Building modern fraud defense: A maturity model for real-time, AI-powered decisioning
Discover a five-stage fraud detection maturity model that shows how organizations advance from rule-based systems to real-time AI decisioning. Learn how real-time features, graph analytics, and high-speed infrastructure reduce losses, improve accuracy, and support large-scale fraud defense.
Matt Sarrel Published December 2, 2025 Read time 9 min read
As organized networks adopt artificial intelligence (AI) and automation, static rules and delayed detection no longer suffice. This blog outlines a fraud maturity model Aerospike has observed across many customers, showing how fraud detection evolves from rule-based systems to real-time, relationship-aware AI with infrastructure built for millisecond-scale decisioning.
Reaching a mature, best-in-class fraud defense posture requires infrastructure built for speed, scale, and reliability. Aerospike enables this foundation, powering leaders such as PayPal, Barclays, and LexisNexis to process millions of transactions per second, detect complex fraud patterns in real time, and reduce infrastructure costs dramatically.
The evolving landscape of fraud and the imperative for real-time, AI-powered defense
The digital economy is under siege. According to a joint report from the Global Anti-Scam Alliance and Feedzai, fraud now drains trillions of dollars from the global economy annually. Today’s fraudsters are sophisticated, globally organized criminals leveraging advanced technology, such as Fraud-as-a-Service (criminal platforms that sell or rent the tools, services, and infrastructure required to conduct fraudulent activities), AI-driven bots, and automation to drive and scale their attacks. The threat has moved beyond simple transactional anomalies to complex, relationship-based fraud with networks of synthetic identities and international money mules. These hidden relationships within data graphs are the new frontier of financial crime.
Below, we explore a maturity model for fraud detection, outlining the architectural evolution from basic rule-based systems to advanced, real-time AI platforms.
Webinar: Powering real-time personalization with recommendation engines
Want to turn real-time data into real-time conversions? Watch our webinar, Powering real-time personalization with recommendation engines, and discover how teams at Wayfair, PayPal, and Myntra are using live behavioral signals and machine learning to deliver sub-millisecond personalized experiences, boosting engagement, loyalty, and revenue across every touchpoint. Learn how to scale personalization with lightning-fast performance.
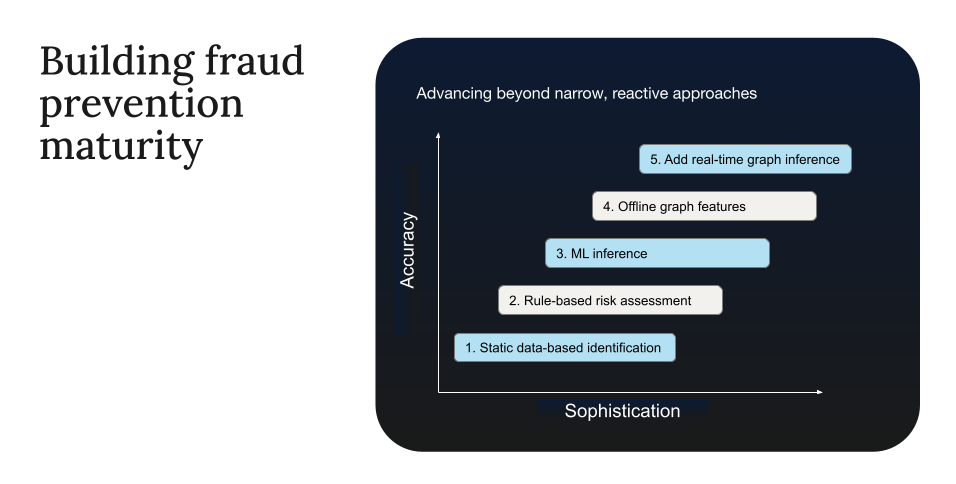
Fraud detection maturity: From static rules to real-time AI
The evolution of fraud detection is a story of increasing speed, sophistication, and contextual fraud awareness, advancing from reactive analysis to proactive, real-time intervention. We chart this progression across five key stages, and each delivers a significant capability leap to keep pace with continuously escalating threats.
