How Aerospike and ScyllaDB behave under production stress
See how Aerospike and ScyllaDB perform at multi-terabyte scale, comparing tail latency and cost using benchmark results. Download the full report today.

As data volumes grow and real-world conditions disrupt ideal assumptions, many databases suffer unpredictable latency spikes, rising costs, and operational fragility driven by cache dependence and non-linear scaling. While ScyllaDB performs well under favorable conditions, its latency and scalability degrade as workloads evolve, whereas Aerospike delivers consistently low latency and true linear scalability at multi-terabyte scale. For long-term user-facing platforms, the key question is whether the database remains predictable, efficient, and resilient as conditions change.
This blog explores some of the findings from the Aerospike vs. ScyllaDB benchmark conducted by McKnight Consulting Group. For a complete analysis, download the benchmark.
The multi-terabyte performance cliff
Modern applications demand databases that can sustain high throughput with predictable, sub-millisecond latency at a multi-terabyte scale. Yet, most architectures exhibit sharp behavioral shifts as data volume increases and workload conditions deteriorate. Three core challenges define this problem space:
1) Cache dependence creates fragile performance
Most high-performance databases achieve impressive benchmark numbers by keeping frequently accessed data in memory. This works elegantly until access patterns change. A product launch shifts user behavior. A machine learning (ML) model introduces new query patterns. Seasonal traffic redistributes the working set. Suddenly, your carefully tuned cache hit rates collapse, and what was once single-digit millisecond latency becomes 20ms, 50ms, or worse at the tail.
The operational reality becomes clear: you're not running a database with predictable performance characteristics. You're running a caching system with a database underneath, and your user experience depends entirely on cache effectiveness. This turns performance management into an ongoing operational risk rather than a solvable engineering problem.
2) Tail latency amplification in modern architectures
Many applications require dozens or even hundreds of database calls to serve a single user interaction; common examples include AI systems, personalization engines, and fraud detection pipelines.
As the number of database requests per interaction increases, the importance of tail latency amplifies. The likelihood that at least one request encounters long-tail latency rises, degrading overall responsiveness. While P99 latency may be a reasonable indicator for applications with simple request paths, it becomes far less meaningful as the number of lookups grows. In these cases, behavior at P999 or even P9999 ultimately determines the user experience.
3) Non-linear degradation under real operating conditions
Databases that perform well under stable conditions often degrade unpredictably as operating realities intrude: storage fills, clusters age, the workload mix shifts between reads and writes, and maintenance events occur. Performance drift isn't catastrophic; it's insidious. Teams compensate by overprovisioning, adding cache layers, and building increasingly complex mitigation strategies. Infrastructure costs rise faster than data volume, and operational complexity becomes a constraint on velocity.
How ScyllaDB approaches these challenges
ScyllaDB positioned itself as a next-generation solution to these problems by reimplementing Cassandra's data model in C++ and adopting a shard-per-core architecture designed to maximize throughput on modern hardware. The promise: Cassandra-like scalability with dramatically improved performance.
In practice, ScyllaDB makes specific architectural tradeoffs that shape its behavior in real-world conditions:
Reliance on internal caching for read performance
ScyllaDB emphasizes its internal cache as the primary mechanism for delivering fast reads. When cache hit rates are high, meaning your working set fits comfortably in memory and access patterns remain stable, this approach delivers strong results. ScyllaDB's documentation and benchmarks often showcase performance under these favorable conditions.
