Architecture overview
![]()
Aerospike is a distributed, scalable database. The architecture has three key objectives:
- Create a flexible, scalable platform for web-scale applications.
- Provide the robustness and reliability (as in ACID) expected from traditional databases.
- Provide operational efficiency with minimal manual involvement.
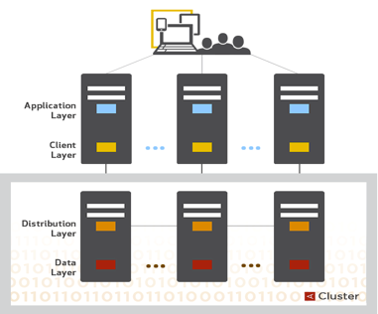
As published in Proceedings of VLDB (Very Large Databases), the Aerospike architecture comprises three layers:
- Client Layer: This cluster-aware layer includes open source client libraries, which implement Aerospike APIs, track nodes, and know where data resides in the cluster.
- Clustering and Data Distribution Layer: This layer manages cluster communications and automates fail-over, replication, Cross-datacenter Replication (XDR), and intelligent re-balancing and data migration.
- Data Storage Layer: This layer reliably stores data in DRAM and Flash for fast retrieval.
Client layer
The Aerospike Smart Client™ is designed for speed. It is implemented as an open source linkable library available in C, C#, Java, Node.js and others (refer to the complete list on the Clients Download page). Developers can contribute new clients or modify existing clients.
The Client layer:
- Implements the Aerospike API, the client-server protocol, and talks directly to the cluster.
- Tracks nodes and knows where data is stored, instantly learning of changes to cluster configuration or when nodes go up or down.
- Implements its own TCP/IP connection pool for efficiency. Also detects transaction failures that have not risen to the level of node failures in the cluster and re-routes those transactions to nodes with copies of the data.
- Transparently sends requests directly to the node with the data and re-tries or re-routes requests as needed (for example, during cluster re-configurations).
This architecture reduces transaction latency, offloads work from the cluster, and eliminates work for the developer. It ensures that applications do not have to restart when nodes are brought up or down. And you don't have to waste time with cluster setup or add cluster management servers or proxies.
Distribution layer
The Aerospike “shared nothing” architecture is designed to reliably store terabytes of data with automatic fail-over, replication, and Cross-Datacenter Replication (XDR). This layer scales linearly.
The Distribution layer is designed to eliminate manual operations with the systematic automation of all cluster management functions. It includes three modules:
- Cluster Management Module: Tracks nodes in the cluster. The key algorithm is a Paxos-based gossip-voting process that determines which nodes are considered part of the cluster. Aerospike implements a special heartbeat (both active and passive) to monitor inter-node connectivity.
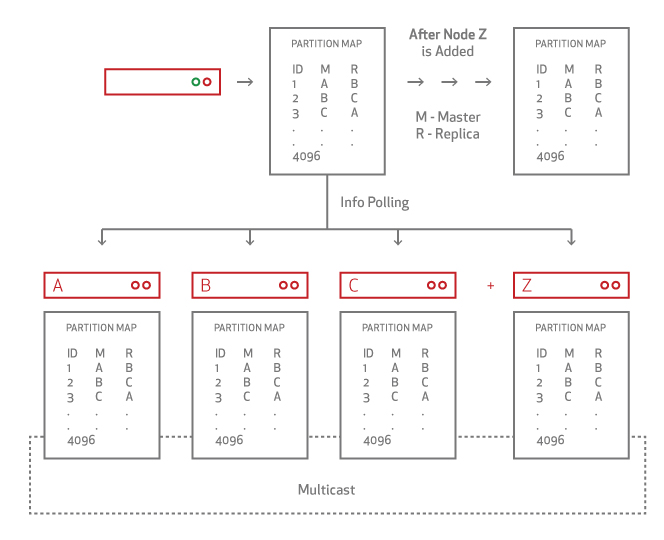
- Data Migration Module: When you add or remove nodes, Aerospike Database cluster membership is ascertained. Each node uses a distributed hash algorithm to divide the primary index space into data slices and assign owners. The Aerospike Data Migration module intelligently balances data distribution across all nodes in the cluster, ensuring that each bit of data replicates across all cluster nodes and datacenters. This operation is specified in the system replication factor configuration.
Division is purely algorithmic. The system scales without a master and eliminates the need for additional configuration as required in a sharded environment.
- Transaction Processing Module: Reads and writes data on request, and provides the consistency and isolation guarantees. This module is responsible for
- Sync/Async Replication: For writes with immediate consistency, it propagates changes to all replicas before committing the data and returning the result to the client.
- Proxy: In rare cases during cluster re-configurations when the Client Layer may be briefly out of date, the Transaction Processing module transparently proxies the request to another node.
