Introduction to shared-nothing architecture
Compare three classic distributed models to grasp their resource-sharing trade-offs, contention risks, and scalability limits.

Shared-nothing architecture is a distributed computing design in which each node in a system is independent, with no shared memory or shared disk storage between nodes.
The term was introduced in the 1980s by computer scientist Michael Stonebraker, who described a database architecture in which neither memory nor storage is shared between processors. Early implementations of the concept appeared even before the term was coined. For example, Tandem Computers’ NonStop systems (circa 1976) were essentially shared-nothing machines focused on fault tolerance, and the first commercial shared-nothing database, Teradata, was released in 1983. Stonebraker’s 1986 paper “The Case for Shared Nothing” articulated the benefits of this approach for parallel database management, contrasting it with shared-memory and shared-disk designs of that era.
In a shared-nothing system, each node or server owns its own CPU, memory, and disk and handles a portion of the overall workload or dataset. All inter-node coordination happens via a network; there is no centralized resource or controller that all nodes depend on. The intent of this architecture is to eliminate any contention or competition for resources among nodes, because no two nodes ever try to read or write the same memory or disk data at the same time. As a result, each incoming request or transaction is satisfied by one node, without requiring cross-node locking or synchronization in the critical path.
This model contrasts with older “shared-everything” designs where multiple nodes might access the same data at the same time, leading to conflicts and bottlenecks. By avoiding shared resources, a shared-nothing architecture removes single points of failure and bottlenecks, making large systems more reliable and scalable.
When one node fails, it does not bring down others, and the system keeps running, which is essential for fault-tolerant, highly available services. Similarly, a shared-nothing system is typically scaled out by adding more nodes, because there is no central disk or memory controller that bottlenecks as the cluster grows. This ability to increase capacity and throughput linearly by adding commodity servers has made the shared-nothing approach especially attractive in the era of big data and cloud computing, where systems expand on demand across distributed infrastructure.
Shared-nothing vs. other architecture models
