Aerospike Database 8: Introducing distributed ACID transactions
How ACID transactions build on years of Aerospike’s strong consistency production experience.

We are proud to announce Aerospike Database 8.0, a version delivering a single, massive new feature - distributed ACID transactions. Using Aerospike’s distributed transactions, developers can build reliable high-performance applications for use cases such as payment systems, billing, social graphs, betting, and e-commerce. This feature is an evolution built on many years of experience. Aerospike’s distributed transactions are constructed on top of the solid foundation of strong consistency mode, launched in March 2018 with Aerospike Database 4, validated externally with Jepsen testing, and used heavily in production since.
A transaction is an encapsulation of multiple commands, isolated from other commands outside of the transaction, that executes as a unit upon commit. A transaction’s atomicity principle guarantees that all modifications happen together. Otherwise, all are rolled back on failure or if the transaction is aborted. While transactions have been a core component of relational databases for decades, ensuring these ACID characteristics in a distributed database is much more complex to implement.
We embarked on the long road to distributed transactions in April 2023, starting with the removal of single-bin namespaces in Database 6.4 to free metadata space needed for transactions. The subsequent three Aerospike Database 7 versions (7.0, 7.1, 7.2) constructed the ground floors through a storage format unification for all storage engines and the addition of cross-datacenter replication (XDR) shipping controls.
It’s normal to denormalize
At the dawn of the internet era, there were (almost exclusively) relational databases on which to build applications, a legacy of 1980s technology. The speed requirements for these new applications, coupled with the availability of larger and cheaper hard drive storage, fueled a data modeling trend of denormalization - reversing the dictate of relational modeling to minimize storage space.
Instead of removing duplicates and splitting data into separate tables JOINed together by queries, data was denormalized (repeated) into loosely coupled standalone tables for faster primary-key access. Document databases later followed this same pattern. A late 90s/early 2000s arms race in dynamic random-access memory (DRAM) took place, with DIMMs getting faster, denser, and cheaper. It enabled the rise of in-memory NoSQL caches like Memcache and data stores like Redis, offering lower latency single-object access through a key-value data model. Eventually, DRAM improvements hit a physical limitation and stopped. A crop of NoSQL databases emerged, combining in-memory caching and storage, leveraging more capable hard drives.
Aerospike’s NoSQL difference
Since 2010, Aerospike has been selected by users for its combination of high performance with low hardware cost. Aerospike benefitted from increasingly faster, denser, and cheaper solid-state flash drive (SSD) technology to provide low latency and high throughput data storage without requiring memory for caching. Data on SSD and a memory consumption of 64 bytes of primary-index metadata per-record (also known as Hybrid Memory Architecture) became the standard Aerospike deployment. Aerospike’s data access pattern uses a unique identifier (the digest). It quickly reaches the record through its in-memory primary-index metadata, directly to the right SSD device location for a single, low-latency contiguous read.
Distributed systems and consistency tradeoffs
Another inexorable trend in application development was the need for horizontal scaling. Since single servers could not support the necessary load of concurrent connections and the need for lower latency, all applications have evolved into distributed applications requiring distributed databases governed by the realities identified by Brewer’s CAP Theorem. Any distributed system can operate in one of two ways when a network partition inevitably happens and the cluster splits - available and partition-tolerant (AP) or consistent and partition-tolerant (CP).
NoSQL databases were originally designed as AP data stores, built to provide high availability and continue working as independent sub-clusters if a network partition happened. In such a situation, the same record/row/document/object might be read and also updated separately in each sub-cluster, leading to data inconsistency. When the network partition ends and the sub-clusters merge back to a single cluster, writes will be lost as no merge strategy can correctly resolve this divergence. Both last-write wins (LWW) and most-writes wins (MWW) are rough-grained conflict resolution policies that drop versions.
