerospike XDR unique
Aerospike XDR is designed and built to connect global data centers and edge deployments to maintain the high availability that real-time applications require because it uses the following:
Service threads for unrivaled performance
XDR runs on a service thread instead of a process thread, resulting in massively increased performance and tighter integration with all Aerospike server components. Processes and threads are basic operational components of an operating system. A process is essentially a running program scheduled in the CPU for execution that spawns one or more threads in the context of the process. Processes can also spawn child processes. The drawback is that multiple threads within a process can compete for resources such as memory. Processes are meant to be isolated – they take more time to start, context switch, and terminate than threads. A system call is required to start a process, whereas a thread can be created through an API. In contrast, service threads are lightweight processes that run in parallel and require fewer resources.
Running XDR as a service thread enables Aerospike to provide efficient, low-latency, and reliable Cross Datacenter Replication for real-time mission-critical applications. XDR is your only choice if you have very high throughput and require ultra-low-latency replication. As long as the network is not the bottleneck, XDR will achieve extremely low-lag replication. Versions 6.1 and 6.4 included massive performance improvements, and version 7 ups the ante even further. With service thread affinities to partitions, XDR is capable of more than twice the throughput of version 5 and earlier.
These improvements in the way that XDR runs have a significant positive impact on performance and scalability:
Improved performance and lower latency: XDR traffic has been reorganized to minimize the use of expensive locks. Traffic between two nodes now executes on the same service thread, leading to higher cache usage, increased throughput, and lower latency.
Thread affinity and cache-friendliness: The service thread takes care of all phases of the shipping lifecycle, achieving thread affinity and cache-friendliness. The same service thread will read from disk, ship to the destination data center, and wait for the response. High-frequency paths no longer require locks, making XDR extremely cache-friendly.
Elimination of dependencies between data centers: By having a dedicated thread for each destination data center, there is no dependency between data centers. This means that even if a link is down or flaky for one data center, all other data centers can continue unaffected.
More efficient use of resources: The new XDR architecture eliminates dependency on the Aerospike C client library for XDR-related data transfers, resulting in a major performance boost. This approach reduces overhead, particularly in terms of extra threads and stages, and records object conversions.
Better handling of hot keys: Service threads can more efficiently manage hotkeys (keys that are written with very high frequency) through the use of caches, helping to prevent bottlenecks in XDR operations.
Improved scalability: By running XDR as a service thread, Aerospike can better handle increased load and scale up to higher throughput levels on fewer nodes.
Tunable for unreliable networks: XDR assumes that disruption is possible and provides administrators with configuration parameters to optimize performance in unreliable network conditions, such as adjusting retry intervals, maximum throughput, and timeout values.
Filtering to minimize data transfer
XDR provides bi-directional filtering, which allows for selective replication of data attributes. This fine-grained data control with selective shipment of record components makes XDR very efficient. XDR can be configured to ship only the changes to bins within records. Complex expressions – similar to selecting by query or running a batch job – can be used for filtering updates and inserts and applied to records as they are shipped. This not only conserves network resources between sites but it can also be used to comply with global and local data privacy regulatory requirements by preventing sensitive data from leaving the cluster. For example, if you were running Aerospike in Europe and wanted to comply with GDPR, you would use expressions to block protected information from leaving the region.
To learn more about Expressions, please see Aerospike Expressions for more details.
Failure handling without interruption
XDR handles source and destination failures. This is especially helpful when connectivity between data centers and edge deployments frequently goes up and down. In the event that something goes wrong with the replication process, we have built error-checking and recovery mechanisms into XDR. XDR gracefully handles local node failure, remote link failure, and combinations of the two. First, replication via the failed link or to the failed remote cluster is suspended. After the issue has been resolved, XDR resumes for the previously unavailable remote cluster and runs until it is fully current. While this occurs, replication via functioning links remains unaffected.
If the connection between the local and remote cluster drops, each master node records the point in time when the link went down and shipping was suspended. When the link becomes available again, client writes that were held back when shipping was suspended are shipped, and new client writes are shipped the same way they were before the link failure.
Should hardware or software failure occur in the primary (local) cluster, another master node can step in to remote cluster nodes. When the master node returns, XDR reads from primary indexes and reconstructs the changes, simplifying recovery and getting you operational again quickly.
Rewind for precision restoration
XDR includes a rewind feature that allows users to rewind the replication of records from a specific point in time. This functionality is particularly useful for disaster recovery or when synchronizing data between clusters. To use the rewind feature, administrators simply specify the data center, namespace, and the desired rewind time in seconds or use "all" to restart from the beginning. This feature provides flexibility in managing data synchronization across Aerospike clusters, allowing for precise control over the replication process. If the transaction queue is overrun by write throughput far exceeding the current network bandwidth to the other cluster, then rewind capability is invoked for error recovery. See asinfo for more information.
Aerospike XDR for the win
Aerospike XDR offers several improvements over typical log shipping replication, particularly in terms of flexibility, efficiency, and latency. Both are asynchronous, but XDR is record-based, while log shipping is log-based. XDR tracks each record’s Last Update Time (LUT) and compares it to the Last Ship Time (LST) to determine what needs to be replicated, whereas log shipping replicates the entire log file and all of its transactions.
Log shipping is not fast, and delay is built into the process because it runs on a set schedule. But that isn’t what people want – today’s businesses demand real-time or at least something close to real time. They want transactions replicated as soon as possible when they are committed. Log shipping saves logs to disk, consuming storage and only replicating on a schedule. In contrast, the Aerospike primary holds updates in memory and ships them immediately.
Key advantages of XDR over log shipping include:
Granular control: XDR is defined per data center with granularity per namespace, set, or bin. XDR allows for dynamic, fine-grained data control, enabling selective shipment of record components.
Bidirectional filtering: XDR supports bi-directional filtering capabilities, allowing for more complex and efficient replication setups.
Low latency: XDR is designed for ultra-low latency operations, making it suitable for real-time applications. It replicates data asynchronously, ensuring that write transactions are not delayed by the replication process.
Efficient: XDR leverages built-in deduplication and compression to help optimize network bandwidth usage.
Fault tolerance and redundancy: XDR provides robust fault tolerance and redundancy features.
Deployment flexibility: XDR supports various deployment topologies, including active-active configurations, which are not feasible with log shipping.
Integration with non-Aerospike systems: Through connectors, XDR can facilitate data transfer to non-Aerospike repositories, such as ERP or CRM systems.
Overall, Aerospike XDR provides a more advanced and adaptable replication solution than traditional log shipping, particularly for distributed, real-time, and mission-critical applications.
Keep reading

Oct 8, 2024
Aerospike Database 7.2: Enhanced clustering and XDR controls

Sep 22, 2022
Aerospike Cross Datacenter Replication (XDR) for Real-time Mission Critical IoT Data Management
Feb 28, 2024
The essentials of a modern distributed database
Dec 14, 2023
Geo-distribution deployment models: Achieving business outcomes while minimizing latency