To better understand shared-nothing architecture, here’s how it compares with alternative approaches to resource sharing in multi-node systems. The three classical models in distributed system design are often described as shared-memory, shared-disk, and shared-nothing (sometimes a fourth called shared-everything, which essentially means no partitioning at all). These differ in how they allocate or share memory and storage among multiple processing nodes.
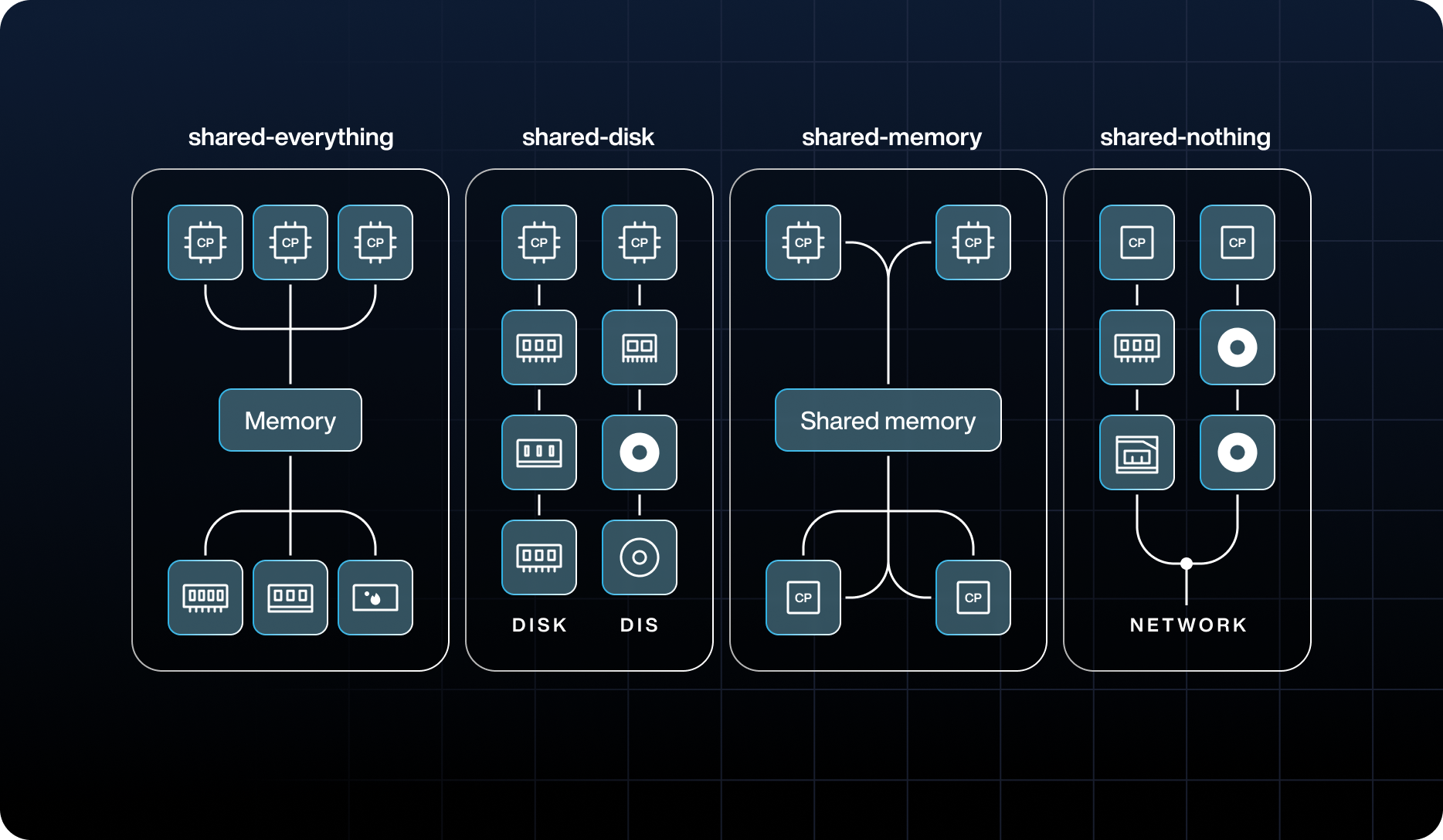
Shared-everything architecture
In a shared-everything, sometimes called tightly coupled, system, all nodes share both memory and storage. This typically implies one memory space and a data store accessible by all processors. Such an architecture uses resources most efficiently under certain workloads because any processor can work on any data. However, as the number of processors grows, contention becomes a problem. Multiple processors or nodes may attempt to update the same data or use the same memory bus simultaneously, requiring complex locking mechanisms and leading to diminishing returns in performance.
An example of a shared-everything system is a large symmetric multiprocessing (SMP) machine or certain clustered databases where all nodes use a shared memory via an interconnect. The upside is simplified data management, because all data is in one place, but the downside is poor scalability beyond a point, due to the overhead of synchronization. In practice, shared-everything architectures are prone to bottlenecks because as soon as you have many processors, the pool of resources, especially memory, is available only to a limited number of threads at a time. This model also couples the fate of nodes: if one node corrupts or locks a shared resource, it affects the whole system.
Shared-disk architecture (shared-storage)
In a shared-disk design, each node has its own private memory and processes, but all nodes share a common disk or storage subsystem. This is the model used by some database clustering technologies, such as Oracle RAC. The benefit of shared-disk is that every node can see the entire dataset on the shared storage, which simplifies data management because there’s no need to partition the data manually. However, the shared storage becomes a central point of contention and potential failure. All read/write operations from any node go through the same disk system, so disk I/O becomes a bottleneck as you add nodes. Moreover, the shared disk or interconnect is a single point of failure; if it fails, the whole system is affected.
In terms of scalability, shared-disk systems usually do not scale as well as shared-nothing systems because throughput is limited by the throughput of the shared storage device. Avoiding conflicting writes also requires coordination: nodes use locking or a consensus mechanism so two nodes don’t try to update the same part of the disk at the same time. This overhead limits performance and scalability compared with shared-nothing.