Eventual consistency approaches like conflict-free replicated data types (CRDTs) are more fine-grained, but in the event of a network partition, they still suffer from stale and dirty reads and, in some cases, lost writes. This behavior was exposed in a series of amusingly scathing Jepsen reports for NoSQL databases, including our very own AP-mode-only Aerospike 3 (again, we passed Jepsen with our 4.0 CP release, as mentioned above).
Aerospike and strong consistency
Aerospike Database 4 introduced the ability to select whether a namespace runs in a high-availability AP mode or a high-performance CP mode. We refer to this option as strong consistency (SC) due to the fact that Aerospike provides sequential consistency and linearizable reads, the highest single-object consistency model guarantees. A namespace configured to SC mode can serve applications that require these guarantees for use cases that cannot tolerate lost writes, dirty reads, and other unpleasant side effects of an AP NoSQL data store during network partitions. These include payment systems, telecom software, and social graphs. For example, users trust that their party invite will only reach its intended audience and not someone they unfriended, whilst two availability zones (AZs) of the database cluster temporarily couldn’t reach each other (leading to two confidently ignorant “I am the database” AP subclusters). In this scenario, a lost write results in an unacceptable user experience. Because Aerospike provides the highest-performing CP mode option, it has been powering such applications in production for close to seven years.
But objects have relationships (making transactions necessary)
While Aerospike pre-8.0 has been great at satisfying the requirements of internet applications (supporting a high number of concurrent users, providing consistently low latency, running with the highest uptime, all at the lowest hardware cost), limiting SC mode to single-record and batched commands left something to be desired. The denormalization approach works well in a system where objects are independent of each other, such as the user profile stores used by adtech and e-commerce. All the (typically anonymized) information about the user is stored in a single record, accessed by that record’s unique identifier. But, in many applications, objects actually do have relationships between them. Examples of this include bidirectional edges in a social graph, an instantaneous payment transfer between two users, or a product-to-shopping-cart relationship where inventory is tightly constrained. In these cases, establishing and updating the relationship between objects requires a transaction affecting more than one record.
Developers shouldn’t have to roll their own transactions
The absence of native transaction functionality in their distributed database of choice can force developers to implement workarounds to support multi-object transactional behavior. One approach takes the form of cooperative locking schemes that are hard to implement correctly while avoiding deadlock situations, and which fail if other tenant applications don’t obey the rules of the road. Think of a railroad crossing sign: it depends on the cooperation (and sanity) of drivers. Likewise, the consequence of miscooperation can be similarly dire for data commonly shared by multiple applications.
Another approach developers tend to be forced to employ is to create an external transaction manager - used by convention by all applications. Implementing a transaction manager correctly (and without serious bugs) is hard to do, and it often suffers from higher latency and constrained throughput as applications bottleneck on shared resources.
In working on a native distributed transaction capability for Aerospike, we set a goal of correctly providing strict serializability for multi-record updates at the best possible performance. This out-of-the-box capability enables developers to focus on writing their own applications and simplify their tech stack while trusting Aerospike Database to handle all data retrieval and manipulation logic for the application. No workarounds and no external transaction managers needed.
Measuring Aerospike transactions (Chinook is a breeze!)
Luis Rocha’s Chinook (lerocha/chinook-database) is a sample database useful for demos and testing. It includes real data representing a digital media store with tables for artists, albums, tracks, customers, and invoices.
