The essentials of a modern distributed database
Explore the essentials that define the modern distributed database landscape and how to prepare your business for success.

In my time at Aerospike, I’ve traveled to meet with hundreds of customers and prospects in all regions, time zones, and industries. I can safely say that across the world, smarter companies are looking to leverage real-time data to improve the user experience of applications catering to tens of millions to hundreds of millions of consumers. Such companies are well aware of the need for a more modern, distributed database that is not just very fast but extremely reliable and robust enough to handle data growth rates upwards of 30% per year while not breaking their IT budgets. However, many don’t know to what extent such a database is feasible.
This blog is based on the techniques we invented while building Aerospike, a distributed database with the attributes required for handling such demanding consumer applications. This blog distills what makes such a distributed database function and excel. We’ll navigate through the essentials that define the modern distributed database landscape: horizontal scaling (scaling out), vertical scaling (scaling up), strong consistency with high performance and availability, and geo-distributed transactions. These essentials are not just theoretical concepts; they are the pillars upon which we’ve built a modern distributed database that can handle the ever-growing demands of applications, delivering the best possible user experience to tens of millions of consumers by using large amounts of data, real-time processing, predictive analytics using AI/ML and more recently, generative AI processing.
Let’s explore these essentials, understand their significance, and see how they come together to create a database system that’s not only poised for today’s challenges but also adaptable to those down the road.
Horizontal scaling: Mastering elasticity
In the realm of distributed databases, horizontal scaling is a cornerstone of modern data management. Scaling out refers to the process of expanding a database by adding more nodes to a cluster, enhancing its ability to manage growing data demands. Efficient scaling out must address a few key topics.
Shared-nothing architecture: No single point of failure
Our system uses a shared-nothing architecture in which all nodes forming the database cluster are identical in terms of CPU, memory, storage, and networking capacity. Moreover, the nodes are peers of each other, i.e., they are identical in terms of the code that runs on them. Therefore, every node can perform all the tasks of running the database – there’s no single point of failure in the cluster.
Eliminating hotspots: No bottlenecks
A critical challenge in scaling out is avoiding ‘hotspots’ – areas in the database that face excessive load. In a well-designed distributed database, the goal is to distribute data and workload evenly across all nodes. This not only optimizes resource usage but also ensures that no single node becomes a bottleneck, maintaining smooth operation even as more nodes are added.
Uniform data partitioning: Balanced workload distribution
Effectively scaling out a database system requires that data be partitioned and distributed. Our scheme uses a “divide and conquer” strategy, employing a uniform data partitioning system. Utilizing the RIPEMD-160 hashing mechanism, data is evenly distributed across 4096 partitions, spanning all cluster nodes. This isn’t just about spreading out data; it’s about smartly allocating it so that each node carries a fair share of the load, ensuring efficiency and reliability.
The original partitioning mapping algorithm was designed to minimize data movement when a node is added or dropped from the cluster. Note that the requirement to provide minimal data movement can create a significant partition skew (~20%) in large cluster sizes (> 100 nodes). We have designed a uniform data partitioning algorithm that allows more data movement when nodes are added or dropped to eliminate all skew regarding partition assignment to nodes.
Grouping nodes within a cluster into separate racks (rack awareness) guarantees that each partition’s master and replica(s) are stored in nodes that are in separate failure groups, i.e., each rack is in its own distinct failure group that is different from the failure groups of other racks. This ensures that data is not lost in case of hardware failures that take an entire rack down, and it also helps reduce network traffic by allowing application clients to read data from servers closest to their location (nodes within a rack are colocated).
Dynamic cluster management: Continuous operation during failures
Millions of users can access (or leave) an application with internet-scale applications within a short real-time window. Therefore, an application’s data needs can change rapidly, so dynamic cluster management (system elasticity) is crucial. This means that new nodes need to be added and existing ones removed without any service outage or interruption to the flow of transactions. Moreover, whether nodes are added or removed, a heartbeat mechanism immediately recognizes that, automatically rebalances data, metadata, and indexes between all nodes, and adjusts transaction workload by redistributing everything evenly across nodes. This seamless data redistribution and workload rebalancing without service interruption is key to maintaining high performance and availability. The database must dynamically adapt to mixed workloads, ensuring optimal performance under varying conditions.
