How do you deliver real-time, personalized experiences across millions of users, under tight latency service level agreements (SLAs), at a global scale, while keeping costs under control?
That’s the challenge Adobe faces every day. Its real-time customer data platform (CDP) processes billions of profiles, handles tens of billions of writes per day, and serves millions of reads daily across a global edge network. It processes massive streams of behavioral data, creates unified customer profiles, and activates them for personalization in milliseconds. Every millisecond matters, and every dollar counts.
✅ Faster performance ✅ Fivefold increase in scale ✅ Reduced infrastructure costs by 89%
This post is based on a talk by Anuj Jain, Senior Engineering Manager at Adobe, delivered at the Real-Time Data Summit.
What personalization at the edge demands
Adobe’s personalization engine powers dynamic web content, in-app product recommendations, and real-time audience segmentation. These aren’t batch jobs—they happen live, in milliseconds, with users expecting immediate, tailored experiences.
Adobe’s real-time CDP ingests behavioral data from known and anonymous users across every touchpoint, creates identities on the fly, and activates segments for marketing, analytics, and experience delivery.
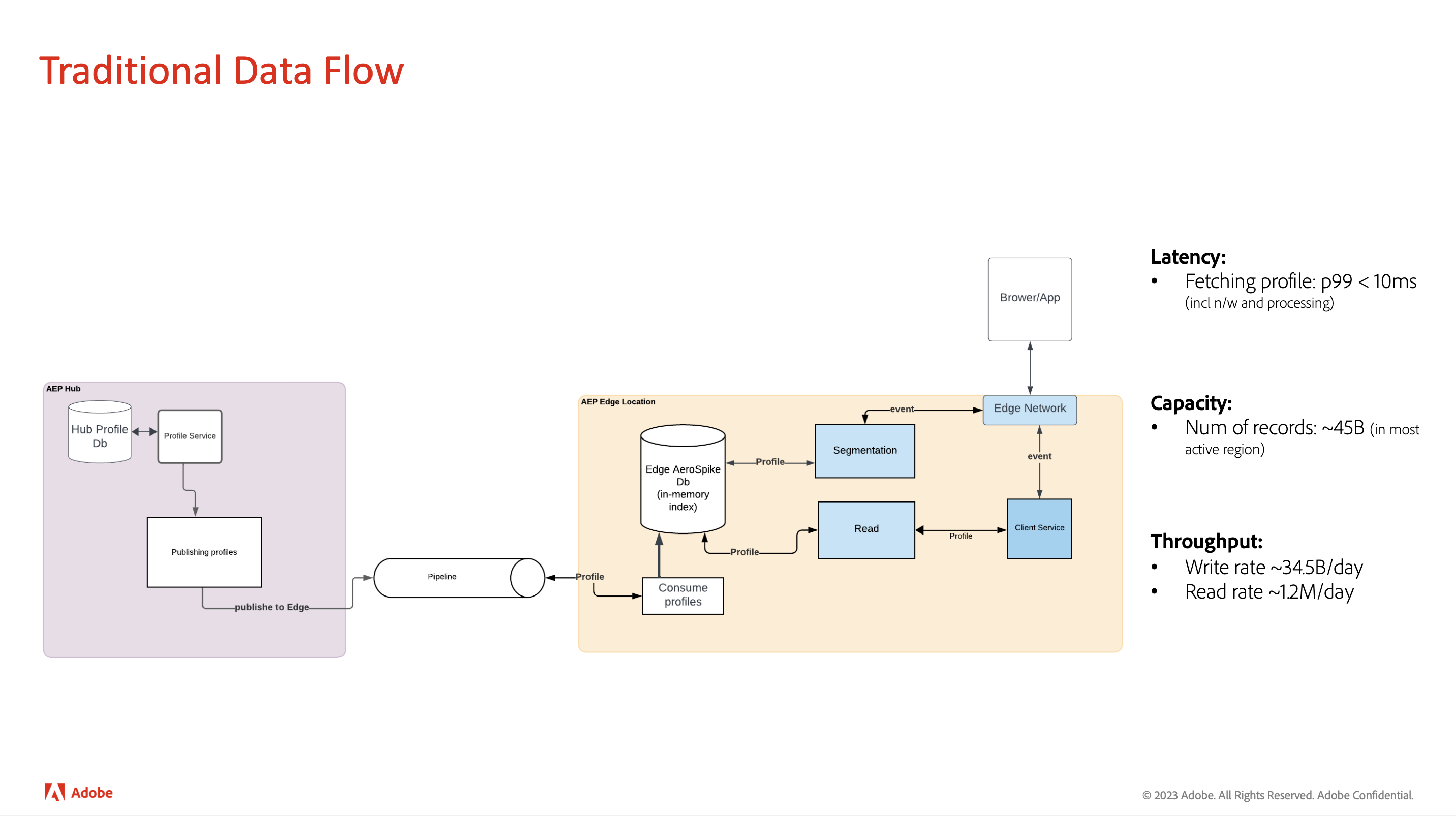
One example is on-site and in-app personalization, triggered by client software development kits (SDKs) through Adobe’s Edge Network. “From there, they are sent to the different services on the Adobe Edge, to read the profiles, perform segmentation, and carry out other personalization activities, ultimately delivering a personalized experience to the visitor on the web page,” Jain said. “Additionally, all these incoming events are also collected in the Adobe real-time CDP for further processing, detailed analysis, and analytics.”