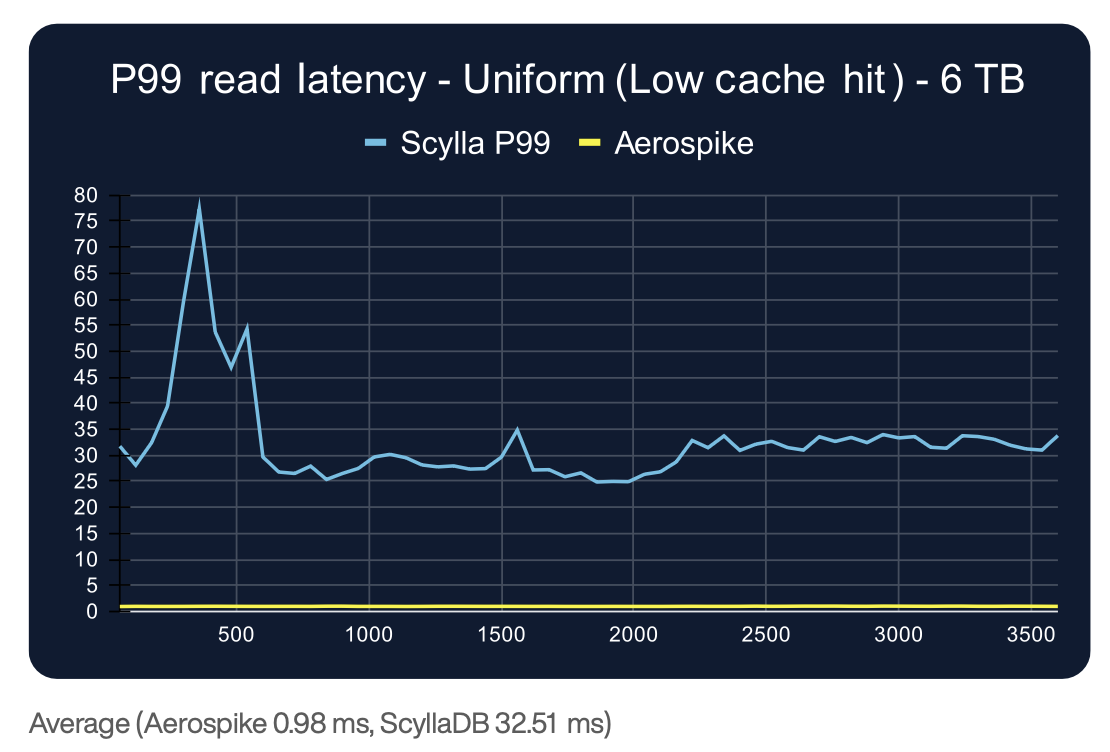
The challenge arises when working sets exceed available memory or when access patterns become volatile. Our recent benchmark made this dependency clear: even with a 50% cache hit rate (which required directing 55% of reads to just 1% of the dataset, a concentration pattern difficult to sustain in most production environments), ScyllaDB's P99 read latency remained in the 15-17ms range. Under a uniform distribution with minimal caching, P99 read latency climbed to 17-32ms due to reduced cache hit rate.
Write optimization at the expense of read predictability
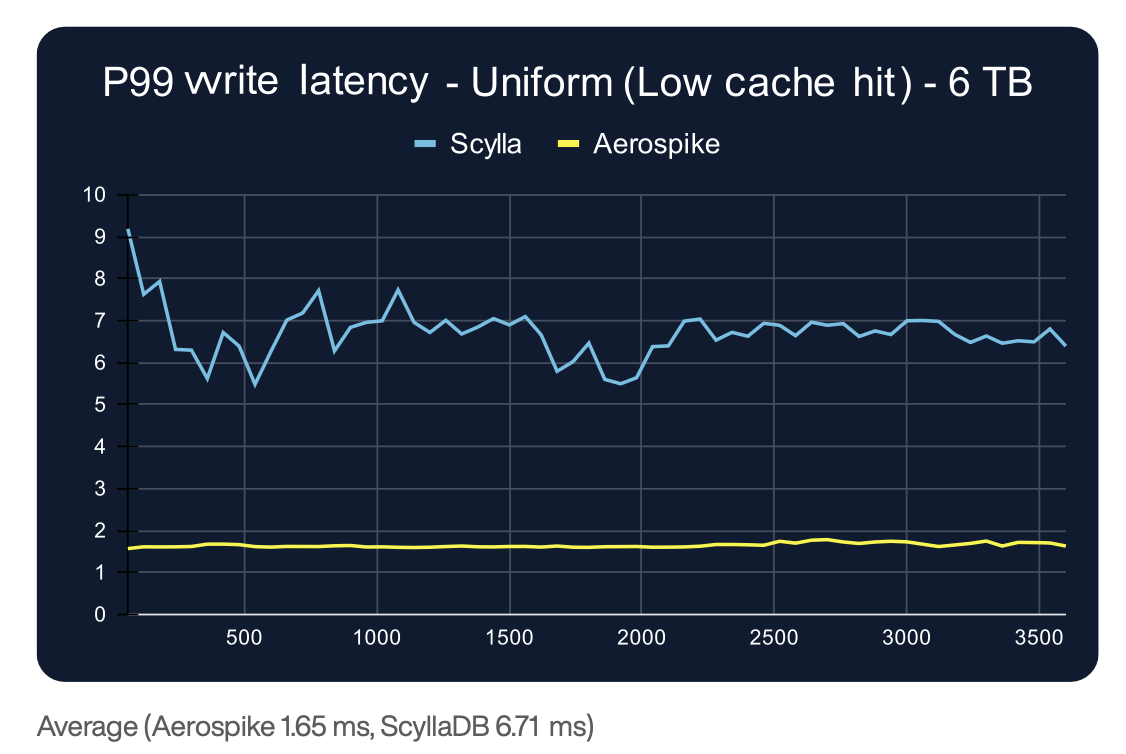
ScyllaDB's architecture delivers notably better write performance than read performance, suggesting optimization decisions that favor write-heavy workloads. In our testing, ScyllaDB's P99 write latency (3.5-6.7ms) was materially lower than its read latency, though it was still several milliseconds slower than competing approaches.