The Smart Client: Scale linearly with one-hop-to-data
Another vital aspect of scaling out is the role of the Smart Client. Unlike traditional databases, where clients might need to go through multiple hops to find the data, our Smart Client technology ensures direct and efficient data access, thus minimizing latency. The Smart Client (typically embedded into an application via a code library) directly connects to the relevant node, ensuring a one-hop data retrieval path, which is especially crucial in large, distributed clusters. The one-hop-to-data scheme also ensures linear scalability of the system as the numbers of server nodes and application nodes increase over time.
Beyond basic scaling: Handling real-world complexities
As we saw, horizontal scaling involves more than just adding nodes; it’s about how these nodes interact, share data, and maintain consistency. Sophisticated synchronization and fault-tolerance mechanisms are integral to this process. The system is engineered to handle node failures, network issues, and other real-world challenges efficiently, ensuring data integrity and system performance are not compromised.
In short, horizontal scaling is about intelligent, efficient, and seamless technical infrastructure growth to support high business growth. In our current era – with big data everywhere- the scalability of key technical systems, including the real-time database, has become synonymous with survival.
Our horizontal scaling strategy is based on a shared-nothing architecture, eliminating hotspots, uniform data partitioning, dynamic cluster management, and Smart Client technology. This exemplifies how to handle these horizontal scaling challenges. The goal here is to ensure that a 10X (or even 100X) growth can be achieved without any reengineering of the system architecture. This is critical for business success.
Vertical scaling: Maximizing cloud and hardware utilization
Scaling up, or vertical scaling, refers to bolstering the capabilities of each individual node to efficiently handle more data, connections, and transactions. This means maximizing every aspect of processor, storage, and networking capacity within each node. Aerospike’s approach to vertical scaling is a blend of software and hardware optimization using patented algorithms, ensuring that each node operates at its maximum potential. Here’s an in-depth look at how we achieve this.
Hybrid Memory Architecture (HMA): Leveraging SSDs as memory

Patented Hybrid Memory ArchitectureTM (HMA) places data on SSD and indexes only in DRAM
Our patented Hybrid Memory Architecture (HMA) technology is the cornerstone of the vertical scaling strategy. This approach utilizes the direct random read access available on solid-state drives (SSDs) to provide sub-millisecond reads and utilizes a log-structured writing process to work around write leveling issues to provide sub-millisecond writes. This is achieved through software written in the C programming language, bypassing the operating system’s file system when necessary to achieve predictable low latency.
Additionally, writes and reads are performed in a highly parallelized way using multiple SSD drives, enabling read and write operations to be executed with both high throughput and low latency.
To provide real-time, sub-millisecond reads and writes uniformly, other database systems must store all data in main memory (DRAM). This results in storing a relatively small amount of real-time data per node (typically, a maximum limit for DRAM is 1TB per node)—this results in huge cluster sizes, often of hundreds or even thousands of nodes. Because HMA enables our system to store real-time data on SSDs and directly access it from there, and there can be a lot of SSD storage capacity per node (up to 100TB using many drives), Aerospike cluster sizes are typically ten times (or more) lower than the cluster sizes of other systems. The trick is to keep parallelism going without significant performance impact on both the processing and networking sides.
Because HMA optimizes SSDs for storage, high-throughput, and low-latency operations, the technology enables heavy read loads while handling heavy write loads.<
One of the major advantages of HMA is its ability to cut huge costs for large-scale application deployments for customers. Through leveraging SSDs as a real-time data store, our system enables customers to drastically cut their total cost of ownership (TCO) by up to 80 percent or more. This results in both huge savings and simplifying ongoing operations (since there are fewer servers to handle).
Scaling up transactions per node
Accessing data stored on SSD in real-time increases the amount of data available for real-time access per node by ten times or more. This means that each node needs to be able to run ten times or more transactions per second. So, we designed a system that is capable of doing that.
CPU and NUMA pinning: Maximizing processing efficiency
Aerospike employs advanced techniques like CPU pinning and NUMA pinning to maximize processing efficiency. By aligning specific processes or threads to specific CPUs or CPU cores (or vCPUs) and ensuring that memory used by these processes is as close as possible to the CPU accessing it, the system minimizes latency and provides very high throughput of transactions per second for each single node. This approach takes full advantage of modern multi-core processors, ensuring that each core is utilized effectively and efficiently.