Stage 1: Static, after-the-fact identification
The earliest forms of fraud detection were entirely reactive. Financial institutions would analyze historical, batched data to identify fraudulent activity afterit had already occurred. The process was slow, relying on traditional data warehouses and SQL to sift through data that could be hours or even days old. Unfortunately, this high-latency process meant that by the time the system flagged the fraudulent transaction, the financial damage had already been done and the perpetrators were gone. This was a post-mortem to understand where the transaction went wrong, not a preventative measure.
The first attempts at proactive fraud detection were rule-based systems. These systems operate using simple “if/then” logic to flag transactions that violate predefined conditions, such as transactions exceeding a certain threshold or originating from an unusual location. Although this stage represented a significant improvement over static analysis, this approach has several significant limitations.
Human analysts must manually create and maintain vast libraries of rules, often numbering in the thousands. This process is labor-intensive, slow, and struggles to adapt to the dynamic, automated, and evolving tactics of modern fraudsters. The rule sets are inherently fragile and rigid; they often treat data points in isolation, failing to pinpoint non-obvious correlations between variables. Most of these systems gradually grow until they can no longer be maintained; there are only so many rules that can run within a given period of time. In addition, these systems generate a massive number of false positives, flagging legitimate customers/transactions and creating friction, while still being unable to detect novel or complex fraud patterns.
Graph database buyer's guide
With the continuing growth of cloud computing, distributed databases, and now AI/ML, the role of graph databases has evolved to include more operational workloads. This guide will help guide you to make an informed decision about which approach to graph databases best suits your requirements.
Stage 3: Machine learning inference for probabilistic fraud risk assessment
The limitations of static rule-based systems led to the adoption of machine learning (ML) in fraud detection systems, marking a paradigm shift from deterministic to probabilistic logic. Instead of relying on manually coded rules, teams train ML models on historical data to identify the subtle patterns and hidden correlations typical of today’s fraud.
Implementing ML inference for probabilistic fraud risk assessment is a fundamental leap forward in an organization’s fraud detection maturity. ML models can simultaneously analyze hundreds or even thousands of features from diverse data sources. These features provide much more than just simple transaction details, including user behavior (e.g., clicks, session duration), device and network information (e.g., IP address, device ID), historical aggregates (e.g., transaction frequency, average spend), and geolocation.
This probabilistic approach improves accuracy and reduces false positives, but it still analyzes transactions individually. Without a relationship context, even sophisticated models can miss organized fraud networks.
Stage 4: Batch-generated graph features enhance machine learning accuracy and predictive power
The first operational step involves applying graph analytics to historical, batched data to generate predictive features. The system is still limited by the fact that these features are only updated in batches, creating a vulnerability window. This process begins by transforming disparate data points into a cohesive graph structure, where key entities, such as accounts, individual users, devices used for transactions, and IP addresses, are represented as nodes. The interactions and connections between these entities, such as shared devices, co-occurring transactions, or common IP addresses, are referred to as edges.
Once teams construct the graph, data scientists can deploy a range of sophisticated graph algorithms to uncover hidden patterns indicative of fraudulent activity. Community detection algorithms, for instance, identify tightly knit groups of nodes that might represent organized fraud rings or mule networks (groups of individuals who move illicit funds through various accounts).
Centrality algorithms help pinpoint the most influential or critical nodes within these networks, which could represent the masterminds of a fraud operation or central points of coordination. By analyzing the connections and attributes, analysts can detect synthetic identities (fraudulent identities created using a combination of real and fabricated information), which often exhibit unusual network structures or connections to multiple, otherwise unrelated, entities.
Data scientists transform these insights into powerful predictive features. For example, a user's "proximity to a known fraudster" (measured by the shortest path in the graph) and the "risk score of their community" (derived from the collective behavior or attributes of their connected nodes) become inputs. Teams feed these graph-derived features into ML models, significantly enhancing their accuracy and predictive power.