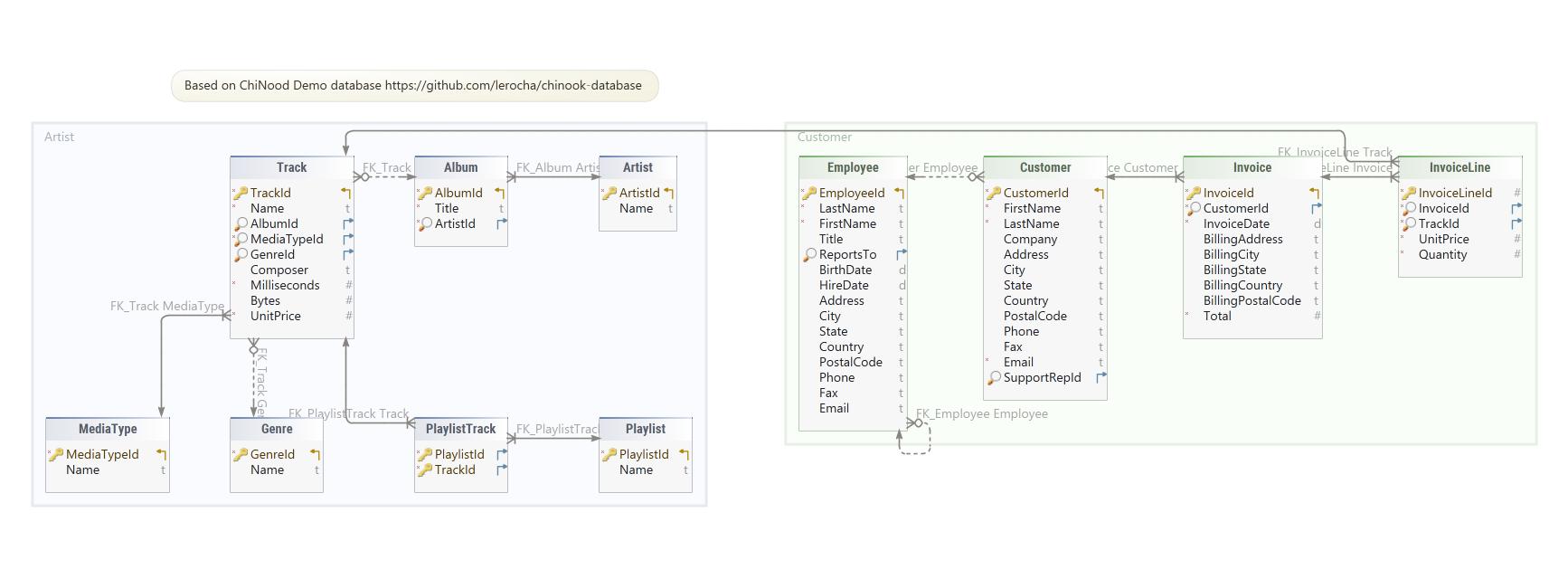
Our test application loaded Chinook records into sets “Customer” and “CustInvsDoc,” with invoices as an embedded Map in “CustInvsDoc.” Using LINQPad to browse these records, we can see the relationship between them:
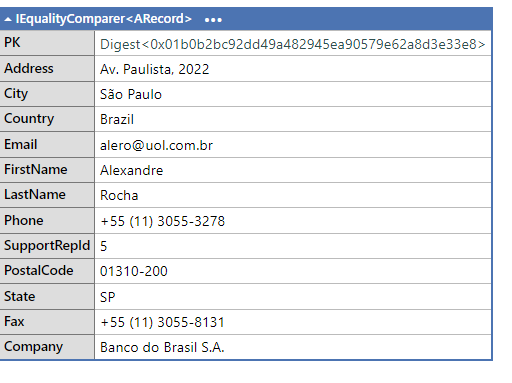
CustInvsDoc:
The test application ran two workload types:
Insert Only (CustCustInvsDocInsert): Inserts records into both Customer and CustInvsDoc sets.
Read-update (CustReadCustInvsDocUpdate). Reads an existing customer record from the Customer set and updates an Invoice reference for that customer record within the CustInvsDoc set.
In both workloads, all records are directly accessed by their keys.
Distributed transaction overhead
Distributed transactions in Aerospike have the following overhead (as described in the FAQ) as we are no longer dealing with single records:
One extra write creates a monitor record to keep track of any records modified by the transaction for its duration.
per-write command – an extra write to add the modified record’s digest to the monitor record, and one extra write when the provisional record is committed, similar to a record touch.
per-read command – one extra verify, which is lighter than a read as it checks the record’s generation without reading bins off the storage device
One monitor record write to commit the transaction, and one durable delete to remove the monitor record when the commit is done.