Network to CPU alignment: Streamlining data flow
Aligning network processing with CPU processing is another critical aspect of scaling up transactions per node. The system ensures that network requests are efficiently routed to the appropriate CPU by using parallel network queues and alignment between network requests to specific CPU threads where applicable. This alignment increases the efficiency of network processing, eliminates bottlenecks under heavy load conditions, and ensures that network operations do not become a limiting factor in database performance.
At Aerospike, we have continuously integrated hardware technological advancements to enhance the system’s vertical scaling capabilities. Innovations in SSD technology, such as PCIe and NVMe, offer faster data access speeds and higher throughput. The database system’s architecture is designed to take full advantage of these advancements, ensuring that our database software can handle increasingly large volumes of data, overall and per node, without sacrificing performance.
When it comes to vertical scaling, our approach is about maximizing the potential of each node. By combining hardware optimizations with intelligent software design, we ensure that each node is a powerhouse of data processing, capable of handling the demands of modern applications and big data. This strategy also promises even greater performance and efficiency in the future as we continue to leverage subsequent advancements in hardware capabilities from device manufacturers and the major cloud providers.
Most importantly, our vertical scaling approach helps customers save considerable amounts of money by cutting the number of nodes (or instances) by up to 80% compared to every other in-memory database system while maintaining the predictable real-time performance, high scale, and high availability requirements needed by real-time applications.
Storage tiering: Optimizing data storage
Our approach to storage tiering involves supporting a range of storage media, from DRAM to NVMe SSDs, each chosen for its specific performance, storage capacity, and cost characteristics. Data in a single cluster can be stored in separate namespaces that can be mapped to different storage configurations like, for example, in-memory (data and indexes in DRAM), hybrid memory (indexes in DRAM, data in flash) or in-flash (data and indexes on SSD) configurations.