However, a critical limitation at this stage is the reliance on batch training. Pipelines generate and update features only a few times per day, or sometimes even less frequently. This inherent delay creates a window of opportunity for fast-acting criminals, who can exploit the time lag between fraudulent activity and the model's updated understanding of the threat landscape. While this approach marks a significant advancement over a traditional, non-graph-based strategy, the static nature of batch-generated features means that real-time, rapidly evolving fraud schemes may not be detected promptly, allowing criminals to cause substantial damage before the system adapts. The transition to more real-time graph analytics is the natural next step in further maturing fraud detection capabilities.
Stage 5: Real-time graph inference for adaptive, millisecond decisioning
State-of-the-art systems reach this stage by moving from batch-generated features to real-time graph inference and traversal within the decision window. This enables adaptive, contextual detection that prevents losses before they occur by analyzing relationships with millisecond latency. They capture and serve the freshest transactional, behavioral, and identity data with millisecond latency to ensure that each inference reflects the most current context. This advanced capability is critical given the dynamic and rapidly evolving nature of modern fraud.
For many mature systems, the final leap comes from graduating from batch-based graph analysis to real-time streaming graph inference. A real-time database with graph functionality is the critical enabler in this scenario. It empowers the inference engine to actively traverse and analyze these intricate relationships as they form.
This means that the system can instantly identify, for example, a newly opened account that shares a device with a known fraudster or trace funds as they move through an international chain of money mule accounts. The system makes end-to-end decisions in under a second, even at massive scale, and models continuously adapt to new signals without the delay of waiting for batch updates. The system prevents losses before they occur, significantly reduces false positives, minimizes customer friction, and delivers measurable business benefits through faster detection, better accuracy, and a resilient, cost-efficient infrastructure.
Hands-on workshop: Real-time fraud detection with graph databases
Learn how to design and implement a fraud detection system that actually scales. This hands-on workshop walks you through using graph databases to spot complex fraud patterns in real time. Watch now to gain practical skills you can put to work immediately.
The progression from static rules to real-time, graph-aware AI reflects an arms race with adversaries who exploit every vulnerability. Victory requires not only risk-scoring individual transactions, but also understanding the complex, dynamic web of relationships among devices, identities, accounts, and funds, all within the same decision window as the transaction.
Teams collapse detection, decisioning, and action into that window. Organizations that reach this state realize faster, more accurate outcomes and reduce false positives.
A graph layer for in-flight traversal (proximity, community risk, multi-hop paths)
An inference engine that supports strict sub-second service performance targets, champion/challenger testing, and policy-based routing
The business payoff will be significant. Organizations measurably reduce losses by interdicting new account abuse, account takeover, and money mule rings faster. They deliver a smoother customer experience with fewer unnecessary escalations requiring human intervention, higher approval rates for good users and transactions, and improved customer satisfaction. Operational efficiency improves as manual reviews decline and decisioning becomes more accurate. The system won’t just react faster; it will constrain fraudsters' time horizon to milliseconds.
To finish the climb to stage five, prioritize a pragmatic migration path.
Identify the top fraud scenarios by loss and friction, define the decision window performance target for each, and move the highest ROI features into the real-time store.
Introduce graph features and graph inference.
Instrument and measure everything and track KPIs such as fraud dollars lost per thousand transactions, approval rate, false-positive rate, human review rate, decision latency at p99, and infrastructure cost per decision.
To evaluate your fraud detection readiness, consider these questions:
Can your system serve features with millisecond latency at high concurrency?
Do you support recency logic, versioning, and reuse across workflows?
Can your infrastructure scale with user growth and usage spikes without driving up cost?
Are you confident in your system’s ability to act without clear user input?
Is slow feature retrieval eating into your inference window?
Aerospike provides the low latency, high-concurrency foundation for real-time features and graph-aware lookups at scale, so fraud detection models act with the freshest view without prohibitively increasing latency or cost.
Try Aerospike Graph
The developer-ready, highly scalable graph database.