- Resolution of Duplicate Data: For clusters recovering from being partitioned (including when restarting nodes), this module resolves any conflicts between different copies of data. The resolution can be based on either the generation count (version) or the last update time.
Once the first is cluster up, you can install additional clusters in other datacenters and setup cross-datacenter replication to ensure that if a datacenter goes down, the remote cluster takes over the workload with minimal or no interruption to users.
Data storage layer
Aerospike is a key-value store with a schemaless data model. Data flows into policy containers, namespaces, which are semantically similar to databases in an RDBMS system. Within a namespace, data is subdivided into sets (RDBMS tables) and records (RDBMS rows). Each record has an indexed key unique in the set, and one or more named bins (RDBMS columns) that hold values associated with the record.
- You do not need to define sets and bins. For maximum flexibility, they can be added at run-time .
- Values in bins are strongly typed, and can include any supported data-type. Bins are not typed, so different records can have the same bin with values of different types.
Indexes, including the primary index and optional secondary indexes, are stored by default in DRAM for ultra-fast access. The primary index can also be configured to be stored in Persistent Memory or on an NVMe flash device. Values can be stored either in DRAM or more cost-effectively on SSDs. You can configure each namespace separately, so small namespaces can take advantage of DRAM and larger ones gain the cost benefits of SSDs.
The Data Layer was designed for speed and to provide a dramatic reduction in hardware costs. It can operate all in-memory, which eliminates the need for a caching layer or it can take advantage of unique optimizations for flash storage. Either way, data is never lost.
In Aerospike:
- 100 million keys only take up 6.4GB. Although keys have no size limitations, each key is efficiently stored in just 64 bytes.
- Native, multi-threaded, multi-core Flash I/O and an Aerospike log structured file system take advantage of low-level SSD read and write patterns. To minimize latency, writes to disk are performed in large blocks. This mechanism bypasses the standard file system, historically tuned to rotational disks.
- The Smart Defragmenter and the Evictor work together to ensure that there is space in DRAM and that data is never lost and is always safely written to disk.
- Smart Defragmenter: Tracks the number of active records in each block and reclaims blocks that fall below a minimum level of use.
- Evictor: Removes expired records and reclaims memory if the system gets beyond a set high-water mark. Expiration times are configured per namespace. Record age is calculated from the last modification. The application can override the default lifetime and specify that a record should never be evicted.
Operating Aerospike
In a conventional (non-distributed) RDBMS, after installing the database software you set up your database schema and create databases and table definitions. The Aerospike Database is quite different.
In distributed databases, data is divided (distributed) between all servers in the cluster. That means you cannot simply log onto a server to access all of your data.
With Aerospike, you create and manage the database:
- By configuring the initial database settings. The Aerospike database is the namespace. When you install Aerospike, each node in the cluster must have each namespace configured to specify how to create and replicate the database. The database is created as soon as you restart your server.
- By performing database operations through your application.
- The database schema is created when your application first references the sets and bins (tables and fields).
- The Aerospike Database is a flex-schema—you don't have to predefine your database schema. For example, to add a new bin (field), your application simply starts storing data in a specified bin. In the Aerospike Database, tasks that might normally be done by a DBA on a command line are done in your application.
- By updating the configuration files as necessary.
- To change namespace parameters, simply update the configuration file, either dynamically without a restart or by restarting the server with a new configuration file.
To provide quality performance and redundancy, plan and configure how many nodes are required (see Capacity Planning).
If you add a node to the cluster or take down a node for upgrading or servicing, the cluster automatically reconfigures. When a node fails, other nodes in the cluster rebalance the workload with minimal impact. See monitoring tools for a list of available monitoring utilities.
Building applications
With a namespace defined, you can use the Aerospike tools to verify that the database is storing data correctly. In production databases, data is distributed over the cluster. To perform database operations, use the Smart Client that instantiates your application. The Smart Client is location-aware and knows how to store and retrieve data without affecting performance.
Aerospike APIs help you build your big data application. See the client guide for your application language.
On application compilation, the Aerospike API libraries are included along with the Smart Client. The Smart Client is a separate thread/process that monitors cluster state to determine data location, which ensures that data is retrieved in a single hop.
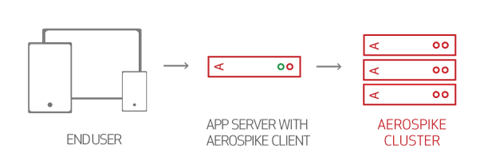
This illustrates how big data applications located on a web server are backed by Aerospike Database clusters, resulting in one-hop operation. The Smart Client allows your application to ignore the data distribution details.
In Aerospike documentation, API and client are interchangeable. Your application integrates the Aerospike API and the Smart Client.