For mixed workloads or read-heavy applications, which make up the majority of user-facing systems, this trade-off becomes consequential. Applications that depend on fast, predictable reads under changing conditions cannot simply optimize for write performance.
Scalability characteristics under increasing load
Predictable linear scaling is crucial for confidently expanding infrastructure as demand grows. When scaling from 3TB to 6TB, ScyllaDB's throughput increased only 1.6× despite doubling infrastructure, and variability spiked to 59.6%. Aerospike's architecture avoids these issues, enabling reliable growth without unpredictable performance drops.
Why Aerospike's architecture eliminates performance cliffs
Where ScyllaDB optimizes for peak throughput under favorable conditions, Aerospike optimizes for predictable behavior under unfavorable conditions. Aerospike was designed from the ground up on a different set of assumptions: that volatility, scale growth, and changing conditions are the baseline reality, not edge cases to be managed through tuning and overprovisioning.
Performance independent of cache hit rate
Unlike databases that rely on caching for speed, Aerospike delivers near-in-memory performance directly from persistent storage through a custom Hybrid Memory Architecture. Data is stored on NVMe SSDs, while indexes and metadata reside in RAM, enabling fast lookups without requiring the entire working set to fit in memory.
The results speak clearly: In our benchmark, Aerospike maintained sub-millisecond P99 read latency (0.92-0.99ms) across all test scenarios, regardless of cache effectiveness. Whether access was uniformly distributed (minimizing any caching benefit) or concentrated (maximizing potential cache hits), Aerospike's latency remained effectively unchanged. This can be seen from the P99 read latency test result, which is shown in the following figure:
The architectural choices made ultimately shape how a system behaves in production. When performance does not depend on stable access patterns, cache tuning, or ideal workload assumptions, changes in usage no longer cause unpredictable behavior. As workloads evolve, as they always do, an Aerospike system remains consistent and predictable.
Tightly bounded tail latency across the stack
Aerospike's read and write latency profiles are closely mirrored, with sub-millisecond read latency and under 2ms write latency at P99. You can see this by comparing the write latency of the same uniform, low-cache-hit 6TB test shown above.
Even at P999, Aerospike's read latency stayed below 6ms across all tests, with minimal jitter (peak-to-trough variability under 2ms).
Compare this to ScyllaDB's P999 read latency, which ranged from 18-205ms, with peak-to-trough variability reaching 142.75ms in the 6TB uniform distribution test. When you're building systems with deep dependency chains where a single user interaction triggers 20, 50, or 100 database calls, this difference between bounded and unbounded tail latency determines whether your application feels responsive or unpredictable.
True linear scalability that preserves performance
When we doubled infrastructure from 3TB to 6TB, Aerospike demonstrated near-perfect linear scalability: throughput doubled (from ~488K ops/s to ~974K ops/s under uniform distribution), while latency characteristics remained essentially unchanged. Peak-to-trough throughput variability remained under 10%, indicating stable, predictable behavior even under sustained load.
Additionally, Aerospike showed no performance degradation over the 60-minute measurement window, and the throughput drift was less than 0.05% between the first and last five minutes of testing. By contrast, ScyllaDB showed measurable throughput degradation over time, suggesting that sustained operation introduces behavioral changes that must be managed operationally.
Resource efficiency that compounds over time
Perhaps most striking: Aerospike delivered 2.5-3× higher throughput than ScyllaDB while using approximately one-third fewer infrastructure resources. This isn't a benchmarking trick; it's a direct consequence of Aerospike's architectural efficiency and its ability to maintain high availability at replication factor 2, rather than requiring a replication factor of 3.