By contrast, a shared-nothing architecture avoids disk contention because each node has its own disk, so there is no I/O bottleneck. This means a shared-nothing cluster keeps operating even if one node’s storage fails, because other nodes’ storage is independent. Adding more nodes adds more aggregate I/O capacity linearly. The tradeoff is that data needs to be partitioned across those independent disks, which makes data distribution more complex and requires design.
Shared-memory architecture
In a shared-memory model, also known as shared-RAM or tightly coupled multiprocessor systems, multiple processors or nodes share a large memory space, but they might have separate disks (or no disks, if purely an in-memory system). This model is common in high-performance computing systems or multi-core processors, where all cores use the same RAM.
Shared-memory architectures offer faster communication between processors than shared-disk, because memory is faster than disk, and make programming simpler because any processor reads/writes any data in memory. However, contention is still a challenge; as more processors are added, they compete for the memory bus or interconnect, and the overhead of maintaining cache coherency and synchronization increases.
The overall system is limited in scalability by the throughput of the memory system. In contrast, a shared-nothing architecture assigns dedicated memory to each node, avoiding memory access conflicts between nodes. Each node in a shared-nothing system works only with its own local memory, which reduces latency and contention because no global memory arbitration is needed. This independence not only makes performance more predictable but also makes it more fault-tolerant; if one node’s memory fails or gets corrupted, it doesn’t affect others. Essentially, shared-nothing trades the convenience of a single memory space for the ability to scale without hitting a memory bottleneck.
Key characteristics of shared-nothing systems
Shared-nothing architecture has several defining characteristics that distinguish it from other models. These characteristics are fundamental design principles that any true shared-nothing architecture system will exhibit:
Independence of each node
In a shared-nothing system, each node or server operates independently of others. A node has its own local CPU, RAM, and disk and does not share these with any other node. All communication between nodes happens via messaging over a network; they don’t share memory addresses or disk data structures. This independence means each node performs its tasks without waiting on locks or access to a common resource. It also means any failure is localized; if one node crashes or loses its disk, it doesn’t corrupt another node’s memory or disk. Node independence is the cornerstone of shared-nothing design, providing the system’s strong fault isolation and predictable performance, because each node owns certain resources and data.
Horizontal scalability
Shared-nothing architectures excel at horizontal scaling, meaning you can grow the system by adding more nodes rather than a larger machine. Because there is no bottleneck, adding a node brings with it additional CPU power, memory, and storage that all increase the system’s capacity in parallel. The architecture accommodates more traffic or data by plugging in additional servers, with minimal changes to the overall setup. Each new node carries its share of the workload by taking on a partition of the data or a subset of queries.
In an ideal shared-nothing system, doubling the number of nodes nearly doubles throughput, a property known as linear scalability. This is an advantage for web-scale systems and big data platforms, where one can start with a small cluster and expand incrementally as demand grows. The ability to scale incrementally not only provides flexibility but also cost-effectiveness, because organizations “pay as they grow,” adding commodity hardware instead of investing in extremely powerful nodes up front.
Fault isolation and resilience
Because each node in a shared-nothing architecture is self-sufficient, the system provides fault isolation. If one node experiences a hardware fault, software crash, or needs to be taken down for maintenance, its absence or malfunction does not incapacitate the others. The failed node’s portion of data or workload gets taken over by surviving nodes (assuming data is replicated or the workload is redistributed), so the overall service keeps running; perhaps not as well, but it’s still up. This characteristic makes it more reliable and available. The system has no single point of failure. In practice, shared-nothing clusters are often designed with redundancy, or multiple replicas of data on different nodes, so that when one node fails, another has a copy of its data to serve requests, keeping the system up. Fault isolation also makes maintenance simpler; upgrade or reboot one node at a time while others keep the service up, resulting in non-disruptive upgrades in many cases. This is one of the reasons shared-nothing designs are popular for systems that need to be available all the time.
Data partitioning or sharding
To make each node independent and avoid sharing, a shared-nothing system partitions the dataset across nodes. Typically, data is divided into disjoint subsets often called shards or partitions, and each node is responsible for one or more shards. For example, a distributed database might hash keys to assign each record to a particular node, or an analytics platform might split data by date ranges or other criteria. Partitioning means each piece of data is available on one node as its primary location, so any transaction goes to the node that owns the required data.