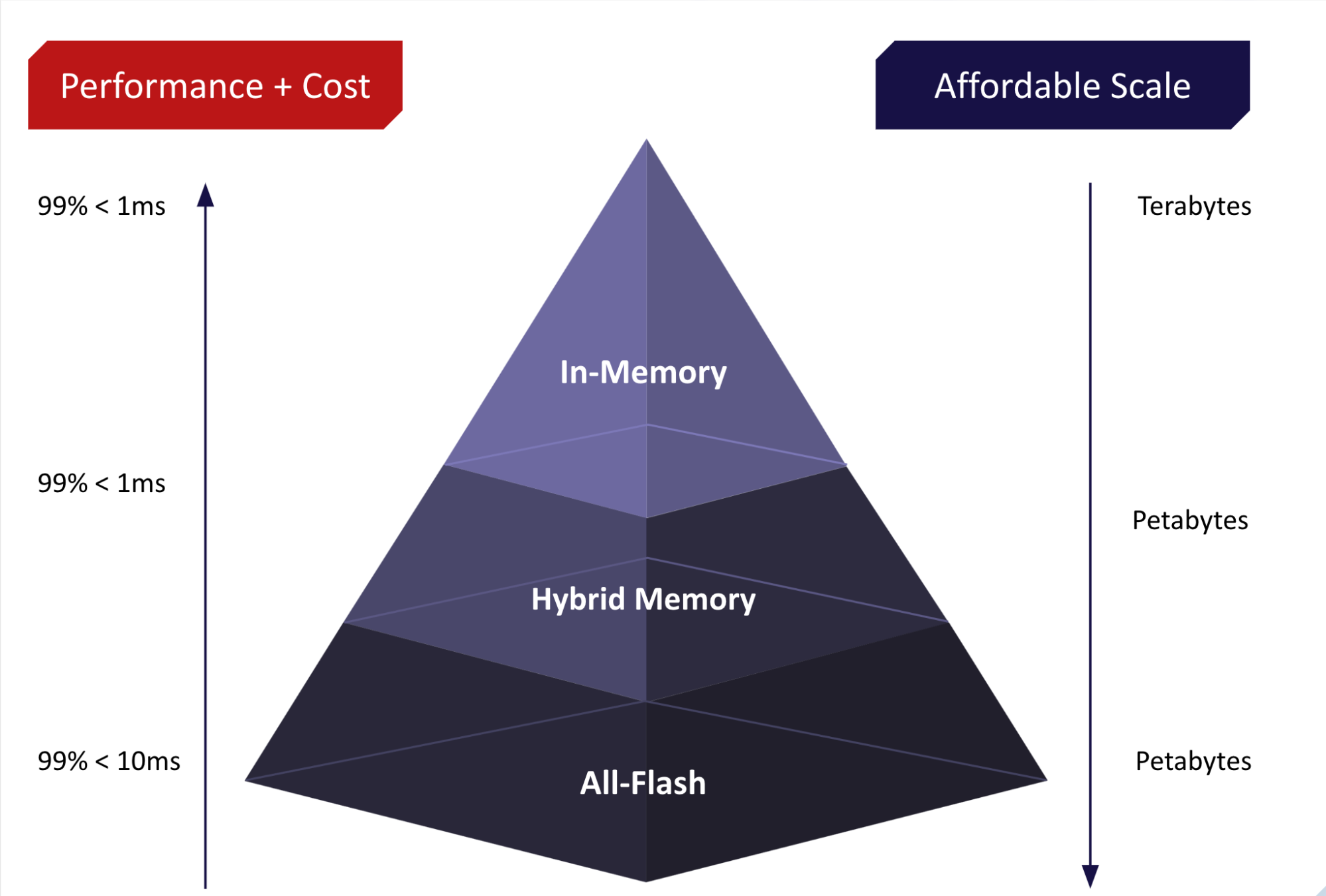
SLAs versus scale
The type of media chosen often depends on the amount of data in the system and the performance and availability service level agreements (SLAs) required to support the relevant business application. The database enables optimizing between various storage media levels to get the best price/performance required for specific application requirements.
For applications with small amounts of data (less than a terabyte) requiring real-time performance, one can use the in-memory configuration and store all data and indexes in DRAM to provide the best read/write performance.
For applications with large amounts of data (multiple terabytes to petabytes) requiring real-time read/write performance, one can use the hybrid-memory configuration, storing data in SSD while keeping indexes in DRAM – this will provide sub-millisecond read and write latencies for heavy concurrent read and write throughput (multiple millions of transactions per second).
For applications with large amounts of data (multiple terabytes to petabytes), a relatively large index size that makes the cost of storing indexes in flash substantially less than storing them in memory, does not require sub-millisecond latencies and does not have enormous write throughput. One can store the data and the indexes in SSD.
There will be performance differences between the options mentioned above. Still, these need to be evaluated with the cost benefits of storing data and indexes on SSDs, resulting in an almost 80% reduction in node count and total cost of operation (TCO). This approach allows data to be stored on the most suitable storage tier, balancing performance, capacity, and cost. Thus, the performance and availability SLAs are maintained without causing an undue increase in deployment cost as the database’s data volume grows.
Strong consistency and maximizing availability
The challenge of implementing strong consistency in a distributed system is finding a way to maintain high performance and a fair amount of availability. Our system does this by basing the algorithm on the list of cluster nodes called the roster.