Running operational workloads with Aerospike at petabyte scale in the cloud on 20 nodes
Discover how to achieve sub-millisecond performance at petabyte scale while cutting costs by up to 80%. Download the Aerospike white paper developed with Intel and AWS to power real-time applications with unmatched efficiency and reliability.
To meet Adobe’s real-time SLA targets, performance wasn’t optional—it was foundational. Every request had to fetch and process a user profile, run segmentation, and complete a round-trip to the edge.
“We need to support an extremely tight latency … in which we have to look up the… profile, we have to process the profile, we have to do some network transfers… we have to constantly maintain 99% of the time, in less than 10 milliseconds,” said Jain.
The problem with all indexes in-memory at hyperscale
Adobe’s first solution was to run an Aerospike cluster with full indexes in RAM, which is typical of its Hybrid Memory Architecture (which simultaneously persists data on SSD). It worked—until scale caught up. “We had to keep all indexes in memory. For 45 billion profiles, it was getting too expensive,” Jain said. “The cost was constantly growing month over month.”
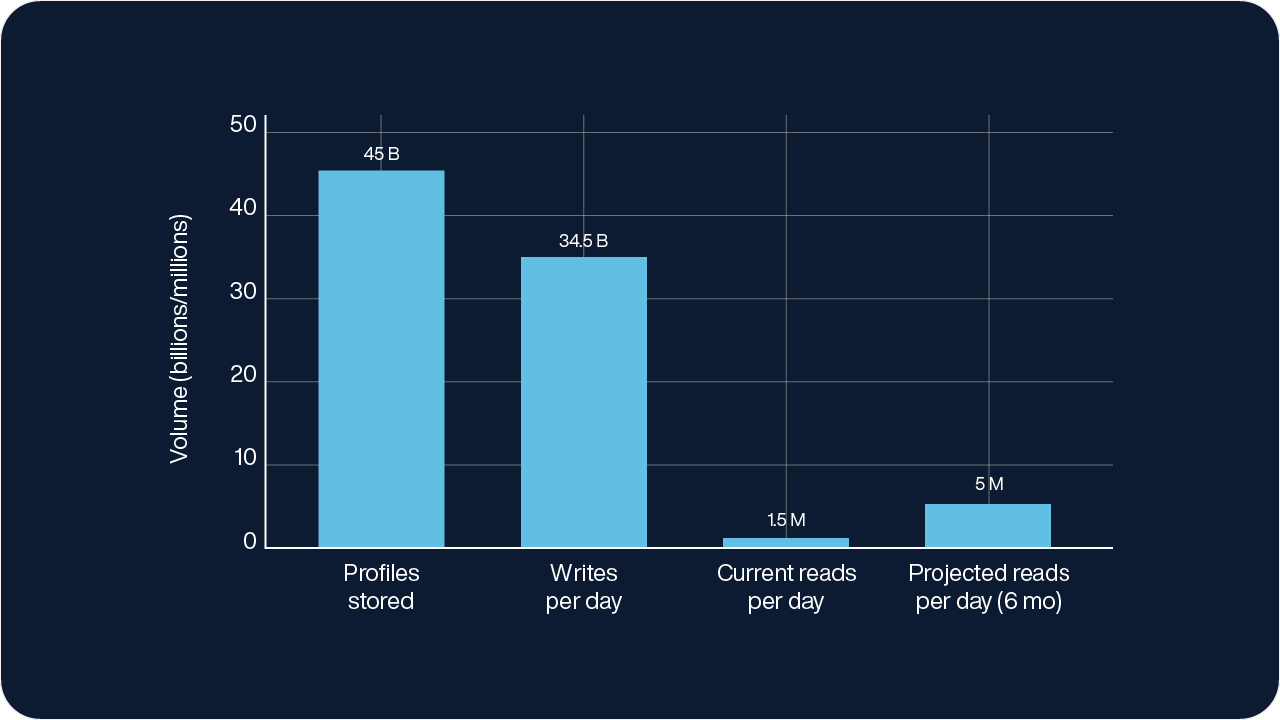
One of Adobe’s busiest edge regions currently holds around 45 billion profiles, and demand is expected to grow significantly in the year ahead. Scaling an architecture with indexes in-memory to meet that demand would mean more RAM, more nodes, and significantly higher cloud costs. It became clear that a different approach was needed.
Most real-time reads came from a relatively small subset of active profiles. The long tail of less frequently accessed data didn’t need to have its indexes live in memory. Adobe began exploring a new model, something more like CPU caching, with a small, ultra-fast hybrid memory L1 tier in front of a larger, SSD-only L2. That insight became the foundation for Adobe’s tiered Aerospike architecture strategy.