Effective data partitioning is important; it should distribute the workload evenly to prevent hotspots, where one node is heavily loaded while others idle, and reduce cross-node interactions. In practice, many shared-nothing systems use consistent hashing or range partitioning to assign data to nodes, and some allow re-partitioning on the fly as nodes join or leave. Data partitioning means that developers and the system need to know where data is. A query that needs data from multiple shards might need to retrieve and combine results from several nodes, which is less efficient than a query that hits only one node. Good partitioning schemes aim to localize most operations to one node.
Overall, partitioning or sharding is a fundamental aspect of shared-nothing architecture that provides parallelism and scalability, but requires more complex data management.
Parallel and distributed processing
Shared-nothing architectures support parallel processing because each node works on its own tasks simultaneously on its portion of data. With the dataset spread across multiple machines, operations can be divided so each machine processes its shard in parallel with the others. This makes reading and writing faster, and is especially beneficial for read-heavy analytic queries or large batch jobs.
For instance, a large database query can be broken into sub-queries that run on each node against its local data, and partial results are then aggregated. This concurrent processing is much faster than having one node handle everything sequentially. Even in online transaction processing, if transactions pertain to different data shards, they run at the same time on different nodes without contending. As a result, shared-nothing systems often see performance improve with cluster size for appropriate workloads. This happens because there’s so little contention; because nodes don’t lock each other’s data, they operate in parallel. This characteristic is used in many big data processing frameworks like MapReduce and Spark, which distribute tasks across worker nodes that do not share state.
However, it’s worth noting that achieving near-linear performance gains requires that the workload be partitionable and that the system reduces communication overhead between nodes. Still, the ability to process large data sets in parallel is a hallmark of shared-nothing architecture, making it suitable for high-volume transaction systems and massive-scale analytics.
Advantages of shared-nothing architecture
Given the characteristics above, shared-nothing systems offer several advantages for certain classes of applications. These advantages have driven its adoption in many of today’s distributed systems:
Scalability and performance efficiency
A primary advantage of shared-nothing architecture is its scalability. Because each node is self-contained, scale out the system simply by adding more nodes to handle increased load or larger data volumes. There is no need for a high-end SMP machine; instead, add to clusters of commodity hardware incrementally. As load grows, add nodes to share the workload, and the system continues to run and grow without a major redesign. This scaling is close to linear in ideal cases, meaning double the nodes almost double the throughput, because no centralized resource bottlenecks the system’s throughput.
Alongside scalability comes performance efficiency. In a shared-nothing design, there is no contention for shared resources such as memory or disk, so each node uses its CPU and I/O for its own tasks without interference. This often leads to faster processing times for a given workload compared with architectures where nodes compete for the same resource. For example, a query done by one node’s local data executes quickly without waiting on locks or network storage. Evenly distributed operations benefit from parallelism.
Fault tolerance and reliability
Another benefit of shared-nothing systems is their fault tolerance. Because no resources are shared, the failure of any node is isolated to that node alone; it does not crash the entire system. The rest of the cluster keeps running, and in a redundant system, data on the failed node will be available on others via replication, so users may not even notice the failure beyond perhaps a slight performance drop. This property makes the system reliable and available; shared-nothing clusters can be designed with no single points of failure. Even components such as cluster coordination are often distributed among nodes to avoid a single brain that could take everything down if it failed.
Node independence also means you can maintain or upgrade one node at a time, for non-disruptive upgrades that improve uptime. Additionally, if the network connecting nodes is robust, a shared-nothing system survives failures such as an entire rack or data center going offline, with a copy of the data on nodes in another rack or data center keeping things running. In fact, geo-distributed shared-nothing clusters underpin high-availability designs; even if a whole site fails, the system keeps running. By keeping each node autonomous, a shared-nothing architecture prevents a hardware or software fault from cascading. This reliability is important for applications requiring continuous service, such as financial platforms and critical web infrastructure, and it’s one of the reasons such architectures are popular in these domains.