Roster-based strong consistency
A roster is the list of nodes that form a cluster. The roster defines what a fully-formed cluster looks like in steady state. Each node knows it’s part of a roster, and it knows all other nodes in the roster. Hence, when one or more nodes are not present for any reason, the remaining nodes immediately know which node (or nodes) is missing. With this information, the nodes define rules for deciding when a particular data item is consistent and available. These rules (described in a VLDB 2023 paper) determine how data is replicated and synchronized across different nodes in the cluster and ensure the availability of all data in the strongly consistent database system in common failure situations. For example:
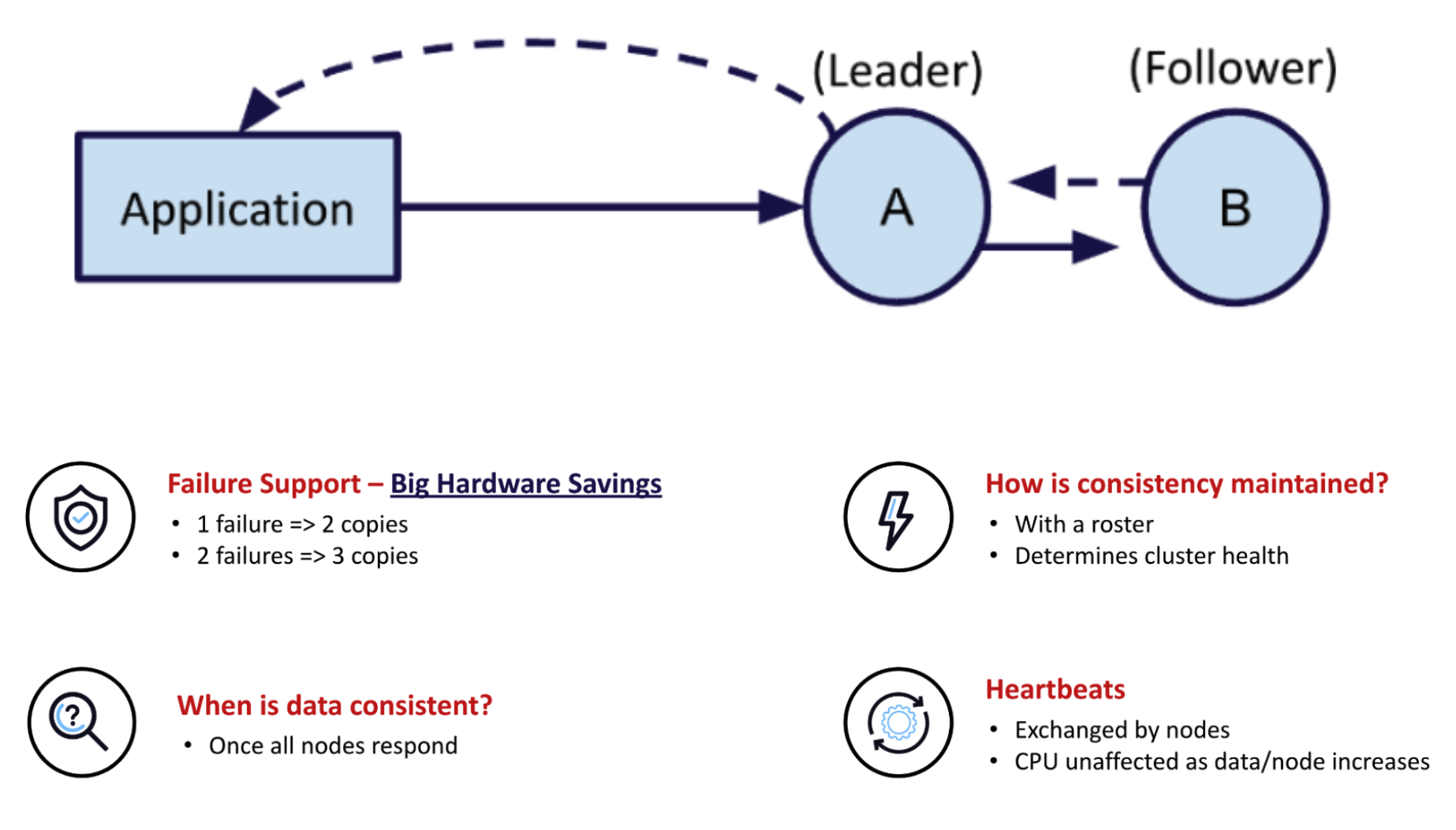
Aerospike consensus is non-quorum, roster-based
The scheme uses synchronous replication to ensure immediate consistency. In our model, a read operation needs to access only one copy of the data to retrieve the latest version. In contrast, a write operation is replicated across all nodes shared by the specific partition to which that piece of data is written. By ensuring that all writes are synchronously replicated across multiple nodes, Aerospike guarantees that no data is lost, even in the event of a node failure or network issue. Read operations in geo-distributed scenarios are sent to the node closest to the client initiating the read, thus minimizing read latency.
Thus, our roster-based scheme uses the performance headroom created by efficient vertical scaling and horizontal scaling algorithms described earlier to deliver significantly higher performance and availability than is otherwise possible in a strongly consistent distributed database system.
For example, one key result is that the distributed database can preserve strong consistency using two copies. This also results in a highly efficient implementation of strong consistency compared to other consensus-based algorithms (e.g., Raft), which require a minimum of three copies for strong consistency. In our roster-based scheme, additional copies may be generated during failure situations. The extra copies are removed once the failure situation has been resolved.