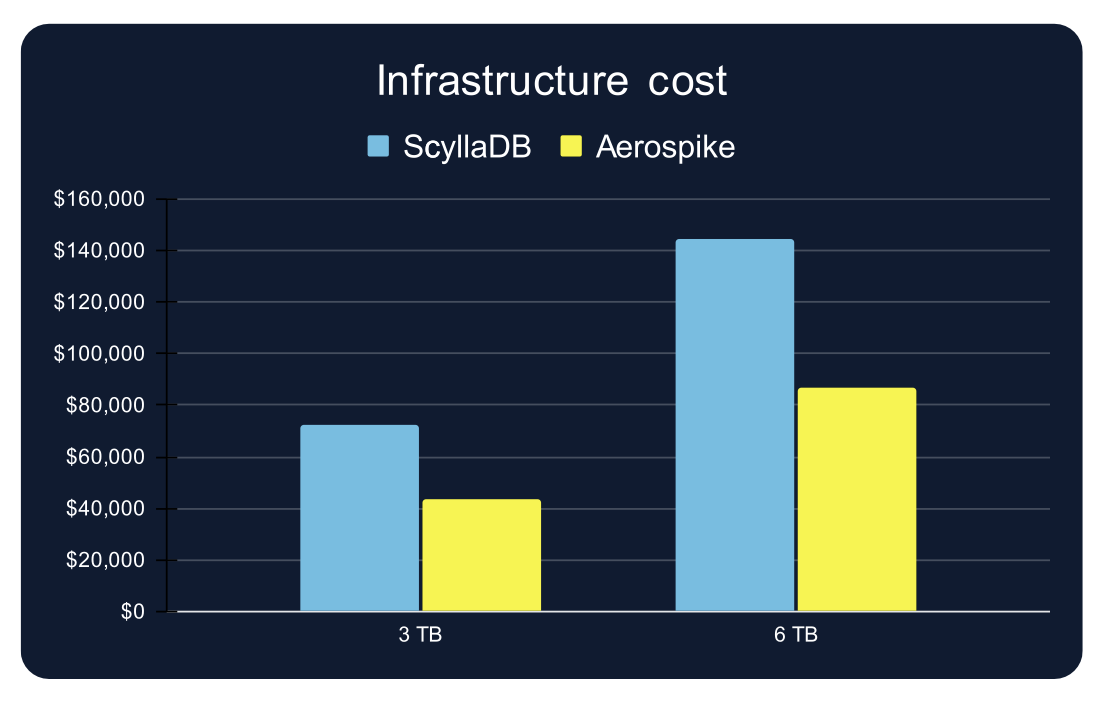
The cost implications are significant. For the 6TB dataset test, ScyllaDB required $144,330 in annual infrastructure spend, compared with Aerospike's $86,585, a 40% reduction. At a true production scale with multiple terabytes, this efficiency translates directly into a budget that can be invested elsewhere.
What this means for your data platform strategy
The benchmark results highlight a critical distinction: optimizing for ideal conditions versus designing for production reality.
Many databases can deliver impressive performance when:
Working sets fit comfortably in memory
Access patterns remain stable
Workloads are predictable and well-characterized
Systems operate with generous headroom below capacity
In reality, production systems are never truly stable. Traffic spikes occur unpredictably, product updates change access patterns, ML models introduce new query distributions, infrastructure experiences failures, maintenance is performed, and systems gradually age and accumulate issues.
The question isn't whether your database can perform well under ideal conditions. It's whether it maintains predictable behavior as those conditions inevitably change.
Predictable performance under real-world conditions
For teams building user-facing systems with high fan-out: If a single user interaction depends on many database calls, unbounded tail latency makes your overall response time unpredictable. Aerospike's tightly controlled P99 and P999 latency prevents tail amplification across deep dependency chains.
For teams operating at scale with evolving access patterns: If you can't predict tomorrow's cache hit rate because you can't predict tomorrow's user behavior, cache-dependent performance creates operational fragility. Aerospike's cache-independent latency eliminates this uncertainty.
For teams managing infrastructure costs at multi-TB scale: If you're overprovisioning to maintain acceptable P99 latency or adding cache layers to compensate for storage-tier slowness, you're paying for architectural limitations. Aerospike's efficiency enables higher utilization without performance cliffs.
For teams planning long-term platform evolution: If your database's performance degrades non-linearly as scale increases, you're locking in future replatforming risk. Aerospike's linear scaling characteristics preserve predictability as systems grow from terabytes to petabytes.
Explore the Aerospike vs. Scylla benchmark: Methodology and access
The complete Aerospike vs. ScyllaDB benchmark provides detailed methodology, full test results, and architectural explanations of the observed behavioral differences. Testing was conducted in partnership with McKnight Consulting Group using industry-standard YCSB benchmarks on AWS infrastructure.
Key aspects of the methodology:
Both systems were tested using recommended production configurations (Aerospike RF=2, ScyllaDB RF=3)
Identical 70% read / 30% write workload across all tests
Two access patterns tested: uniform distribution (low cache effectiveness) and hotspot distribution (~50% cache hit rate)
All metrics captured over 60-minute windows after a one-hour cache warm-up period
Testing at both 3TB and 6TB dataset sizes to evaluate scaling characteristics
Download the full benchmark report, which includes:
Detailed throughput analysis with time-series data
Comprehensive latency distributions at P50, P90, P99, and P999
Infrastructure cost breakdowns
Explanations of observed behavioral differences in architecture