Cost-effectiveness and resource optimization
Shared-nothing architectures tend to be cost-effective, especially when scaling to large sizes. They are typically built using commodity hardware of standard servers rather than a few specialized, high-end machines. Because you can incrementally add nodes, organizations start small and add capacity as needed, aligning costs with growth instead of making a huge upfront investment. This pay-as-you-grow approach avoids the expense of over-provisioned systems. Moreover, with each node using its own resources, resources are used efficiently; you don’t have unused central storage or idle CPUs waiting for access to a shared disk.
Each node’s CPU, memory, and disk are used for its portion of work. There is little risk of one big resource sitting as an idle bottleneck; instead, work and resources scale together. Also, removing the need for a fancy shared storage fabric or large shared-memory machines cuts down infrastructure costs. Commodity clusters running on standard Ethernet and local disks are relatively cheap and easy to replace or upgrade.
In many cases, the operational model of shared-nothing by adding more small servers also aligns well with cloud environments, where you can spin up additional instances on demand. Additionally, no expensive high-end SMP or mainframe is required; a cluster of inexpensive nodes outperforms a monolithic server through parallelism.
All of this makes shared-nothing architecture an economically attractive choice for large-scale systems. Resource optimization is also about performance per cost; because each node works independently, you can tune each to run at full capacity, for excellent performance without wasted resources. In summary, shared-nothing designs deliver scalable performance at lower cost with efficient use of distributed resources and avoiding the need for specialized hardware.
Flexibility and maintainability
A more architectural but important advantage of shared-nothing systems is their flexibility and ease of maintenance in certain aspects. Because nodes are decoupled, you have a lot of freedom to configure and evolve the system. You can deploy heterogeneous nodes with different hardware or software versions as long as they follow communication protocols, which allows rolling upgrades and testing new configurations on part of the cluster. Developers can adopt a modular approach: different services or data partitions run on different nodes, supporting microservices or polyglot persistence patterns where each node or shard might be optimized for a subset of data or queries. Also, from a DevOps perspective, maintenance is simpler because you can restart or replace one node at a time without a full shutdown. Each node’s software and hardware can be upgraded in isolation while the system remains available, which reduces downtime and operational risk.
Shared-nothing also allows independent scaling of different parts of the system. For instance, if one kind of data or service gets more load, add nodes specifically for that shard or service, without affecting others. The independence of components fosters a clean separation of concerns and often simpler troubleshooting because a problem can often be traced to an individual node rather than an issue in a global shared resource. All these factors mean shared-nothing architectures are easier to manage and evolve over time.
Be aware, though, that benefits such as scalability, fault tolerance, and cost efficiency require proper system design. A badly designed shared-nothing system could fail to balance load or might suffer bottlenecks such as network saturation. Assuming good design, however, the shared-nothing approach is a powerful one, which is why it has been widely adopted in today’s distributed systems.
Aerospike’s shared-nothing architecture
Aerospike is built on shared-nothing architecture. Aerospike was designed to be a high-scale operational database, and its architecture follows the classic shared-nothing approach. An Aerospike database cluster has several commodity server nodes, each equipped with its own CPU, RAM, and SSD or HDD storage, and these nodes are connected via a standard TCP/IP network. No node shares memory or disk with another; every Aerospike node manages its portion of the data using local resources, embodying the shared-nothing principle. This means Aerospike has no primary node or central coordinator, which could become a bottleneck; all nodes are peers and coordinate via network protocols such as gossip heartbeats to maintain the cluster state. In fact, Aerospike’s clustering is “masterless” in normal operation: there isn’t one node through which all requests funnel; instead, the client library directs each read/write request to the appropriate node that owns the relevant data partition, typically in a single network hop.
An Aerospike cluster partitions the data using hashing: the key space is divided into a fixed number of partitions, and those partitions are distributed across the nodes. Each node is responsible for a subset of partitions, both primary copies and secondary replica copies. This is analogous to sharding, and it’s done by Aerospike’s “distribution layer.” When you add or remove a node from an Aerospike cluster, the system rebalances partition ownership among nodes with an algorithm that reduces data movement.