Note that network partitions (i.e., split-brain scenarios) and failures are inevitable. Within the confines of the CAP theorem, a strongly consistent distributed system cannot have strong consistency and still provide 100% high availability for any type of split-brain scenario. Our roster-based algorithms maximize system availability during many common failure scenarios but are not a panacea for arbitrarily complex network and node failures.
Maintaining read performance with strong consistency
Our vertical scaling algorithms provide very predictable high performance. To maintain that performance for reads in strong consistency configurations, Aerospike supports two types of read consistency levels – linearizable or sequential – and the read consistency level can be chosen on every application read operation. Linearizable is the stricter model; reads are slower yet can never return stale data. Sequential is the more relaxed strong consistency model; reads are typically as fast as in a system without strong consistency configuration but may return slightly stale committed data in rare failure situations.
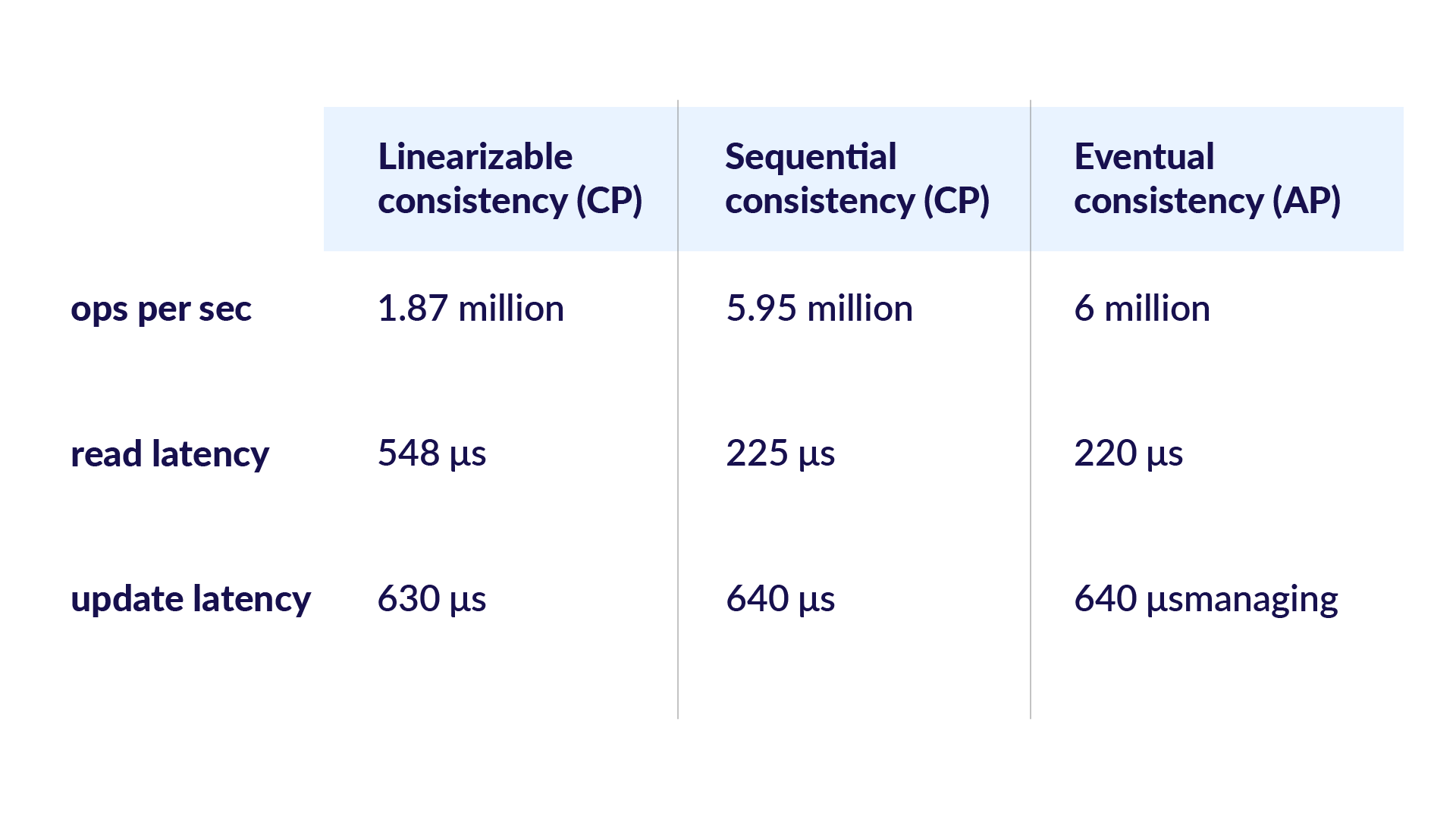
In performance tests, we have demonstrated that for replication factor 2, there is no difference in performance (both throughput and latency) between eventual consistency (AP Mode) and sequential consistency. As expected, there is a falloff in throughput and latency for running with linearizable consistency. However, even in those situations, note that the system can still perform over a million transactions per second at sub-millisecond latency on a single node.