The breakthrough: Two-tier Aerospike architecture
To break the cycle of spiraling memory costs and unpredictable scale, Adobe engineers took a cue from a well-known performance paradigm: CPU cache design. Adobe applied that architectural logic to its data layer and built a two-tier Aerospike architecture:
L1 (Front tier): A small, ultra-fast Aerospike cluster holding the most frequently retrieved user profiles (i.e., Aerospike’s Hybrid Memory Architecture) with only indexes in memory.
L2 (Back tier): A much larger, all-flash SSD-backed Aerospike cluster storing the full dataset with indexes—billions of profiles and all writes from the central pipeline.
“Just like CPU caches, we use a smaller, faster L1 in front of a larger L2. L1 is (indexes) in-memory and super fast. L2 is on SSD and cost-effective,” said Jain. The design struck a balance between low-latency reads and large-scale durability. L1 ensures fast access to frequently used profiles, while L2 handles the volume and persistence, without breaking the budget.
To make this work, Adobe developed custom tiering logic:
Reads are routed through L1 when available
Async updates keep L1 fresh without excessive overhead
Write duplication is minimized, keeping bandwidth low between tiers
Fallback reads from L2 can promote data back into L1 for subsequent requests
The result is an intelligent, scalable system that delivers real-time performance for active data, without paying memory prices for the entire dataset.
How L1 and L2 work in practice
Adobe’s two-tier Aerospike deployment is tightly tuned for real-time scale. Reads are routed toL1first for extremely fast access. If a profile isn’t found, the system fetches it from L2 and can promote it into L1. Writes go directly to L2, keeping memory usage low and ensuring persistence.
What makes this work is a custom syncing layer between tiers. “You can’t let L1 go stale. We built custom algorithms to make sure every profile is always fresh,” said Jain. “Even under high write pressure, our design guarantees consistency without compromising performance.” This design eliminates the need for oversized memory clusters while maintaining data freshness and performance guarantees.
Tier responsibilities and characteristics
Tier
Throughput
Index
Storage
Role
L1
Moderate
RAM
SSD (Small)
Active profile reads
L2
High
SSD
SSD (Large)
All writes + long-tail access
Jain elaborates a bit further on how his team managed to keep profiles fresh under high write pressure. “We had to come up with specialized algorithms of our own to read profiles, to write profiles, and to make sure that they are always kept in sync, even though the throughput that this smaller database can support is much smaller... Any write load that is coming from the hub, which could be as high as half a million records per second, has to make sure that if that profile is present in the smaller database, it gets updated there.”
In other words, L1 stays lean and fast, while L2 carries the full workload at scale. Together, they allow Adobe to meet tight SLAs, reduce infrastructure costs, and keep every profile up to date.
A unified data platform for buy-side precision and sell-side scale
This white paper breaks down how Aerospike brings together document, graph, and vector search in one real-time database—so AdTech platforms can match users to the right ads, creatives, and products in under 100ms, even at global scale.
Edge cluster capacity increased 5x, allowing the same infrastructure to handle significantly more traffic
Infrastructure costs dropped 89%, thanks to the shift from RAM-heavy nodes to SSD-backed storage
Cache miss rates decreased, as smarter caching kept active profiles in L1 longer, improving user experience and cache efficiency
Latency remained consistently low, even improving slightly from before, reinforcing Adobe’s ability to meet its SLA.
This was more than a cost optimization. It was a structural shift that made Adobe’s personalization engine faster, leaner, and more future-proof, without sacrificing scale or freshness.
Why Aerospike was the right fit
Adobe needed performance at scale, without the hardware bloat. With Aerospike, it built a real-time lookup system on standard cloud infrastructure, not custom hardware or overprovisioned memory clusters.
Aerospike’s tiered architecture delivered:
An in-memory-to-SSD storage model that provides predictable, low latency reads
An all-flash storage engine to efficiently store billions of indexes on SSD with data
The ability to scale linearly without non-linear cost
“We didn’t use any special hardware. It’s all public cloud. Aerospike gave us the control we needed,” said Jain. “I think this hybrid system that we developed…beats most of the real-time databases for real-time marketing use cases.” Aerospike wasn’t just fast—it was efficient, scalable, and ready for real-world demands. And for Adobe, that made all the difference.
What’s next
Adobe’s roadmap builds on the success of its tiered storage architecture. The team is preparing for continued growth without a corresponding spike in infrastructure costs.
“We will have about 3x the capacity requirement and traffic requirement,” said Jain. “This will continue to grow linearly because…when we did the switch, our clusters were at capacity. So any new thing that we add, we will have to increase cluster sizes. So one year from now, the savings that we will have will be much, much larger. Our new infrastructure is going to cost about $20K per month, whereas the older infra would have us spend about $350K. So that’s going to be the ratio of the savings.”
Future efforts include more intelligent tiering, deeper regional clusters, and continued investment in delivering real-time personalization at scale.
Try Aerospike: Community or Enterprise Edition
Aerospike offers two editions to fit your needs:
Community Edition (CE)
A free, open-source version of Aerospike Server with the same high-performance core and developer API as our Enterprise Edition. No sign-up required.
Enterprise & Standard Editions
Advanced features, security, and enterprise-grade support for mission-critical applications. Available as a package for various Linux distributions. Registration required.