Notably, Aerospike’s partitioning and cluster management are algorithmic and masterless; it doesn’t require manual sharding configuration or a central lookup service. Nodes agree on the cluster membership and partition map through a gossip protocol based on Paxos. The cluster maintains a shared understanding of which node owns which partition at any given time. This approach epitomizes shared-nothing: metadata about the cluster is distributed, and each node makes independent decisions about the data it manages, coordinating only to the extent needed to keep the cluster consistent.
Because of its shared-nothing foundation, Aerospike has many of the advantages of shared-nothing architecture: linear scalability, high availability, and fault tolerance. Aerospike documentation emphasizes that the system is designed to scale linearly with additional nodes while reliably storing terabytes to petabytes of data. Benchmarks have shown that as you add nodes, throughput increases roughly proportionally, which is a result of the shared-nothing design removing bottlenecks. Also, Aerospike’s architecture has no single point of failure; there is no single master that, if lost, would halt the cluster, and there is no shared disk whose failure would bring the database down. Each node is redundant in the sense that critical data on one node is replicated to other nodes, configurable by a replication factor. If a node fails or is taken offline, the cluster detects it via heartbeat messages and rebalances the data partitions that node was responsible for, promoting replica partitions on surviving nodes to be new primaries.
The Aerospike client also becomes aware of the cluster change because the client tracks the cluster map and redirects subsequent requests to the appropriate new nodes. This means that even during node failures or additions, the system continues serving requests with little interruption. This is the high availability behavior expected from a shared-nothing, self-healing cluster.
Aerospike’s use of shared-nothing also shows up in how it handles performance and cost. Because each node in an Aerospike cluster manages its data locally, often storing indexes in RAM and data on SSDs, it offers low latency for read/write operations because there is no extra network hop to fetch data from a central storage location; the node receiving the request often has the data on its own disk. Aerospike clients know the partition-to-node mapping, so a client will send a given key’s request to the node that owns that key, typically resulting in single-hop data access. This efficient request routing, avoiding proxies or coordinators, is a benefit of the shared-nothing philosophy of having data ownership and request handling in the same place.
Additionally, Aerospike’s ability to mix in-memory and on-disk storage for different sets of data, and its optimized use of SSDs, means each node does a lot of work independently; it can handle millions of transactions per second per server on flash. To scale performance, add more nodes; Aerospike partitions more finely and distributes the load for high throughput. This is why Aerospike is often praised for its near-linear scaling and high performance on relatively small clusters of commodity hardware.
From a cost and operations perspective, Aerospike benefits from shared-nothing by running effectively on fewer nodes to handle a given workload compared with some other systems. Documentation notes that Aerospike often runs on a smaller number of nodes than other databases for the same throughput, which keeps costs down, while still providing resilience. The shared-nothing design, combined with efficient engineering, means each Aerospike node offers higher performance with techniques such as multi-threading and direct device I/O before you need to scale out. But when you do need to expand, it’s straightforward: Add a node to the cluster and the cluster rebalances; throughput and performance scale linearly as you add capacity. This operational simplicity of adding or removing nodes and letting the cluster self-manage is another hallmark of a well-implemented shared-nothing system. Aerospike’s cluster reconfigures and migrates data when nodes join or leave, requiring little manual intervention. This self-management is possible because there is no centralized state that an operator has to tweak; distributed algorithms handle it.
Aerospike’s design illustrates how shared-nothing principles of independent nodes, partitioned data, and no shared storage result in a system that scales to large workloads, stays up around the clock, and requires little manual sharding or failover intervention. Aerospike’s use of shared-nothing is how it offers features such as zero-downtime upgrades, self-healing clusters, and immediate failover of transactions; these are from having no single points of control or contention. With a shared-nothing architecture, Aerospike ensures that as demand grows, the database grows with it smoothly, and that the failure of any one component will not bring the whole system down. This alignment of shared-nothing theory with Aerospike’s implementation practice shows why shared-nothing architectures are so important in today’s landscape of distributed systems.