The table below illustrates Aerospike benchmark results of a 5-node cluster operating at different levels of consistency. These were run with 500 million keys, replication factor 2. Aerospike was configured for in-memory with persistence. Note that linearizable and sequential consistency are two forms of strong consistency, i.e., no data loss is possible in either of these settings. On rare occasions, it is possible for stale reads of data committed earlier to occur in sequential consistency configuration. No such possibility exists in the case of linearizable consistency.
Table: Performance comparison of various consistency settings
Geo-distributed active-active systems
Strong consistency is crucial for applications that require up-to-date data across all nodes, regardless of their geographical location. A common case is for small cash consumer payments between individuals; once a payment from one person to another has been successfully processed, this state needs to be maintained forever. A common requirement in these situations is to have two or more components of a single database system based in geographically distributed sites (thousands of miles apart) to jointly commit the transaction, i.e., once a transaction is committed, this transactional state is available on all the geographically distributed sites.
Managing transactions over geographically dispersed locations poses unique challenges. Given the fact that data operations routinely need to span continents, maintaining data integrity and consistency across various regions while balancing performance and availability is crucial.
This section delves into how geo-distributed transactions are effectively handled by the roster-based strong consistency algorithms, focusing on the technologies and strategies that ensure seamless operation across distances.
A modern geo-distributed database should support both synchronous and asynchronous active-active systems. This dual approach offers flexibility in how data is replicated and accessed across different regions. In a synchronous system, transactions are immediately replicated across all nodes, ensuring real-time, immediate strong consistency. At any given moment, each piece of data is identical across all replicas that share it (or else the write operation is not committed). In contrast, an asynchronous system allows for some delay in replication, which can be beneficial in scenarios where strong consistency is not a critical requirement. Aerospike supports both these models; the strongly consistent synchronous active-active offering is named multi-site clustering (MSC), and the asynchronous active-active offering is named Cross Datacenter Replication (XDR). This flexibility allows Aerospike to cater to a wide range of use cases and performance needs. See our recent blog on geo-distribution strategies to learn more about these configurations.
To summarize, managing geo-distributed transactions is about striking a balance between consistency, availability, and performance. By utilizing a roster-based approach, employing a read-one, write-all scheme, offering tunable consistency, supporting both synchronous and asynchronous systems, and pushing the availability envelope for a distributed, strongly consistent cluster, our database technology ensures efficient and effective handling of transactions across the globe. These strategies are pivotal in maintaining data integrity and system resilience, which are essential in today’s interconnected world.
Embracing the future with modern distributed databases
As we’ve journeyed through the essentials of modern distributed databases – from scaling out and up, implementing strong consistency with high performance and availability, and mastering geo-distributed transactions – it’s clear that the landscape of data management is evolving rapidly. These pillars are not just technological advancements; they represent a shift in how we approach data challenges in an increasingly interconnected world.
For businesses looking to stay ahead, implementing a modern distributed database is no longer just an option – it’s a necessity. It’s about embracing a system that scales effortlessly, handles data with precision across the globe, and processes information at unparalleled speeds. This is where innovation meets practicality, ensuring that your data infrastructure is not only robust but also intelligent and future-proof.
Keep reading

Mar 18, 2026
How Myntra built a GenAI shopping assistant that remembers, recommends, and responds in milliseconds

Mar 12, 2026
How Unity replaced Redis to scale its ad platform to 10 million ops

Mar 10, 2026
AKO 4.2: The evolution of production-grade Aerospike on Kubernetes
Mar 3, 2026
How Aerospike and ScyllaDB behave under production stress