Testing results
We compared the same units of work executed within a transaction (“TXN” in the chart below) versus the same single-record commands not encapsulated in a transaction (“SRT” in the chart below) encapsulating the read and write commands. We plotted the ratio of their runtime as seen below where 1.00 is no dropoff for a transaction:
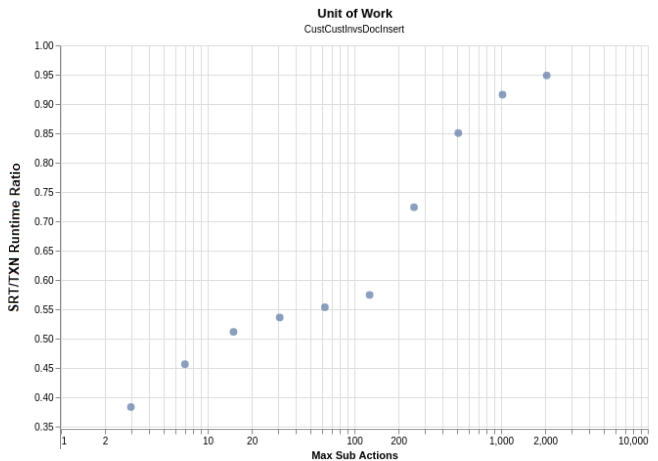
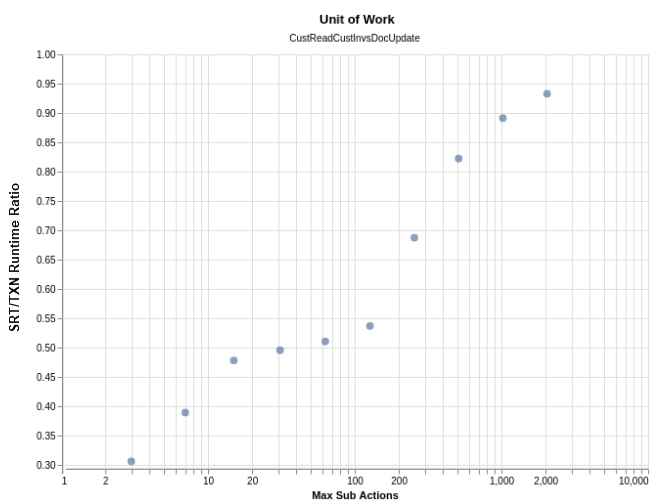
The results are in line with transaction overhead, with smaller transactions exhibiting the biggest latency gap between the same unit of work executed independently versus when it was wrapped in a transaction. In larger transactions, the overhead is amortized so that overall latencies are less affected.
The conclusion from running various tests is that it is okay to normalize data when the overhead is understood. Transactions perform well when used judiciously together with single-record read and write workloads.
You should familiarize yourself with the best practices for using transactions.
Try Aerospike Database 8
Developers can get started quickly with AeroLab. Alternatively, you can download Aerospike Enterprise Edition (EE) and run it in a single-node evaluation or get started with a 60-day multi-node trial.
You should read Tim Faulkes’ Aerospike 8 adds distributed ACID transactions for developers before digging further into our documentation. We are excited to deliver transaction management API compatibility in our Spring Data Aerospike 5.0.0 release. Read Andrey Grosland’s blog posts about new features in Spring Data Aerospike, updates and migration guide.
Consult the platform compatibility page and the minimum usable client versions table. For more details, read the Database 8.0 release notes.
Keep reading

Dec 27, 2024
What’s next for AI and data platforms? Predictions for 2025

Apr 16, 2026
Aerospike Database 8 named NoSQL Solution of the Year at the 2026 Data Breakthrough Awards

Apr 16, 2026
Introducing Aerospike 8.1.2: Making nested data queries fast and easy to write

Apr 14, 2026
Why tail latency dominates user experience in AI systems